 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlex Attention: A Programming Model for Generating Optimized Attention Kernels
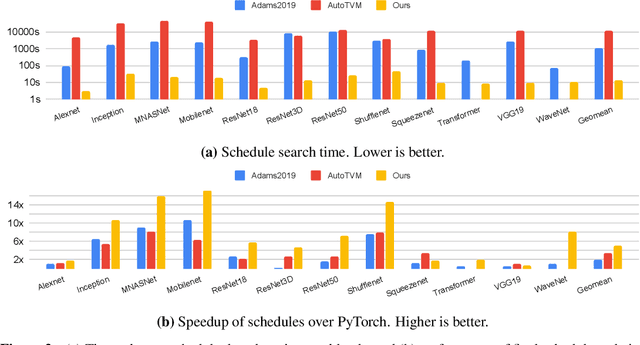
Dec 07, 2024Over the past 7 years, attention has become one of the most important primitives in deep learning. The primary approach to optimize attention is FlashAttention, which fuses the operation together, drastically improving both the runtime and the memory consumption. However, the importance of FlashAttention combined with its monolithic nature poses a problem for researchers aiming to try new attention variants -- a "software lottery". This problem is exacerbated by the difficulty of writing efficient fused attention kernels, resisting traditional compiler-based approaches. We introduce FlexAttention, a novel compiler-driven programming model that allows implementing the majority of attention variants in a few lines of idiomatic PyTorch code. We demonstrate that many existing attention variants (e.g. Alibi, Document Masking, PagedAttention, etc.) can be implemented via FlexAttention, and that we achieve competitive performance compared to these handwritten kernels. Finally, we demonstrate how FlexAttention allows for easy composition of attention variants, solving the combinatorial explosion of attention variants.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022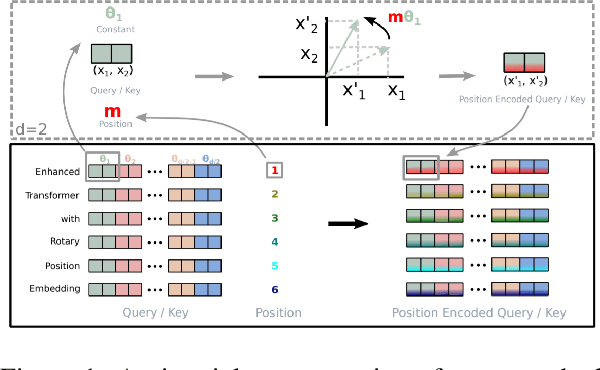
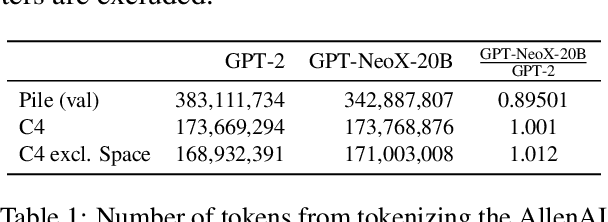
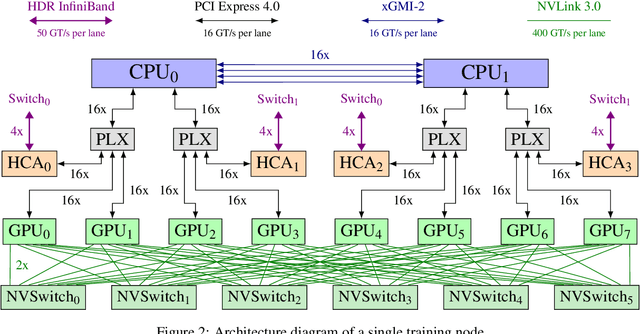

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
torch.fx: Practical Program Capture and Transformation for Deep Learning in Python
Dec 15, 2021



Modern deep learning frameworks provide imperative, eager execution programming interfaces embedded in Python to provide a productive development experience. However, deep learning practitioners sometimes need to capture and transform program structure for performance optimization, visualization, analysis, and hardware integration. We study the different designs for program capture and transformation used in deep learning. By designing for typical deep learning use cases rather than long tail ones, it is possible to create a simpler framework for program capture and transformation. We apply this principle in torch.fx, a program capture and transformation library for PyTorch written entirely in Python and optimized for high developer productivity by ML practitioners. We present case studies showing how torch.fx enables workflows previously inaccessible in the PyTorch ecosystem.
