 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Risk Assessments for Offensive Cybersecurity Agents
May 23, 2025



Foundation models are increasingly becoming better autonomous programmers, raising the prospect that they could also automate dangerous offensive cyber-operations. Current frontier model audits probe the cybersecurity risks of such agents, but most fail to account for the degrees of freedom available to adversaries in the real world. In particular, with strong verifiers and financial incentives, agents for offensive cybersecurity are amenable to iterative improvement by would-be adversaries. We argue that assessments should take into account an expanded threat model in the context of cybersecurity, emphasizing the varying degrees of freedom that an adversary may possess in stateful and non-stateful environments within a fixed compute budget. We show that even with a relatively small compute budget (8 H100 GPU Hours in our study), adversaries can improve an agent's cybersecurity capability on InterCode CTF by more than 40\% relative to the baseline -- without any external assistance. These results highlight the need to evaluate agents' cybersecurity risk in a dynamic manner, painting a more representative picture of risk.
AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks
Mar 02, 2024



Large language models (LLMs) have demonstrated impressive results on natural language tasks, and security researchers are beginning to employ them in both offensive and defensive systems. In cyber-security, there have been multiple research efforts that utilize LLMs focusing on the pre-breach stage of attacks like phishing and malware generation. However, so far there lacks a comprehensive study regarding whether LLM-based systems can be leveraged to simulate the post-breach stage of attacks that are typically human-operated, or "hands-on-keyboard" attacks, under various attack techniques and environments. As LLMs inevitably advance, they may be able to automate both the pre- and post-breach attack stages. This shift may transform organizational attacks from rare, expert-led events to frequent, automated operations requiring no expertise and executed at automation speed and scale. This risks fundamentally changing global computer security and correspondingly causing substantial economic impacts, and a goal of this work is to better understand these risks now so we can better prepare for these inevitable ever-more-capable LLMs on the horizon. On the immediate impact side, this research serves three purposes. First, an automated LLM-based, post-breach exploitation framework can help analysts quickly test and continually improve their organization's network security posture against previously unseen attacks. Second, an LLM-based penetration test system can extend the effectiveness of red teams with a limited number of human analysts. Finally, this research can help defensive systems and teams learn to detect novel attack behaviors preemptively before their use in the wild....
Maestro: A Gamified Platform for Teaching AI Robustness
Jun 14, 2023Although the prevention of AI vulnerabilities is critical to preserve the safety and privacy of users and businesses, educational tools for robust AI are still underdeveloped worldwide. We present the design, implementation, and assessment of Maestro. Maestro is an effective open-source game-based platform that contributes to the advancement of robust AI education. Maestro provides goal-based scenarios where college students are exposed to challenging life-inspired assignments in a competitive programming environment. We assessed Maestro's influence on students' engagement, motivation, and learning success in robust AI. This work also provides insights into the design features of online learning tools that promote active learning opportunities in the robust AI domain. We analyzed the reflection responses (measured with Likert scales) of 147 undergraduate students using Maestro in two quarterly college courses in AI. According to the results, students who felt the acquisition of new skills in robust AI tended to appreciate highly Maestro and scored highly on material consolidation, curiosity, and mastery in robust AI. Moreover, the leaderboard, our key gamification element in Maestro, has effectively contributed to students' engagement and learning. Results also indicate that Maestro can be effectively adapted to any course length and depth without losing its educational quality.
Attacking Point Cloud Segmentation with Color-only Perturbation
Dec 18, 2021
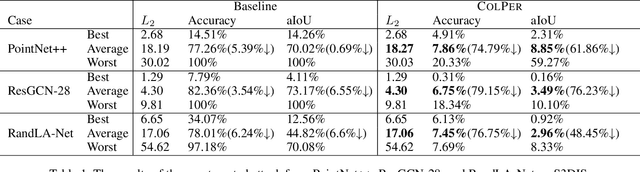


Recent research efforts on 3D point-cloud semantic segmentation have achieved outstanding performance by adopting deep CNN (convolutional neural networks) and GCN (graph convolutional networks). However, the robustness of these complex models has not been systematically analyzed. Given that semantic segmentation has been applied in many safety-critical applications (e.g., autonomous driving, geological sensing), it is important to fill this knowledge gap, in particular, how these models are affected under adversarial samples. While adversarial attacks against point cloud have been studied, we found all of them were targeting single-object recognition, and the perturbation is done on the point coordinates. We argue that the coordinate-based perturbation is unlikely to realize under the physical-world constraints. Hence, we propose a new color-only perturbation method named COLPER, and tailor it to semantic segmentation. By evaluating COLPER on an indoor dataset (S3DIS) and an outdoor dataset (Semantic3D) against three point cloud segmentation models (PointNet++, DeepGCNs, and RandLA-Net), we found color-only perturbation is sufficient to significantly drop the segmentation accuracy and aIoU, under both targeted and non-targeted attack settings.
An Empirical and Comparative Analysis of Data Valuation with Scalable Algorithms
Nov 17, 2019

