 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaternal and Fetal Health Status Assessment by Using Machine Learning on Optical 3D Body Scans
Apr 08, 2025Monitoring maternal and fetal health during pregnancy is crucial for preventing adverse outcomes. While tests such as ultrasound scans offer high accuracy, they can be costly and inconvenient. Telehealth and more accessible body shape information provide pregnant women with a convenient way to monitor their health. This study explores the potential of 3D body scan data, captured during the 18-24 gestational weeks, to predict adverse pregnancy outcomes and estimate clinical parameters. We developed a novel algorithm with two parallel streams which are used for extract body shape features: one for supervised learning to extract sequential abdominal circumference information, and another for unsupervised learning to extract global shape descriptors, alongside a branch for demographic data. Our results indicate that 3D body shape can assist in predicting preterm labor, gestational diabetes mellitus (GDM), gestational hypertension (GH), and in estimating fetal weight. Compared to other machine learning models, our algorithm achieved the best performance, with prediction accuracies exceeding 88% and fetal weight estimation accuracy of 76.74% within a 10% error margin, outperforming conventional anthropometric methods by 22.22%.
Accelerating Neural Network Training: An Analysis of the AlgoPerf Competition
Feb 20, 2025



The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition's results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
Flex Attention: A Programming Model for Generating Optimized Attention Kernels
Dec 07, 2024Over the past 7 years, attention has become one of the most important primitives in deep learning. The primary approach to optimize attention is FlashAttention, which fuses the operation together, drastically improving both the runtime and the memory consumption. However, the importance of FlashAttention combined with its monolithic nature poses a problem for researchers aiming to try new attention variants -- a "software lottery". This problem is exacerbated by the difficulty of writing efficient fused attention kernels, resisting traditional compiler-based approaches. We introduce FlexAttention, a novel compiler-driven programming model that allows implementing the majority of attention variants in a few lines of idiomatic PyTorch code. We demonstrate that many existing attention variants (e.g. Alibi, Document Masking, PagedAttention, etc.) can be implemented via FlexAttention, and that we achieve competitive performance compared to these handwritten kernels. Finally, we demonstrate how FlexAttention allows for easy composition of attention variants, solving the combinatorial explosion of attention variants.
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022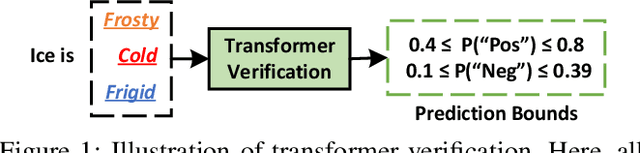

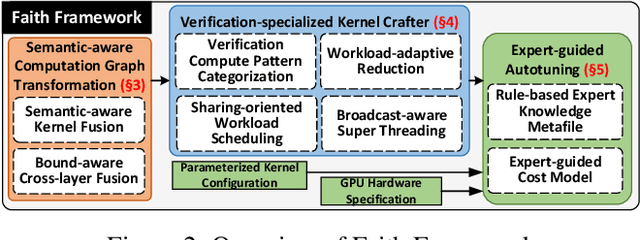
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Empowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Sep 14, 2022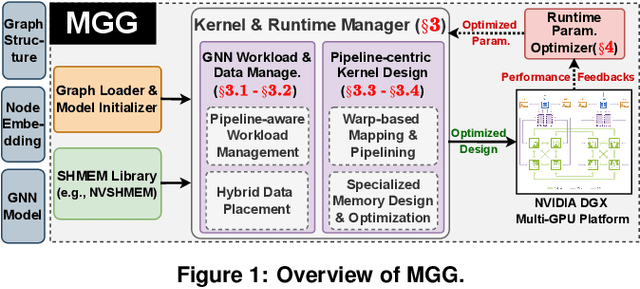