Edge Proposal Sets for Link Prediction
Jun 30, 2021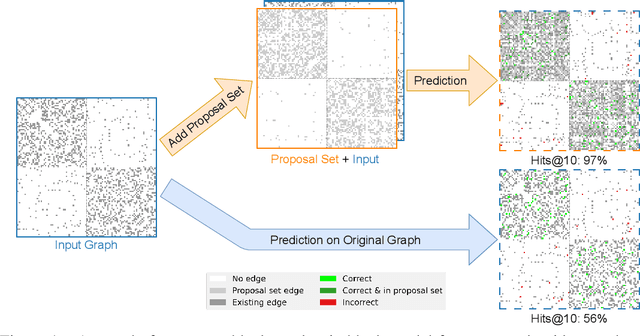
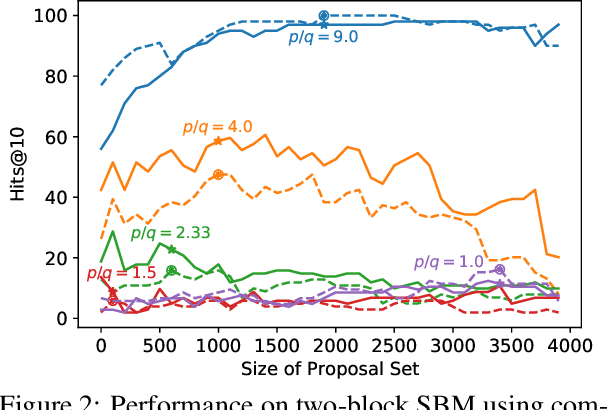
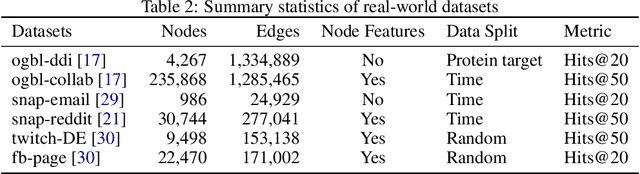
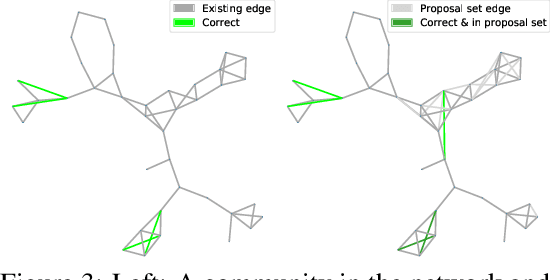
Graphs are a common model for complex relational data such as social networks and protein interactions, and such data can evolve over time (e.g., new friendships) and be noisy (e.g., unmeasured interactions). Link prediction aims to predict future edges or infer missing edges in the graph, and has diverse applications in recommender systems, experimental design, and complex systems. Even though link prediction algorithms strongly depend on the set of edges in the graph, existing approaches typically do not modify the graph topology to improve performance. Here, we demonstrate how simply adding a set of edges, which we call a \emph{proposal set}, to the graph as a pre-processing step can improve the performance of several link prediction algorithms. The underlying idea is that if the edges in the proposal set generally align with the structure of the graph, link prediction algorithms are further guided towards predicting the right edges; in other words, adding a proposal set of edges is a signal-boosting pre-processing step. We show how to use existing link prediction algorithms to generate effective proposal sets and evaluate this approach on various synthetic and empirical datasets. We find that proposal sets meaningfully improve the accuracy of link prediction algorithms based on both neighborhood heuristics and graph neural networks. Code is available at \url{https://github.com/CUAI/Edge-Proposal-Sets}.