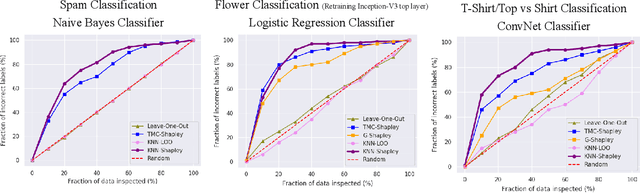

This paper focuses on valuating training data for supervised learning tasks and studies the Shapley value, a data value notion originated in cooperative game theory. The Shapley value defines a unique value distribution scheme that satisfies a set of appealing properties desired by a data value notion. However, the Shapley value requires exponential complexity to calculate exactly. Existing approximation algorithms, although achieving great improvement over the exact algorithm, relies on retraining models for multiple times, thus remaining limited when applied to larger-scale learning tasks and real-world datasets. In this work, we develop a simple and efficient heuristic for data valuation based on the Shapley value with complexity independent with the model size. The key idea is to approximate the model via a $K$-nearest neighbor ($K$NN) classifier, which has a locality structure that can lead to efficient Shapley value calculation. We evaluate the utility of the values produced by the $K$NN proxies in various settings, including label noise correction, watermark detection, data summarization, active data acquisition, and domain adaption. Extensive experiments demonstrate that our algorithm achieves at least comparable utility to the values produced by existing algorithms while significant efficiency improvement. Moreover, we theoretically analyze the Shapley value and justify its advantage over the leave-one-out error as a data value measure.
Beyond Adversarial Training: Min-Max Optimization in Adversarial Attack and Defense
Jun 09, 2019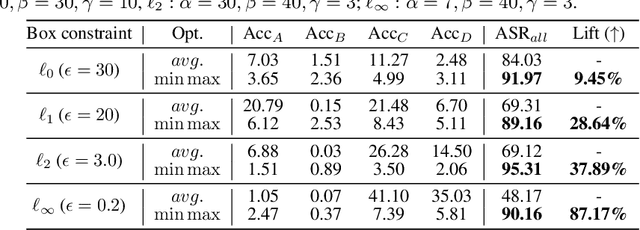
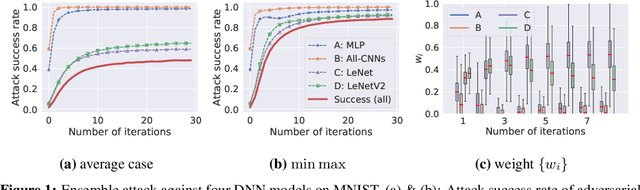
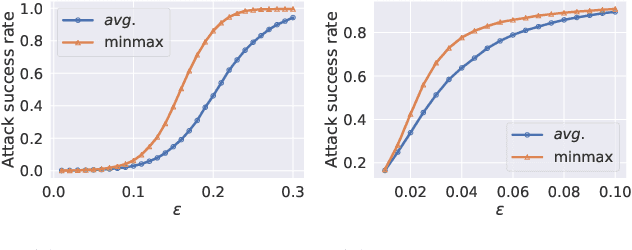

The worst-case training principle that minimizes the maximal adversarial loss, also known as adversarial training (AT), has shown to be a state-of-the-art approach for enhancing adversarial robustness against norm-ball bounded input perturbations. Nonetheless, min-max optimization beyond the purpose of AT has not been rigorously explored in the research of adversarial attack and defense. In particular, given a set of risk sources (domains), minimizing the maximal loss induced from the domain set can be reformulated as a general min-max problem that is different from AT, since the maximization is taken over the probability simplex of the domain set. Examples of this general formulation include attacking model ensembles, devising universal perturbation to input samples or data transformations, and generalized AT over multiple norm-ball threat models. We show that these problems can be solved under a unified and theoretically principled min-max optimization framework. Our proposed approach leads to substantial performance improvement over the uniform averaging strategy in four different tasks. Moreover, we show how the self-adjusted weighting factors of the probability simplex from our proposed algorithms can be used to explain the importance of different attack and defense models.