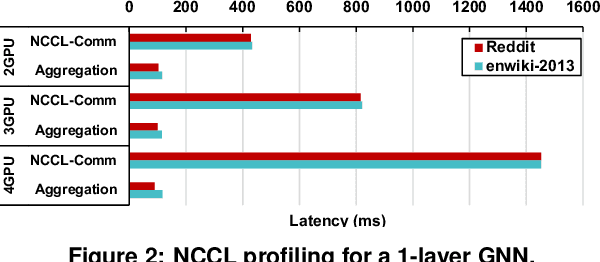

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.
Attacking Point Cloud Segmentation with Color-only Perturbation
Dec 18, 2021
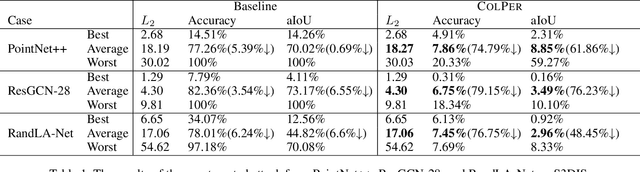


Recent research efforts on 3D point-cloud semantic segmentation have achieved outstanding performance by adopting deep CNN (convolutional neural networks) and GCN (graph convolutional networks). However, the robustness of these complex models has not been systematically analyzed. Given that semantic segmentation has been applied in many safety-critical applications (e.g., autonomous driving, geological sensing), it is important to fill this knowledge gap, in particular, how these models are affected under adversarial samples. While adversarial attacks against point cloud have been studied, we found all of them were targeting single-object recognition, and the perturbation is done on the point coordinates. We argue that the coordinate-based perturbation is unlikely to realize under the physical-world constraints. Hence, we propose a new color-only perturbation method named COLPER, and tailor it to semantic segmentation. By evaluating COLPER on an indoor dataset (S3DIS) and an outdoor dataset (Semantic3D) against three point cloud segmentation models (PointNet++, DeepGCNs, and RandLA-Net), we found color-only perturbation is sufficient to significantly drop the segmentation accuracy and aIoU, under both targeted and non-targeted attack settings.
TC-GNN: Accelerating Sparse Graph Neural Network Computation Via Dense Tensor Core on GPUs
Dec 03, 2021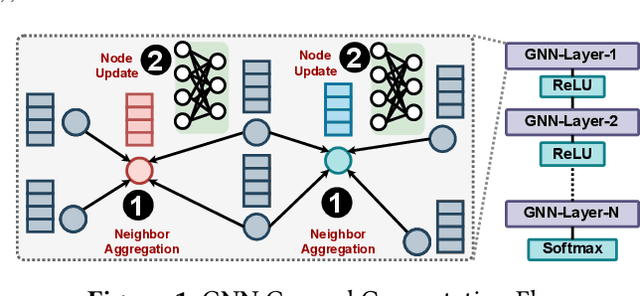
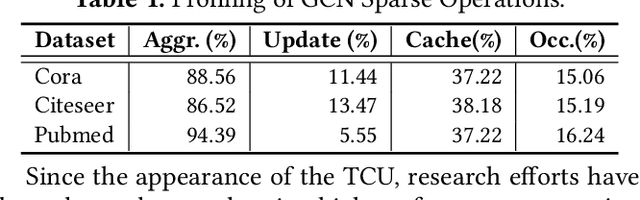
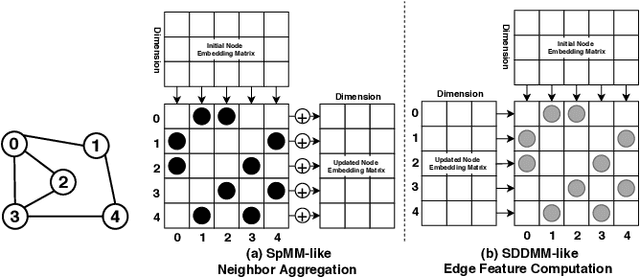