Measuring Coding Challenge Competence With APPS
May 27, 2021



While programming is one of the most broadly applicable skills in modern society, modern machine learning models still cannot code solutions to basic problems. Despite its importance, there has been surprisingly little work on evaluating code generation, and it can be difficult to accurately assess code generation performance rigorously. To meet this challenge, we introduce APPS, a benchmark for code generation. Unlike prior work in more restricted settings, our benchmark measures the ability of models to take an arbitrary natural language specification and generate satisfactory Python code. Similar to how companies assess candidate software developers, we then evaluate models by checking their generated code on test cases. Our benchmark includes 10,000 problems, which range from having simple one-line solutions to being substantial algorithmic challenges. We fine-tune large language models on both GitHub and our training set, and we find that the prevalence of syntax errors is decreasing exponentially as models improve. Recent models such as GPT-Neo can pass approximately 20% of the test cases of introductory problems, so we find that machine learning models are now beginning to learn how to code. As the social significance of automatic code generation increases over the coming years, our benchmark can provide an important measure for tracking advancements.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020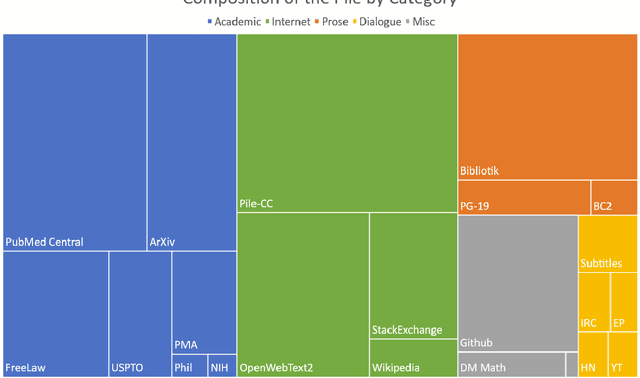
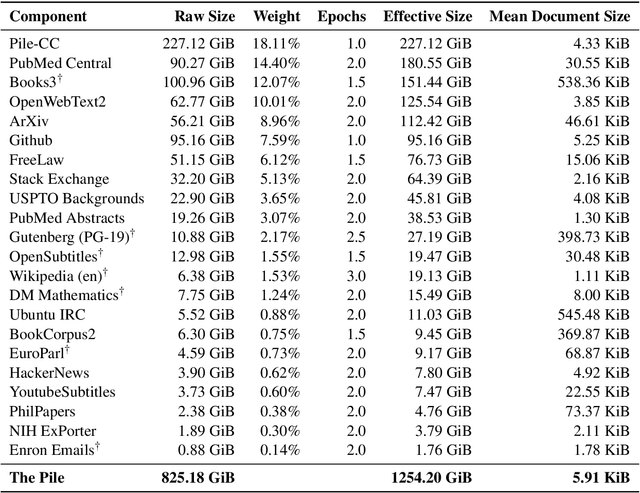
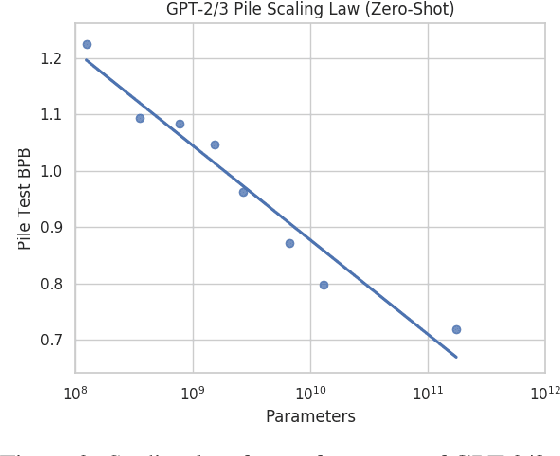
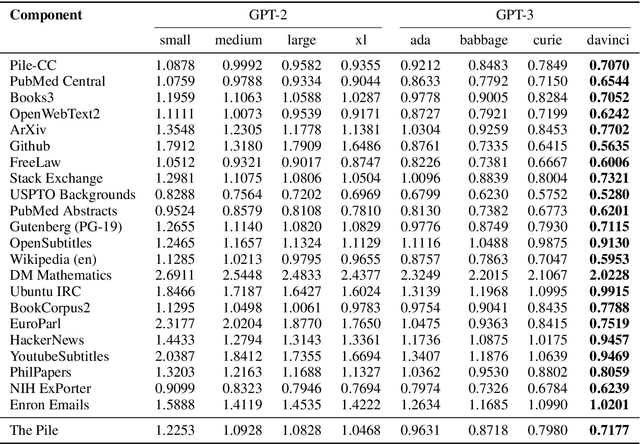
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.