Recently, graph neural networks (GNNs), as the backbone of graph-based machine learning, demonstrate great success in various domains (e.g., e-commerce). However, the performance of GNNs is usually unsatisfactory due to the highly sparse and irregular graph-based operations. To this end, we propose, TC-GNN, the first GPU Tensor Core Unit (TCU) based GNN acceleration framework. The core idea is to reconcile the "Sparse" GNN computation with "Dense" TCU. Specifically, we conduct an in-depth analysis of the sparse operations in mainstream GNN computing frameworks. We introduce a novel sparse graph translation technique to facilitate TCU processing of sparse GNN workload. We also implement an effective CUDA core and TCU collaboration design to fully utilize GPU resources. We fully integrate TC-GNN with the Pytorch framework for ease of programming. Rigorous experiments show an average of 1.70X speedup over the state-of-the-art Deep Graph Library framework across various GNN models and dataset settings.
Towards Efficient Ansatz Architecture for Variational Quantum Algorithms
Nov 26, 2021
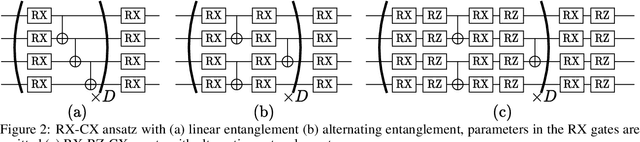
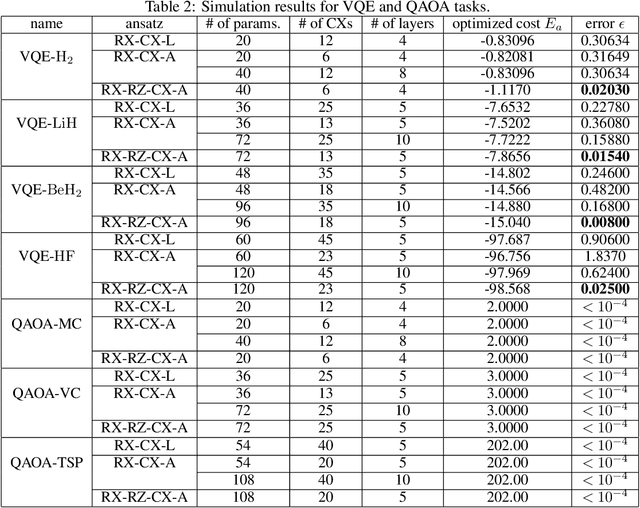
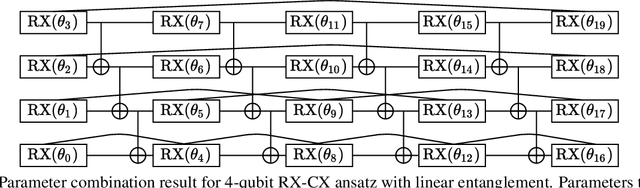
Variational quantum algorithms are expected to demonstrate the advantage of quantum computing on near-term noisy quantum computers. However, training such variational quantum algorithms suffers from gradient vanishing as the size of the algorithm increases. Previous work cannot handle the gradient vanishing induced by the inevitable noise effects on realistic quantum hardware. In this paper, we propose a novel training scheme to mitigate such noise-induced gradient vanishing. We first introduce a new cost function of which the gradients are significantly augmented by employing traceless observables in truncated subspace. We then prove that the same minimum can be reached by optimizing the original cost function with the gradients from the new cost function. Experiments show that our new training scheme is highly effective for major variational quantum algorithms of various tasks.
APNN-TC: Accelerating Arbitrary Precision Neural Networks on Ampere GPU Tensor Cores
Jun 23, 2021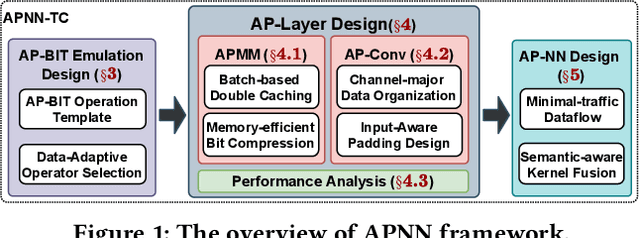

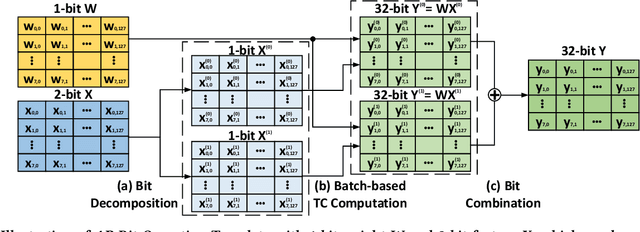

Over the years, accelerating neural networks with quantization has been widely studied. Unfortunately, prior efforts with diverse precisions (e.g., 1-bit weights and 2-bit activations) are usually restricted by limited precision support on GPUs (e.g., int1 and int4). To break such restrictions, we introduce the first Arbitrary Precision Neural Network framework (APNN-TC) to fully exploit quantization benefits on Ampere GPU Tensor Cores. Specifically, APNN-TC first incorporates a novel emulation algorithm to support arbitrary short bit-width computation with int1 compute primitives and XOR/AND Boolean operations. Second, APNN-TC integrates arbitrary precision layer designs to efficiently map our emulation algorithm to Tensor Cores with novel batching strategies and specialized memory organization. Third, APNN-TC embodies a novel arbitrary precision NN design to minimize memory access across layers and further improve performance. Extensive evaluations show that APNN-TC can achieve significant speedup over CUTLASS kernels and various NN models, such as ResNet and VGG.
DSXplore: Optimizing Convolutional Neural Networks via Sliding-Channel Convolutions
Jan 04, 2021
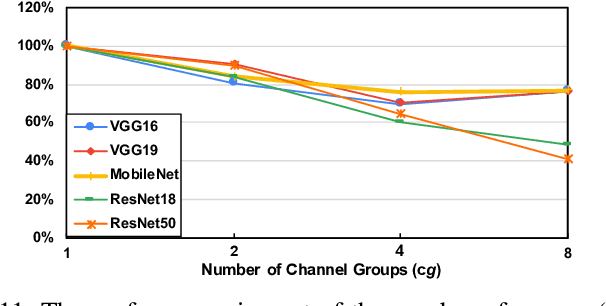
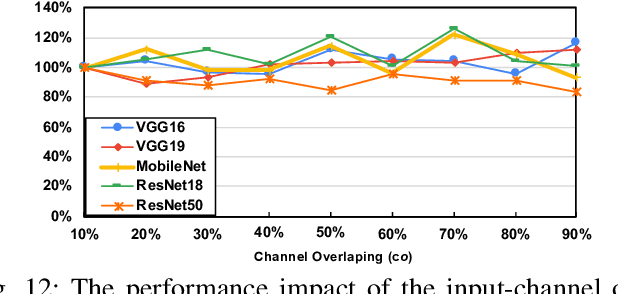
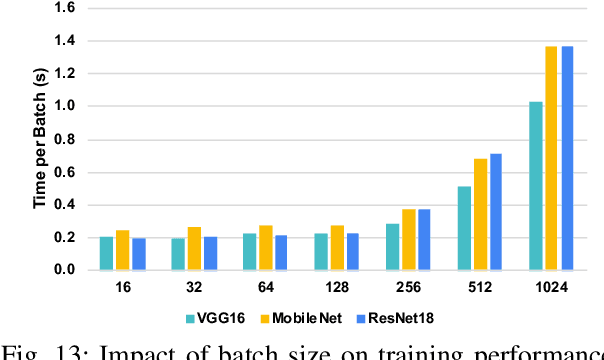
As the key advancement of the convolutional neural networks (CNNs), depthwise separable convolutions (DSCs) are becoming one of the most popular techniques to reduce the computations and parameters size of CNNs meanwhile maintaining the model accuracy. It also brings profound impact to improve the applicability of the compute- and memory-intensive CNNs to a broad range of applications, such as mobile devices, which are generally short of computation power and memory. However, previous research in DSCs are largely focusing on compositing the limited existing DSC designs, thus, missing the opportunities to explore more potential designs that can achieve better accuracy and higher computation/parameter reduction. Besides, the off-the-shelf convolution implementations offer limited computing schemes, therefore, lacking support for DSCs with different convolution patterns. To this end, we introduce, DSXplore, the first optimized design for exploring DSCs on CNNs. Specifically, at the algorithm level, DSXplore incorporates a novel factorized kernel -- sliding-channel convolution (SCC), featured with input-channel overlapping to balance the accuracy performance and the reduction of computation and memory cost. SCC also offers enormous space for design exploration by introducing adjustable kernel parameters. Further, at the implementation level, we carry out an optimized GPU-implementation tailored for SCC by leveraging several key techniques, such as the input-centric backward design and the channel-cyclic optimization. Intensive experiments on different datasets across mainstream CNNs show the advantages of DSXplore in balancing accuracy and computation/parameter reduction over the standard convolution and the existing DSCs.