Value Function Based Performance Optimization of Deep Learning Workloads
Nov 30, 2020
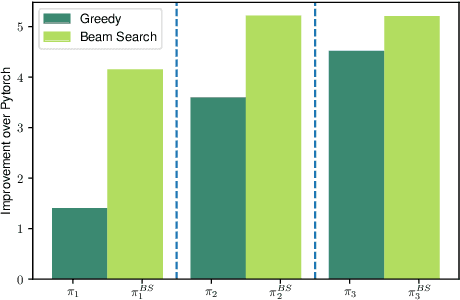
As machine learning techniques become ubiquitous, the efficiency of neural network implementations is becoming correspondingly paramount. Frameworks, such as Halide and TVM, separate out the algorithmic representation of the network from the schedule that determines its implementation. Finding good schedules, however, remains extremely challenging. We model this scheduling problem as a sequence of optimization choices, and present a new technique to accurately predict the expected performance of a partial schedule. By leveraging these predictions we can make these optimization decisions greedily and rapidly identify an efficient schedule. This enables us to find schedules that improve the throughput of deep neural networks by 2.6x over Halide and 1.5x over TVM. Moreover, our technique is two to three orders of magnitude faster than that of these tools, and completes in seconds instead of hours.
Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
Nov 02, 2020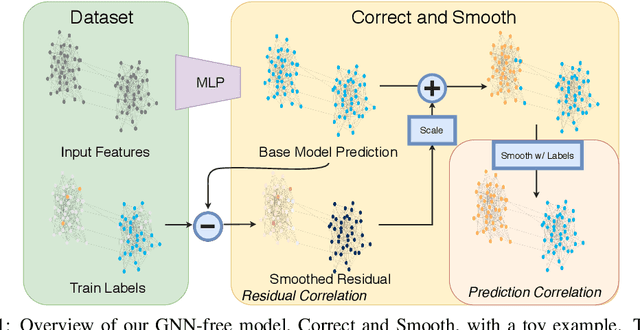
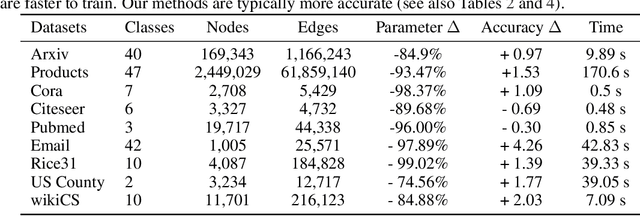
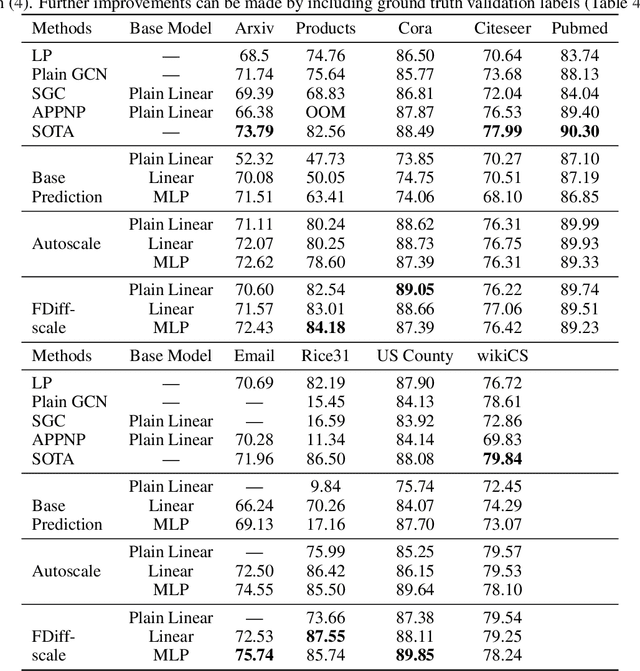
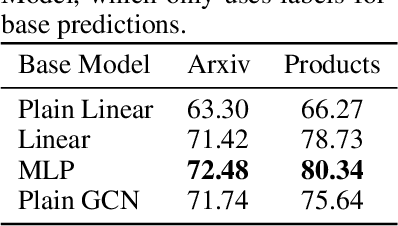
Graph Neural Networks (GNNs) are the predominant technique for learning over graphs. However, there is relatively little understanding of why GNNs are successful in practice and whether they are necessary for good performance. Here, we show that for many standard transductive node classification benchmarks, we can exceed or match the performance of state-of-the-art GNNs by combining shallow models that ignore the graph structure with two simple post-processing steps that exploit correlation in the label structure: (i) an "error correlation" that spreads residual errors in training data to correct errors in test data and (ii) a "prediction correlation" that smooths the predictions on the test data. We call this overall procedure Correct and Smooth (C&S), and the post-processing steps are implemented via simple modifications to standard label propagation techniques from early graph-based semi-supervised learning methods. Our approach exceeds or nearly matches the performance of state-of-the-art GNNs on a wide variety of benchmarks, with just a small fraction of the parameters and orders of magnitude faster runtime. For instance, we exceed the best known GNN performance on the OGB-Products dataset with 137 times fewer parameters and greater than 100 times less training time. The performance of our methods highlights how directly incorporating label information into the learning algorithm (as was done in traditional techniques) yields easy and substantial performance gains. We can also incorporate our techniques into big GNN models, providing modest gains. Our code for the OGB results is at https://github.com/Chillee/CorrectAndSmooth.
Set-Structured Latent Representations
Mar 09, 2020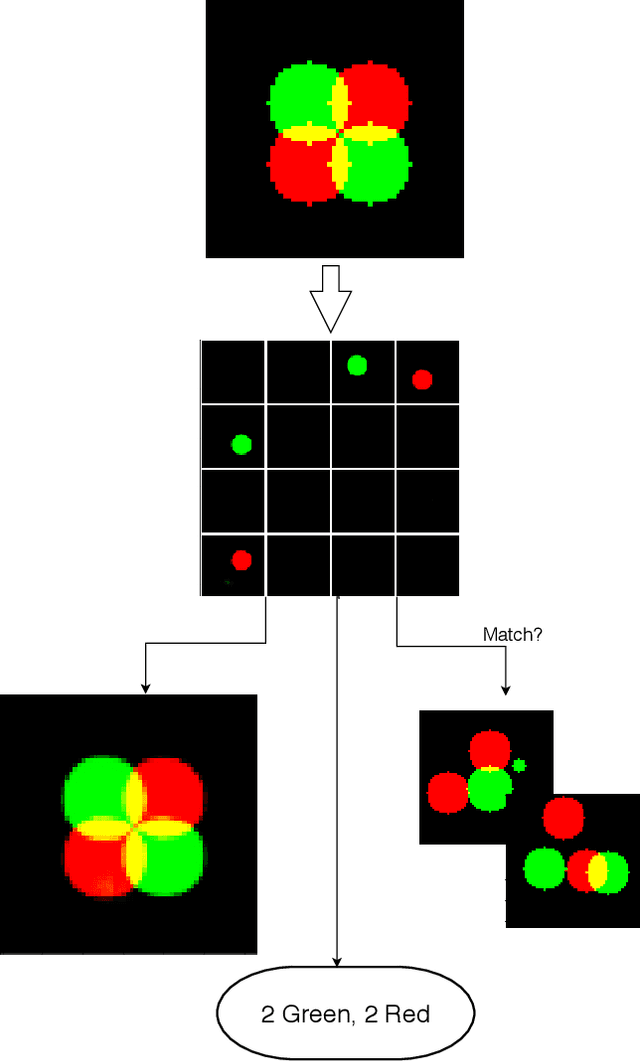
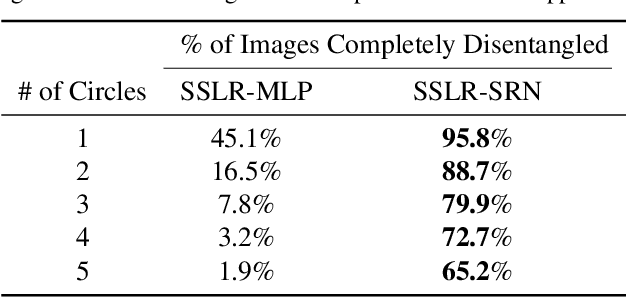

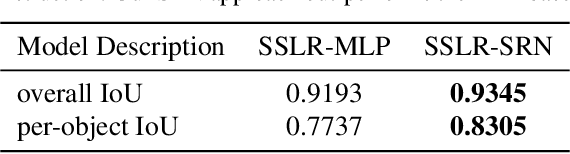
Unstructured data often has latent component structure, such as the objects in an image of a scene. In these situations, the relevant latent structure is an unordered collection or \emph{set}. However, learning such representations directly from data is difficult due to the discrete and unordered structure. Here, we develop a framework for differentiable learning of set-structured latent representations. We show how to use this framework to naturally decompose data such as images into sets of interpretable and meaningful components and demonstrate how existing techniques cannot properly disentangle relevant structure. We also show how to extend our methodology to downstream tasks such as set matching, which uses set-specific operations. Our code is available at https://github.com/CUVL/SSLR.
Enhancing Adversarial Example Transferability with an Intermediate Level Attack
Jul 23, 2019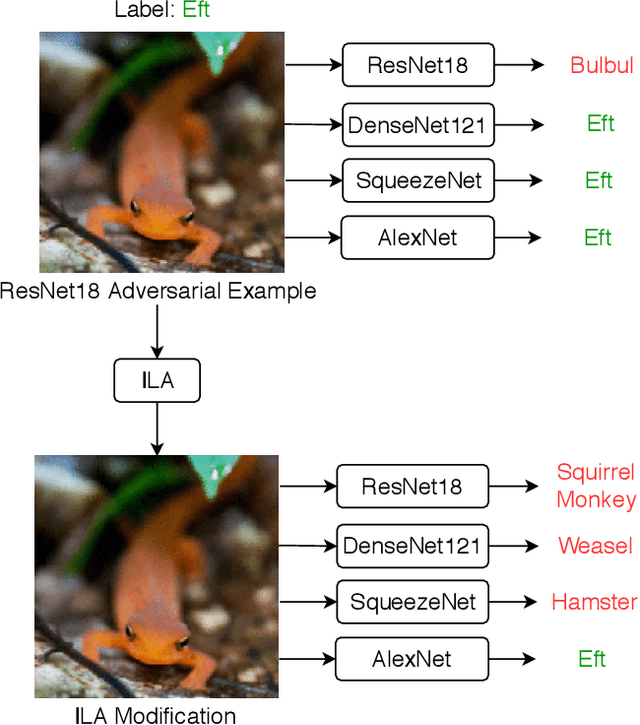
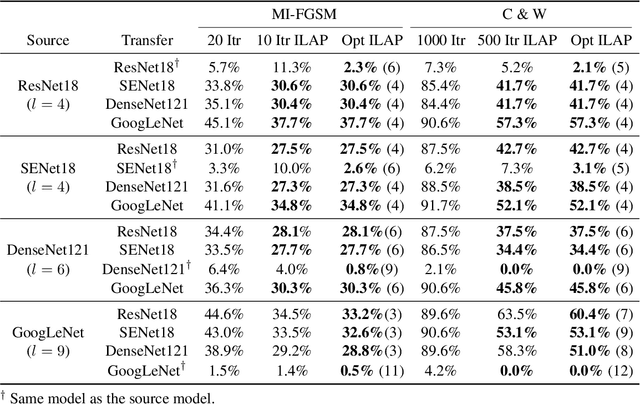

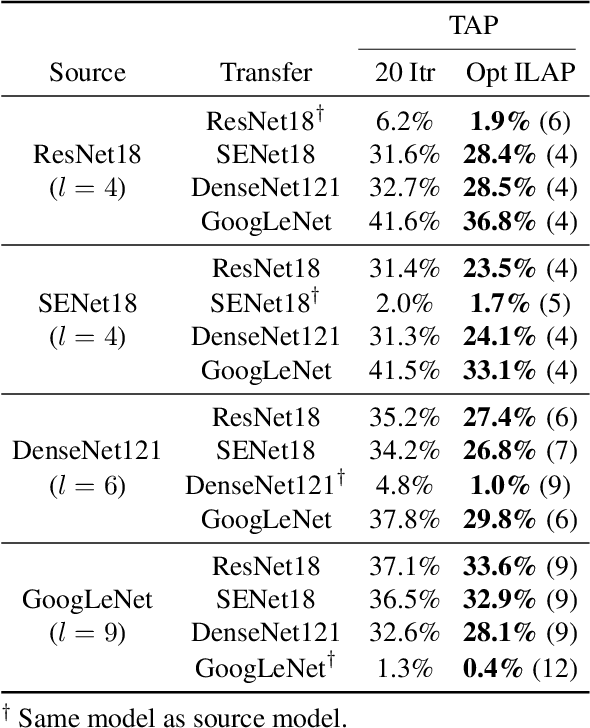
Neural networks are vulnerable to adversarial examples, malicious inputs crafted to fool trained models. Adversarial examples often exhibit black-box transfer, meaning that adversarial examples for one model can fool another model. However, adversarial examples are typically overfit to exploit the particular architecture and feature representation of a source model, resulting in sub-optimal black-box transfer attacks to other target models. We introduce the Intermediate Level Attack (ILA), which attempts to fine-tune an existing adversarial example for greater black-box transferability by increasing its perturbation on a pre-specified layer of the source model, improving upon state-of-the-art methods. We show that we can select a layer of the source model to perturb without any knowledge of the target models while achieving high transferability. Additionally, we provide some explanatory insights regarding our method and the effect of optimizing for adversarial examples in intermediate feature maps.