 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrent Neural Tree and Data Preprocessing AutoML for Image Classification
May 25, 2022
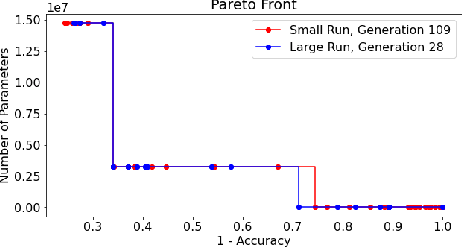

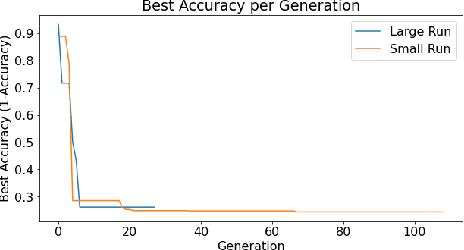
Deep Neural Networks (DNN's) are a widely-used solution for a variety of machine learning problems. However, it is often necessary to invest a significant amount of a data scientist's time to pre-process input data, test different neural network architectures, and tune hyper-parameters for optimal performance. Automated machine learning (autoML) methods automatically search the architecture and hyper-parameter space for optimal neural networks. However, current state-of-the-art (SOTA) methods do not include traditional methods for manipulating input data as part of the algorithmic search space. We adapt the Evolutionary Multi-objective Algorithm Design Engine (EMADE), a multi-objective evolutionary search framework for traditional machine learning methods, to perform neural architecture search. We also integrate EMADE's signal processing and image processing primitives. These primitives allow EMADE to manipulate input data before ingestion into the simultaneously evolved DNN. We show that including these methods as part of the search space shows potential to provide benefits to performance on the CIFAR-10 image classification benchmark dataset.
Evolving SimGANs to Improve Abnormal Electrocardiogram Classification
May 12, 2022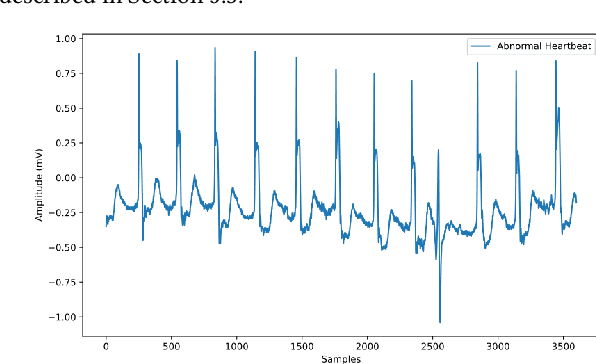

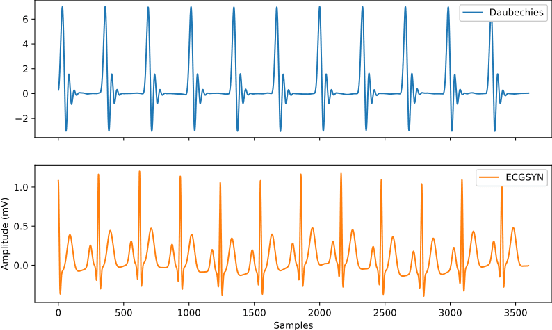
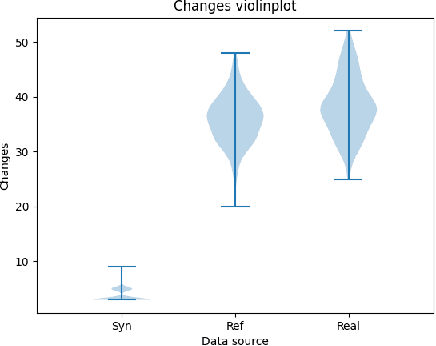
Machine Learning models are used in a wide variety of domains. However, machine learning methods often require a large amount of data in order to be successful. This is especially troublesome in domains where collecting real-world data is difficult and/or expensive. Data simulators do exist for many of these domains, but they do not sufficiently reflect the real world data due to factors such as a lack of real-world noise. Recently generative adversarial networks (GANs) have been modified to refine simulated image data into data that better fits the real world distribution, using the SimGAN method. While evolutionary computing has been used for GAN evolution, there are currently no frameworks that can evolve a SimGAN. In this paper we (1) extend the SimGAN method to refine one-dimensional data, (2) modify Easy Cartesian Genetic Programming (ezCGP), an evolutionary computing framework, to create SimGANs that more accurately refine simulated data, and (3) create new feature-based quantitative metrics to evaluate refined data. We also use our framework to augment an electrocardiogram (ECG) dataset, a domain that suffers from the issues previously mentioned. In particular, while healthy ECGs can be simulated there are no current simulators of abnormal ECGs. We show that by using an evolved SimGAN to refine simulated healthy ECG data to mimic real-world abnormal ECGs, we can improve the accuracy of abnormal ECG classifiers.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020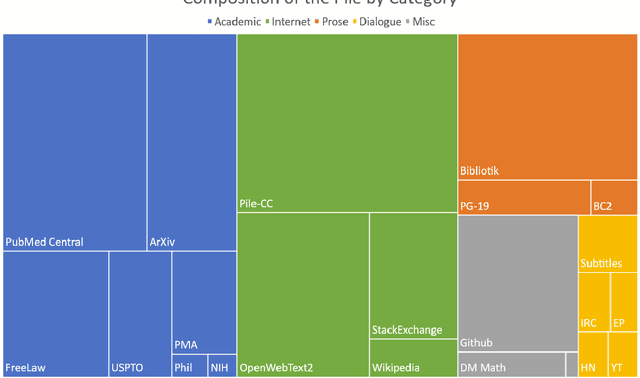
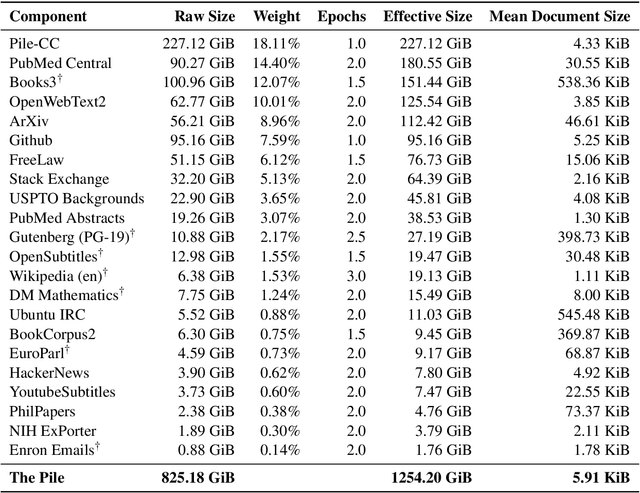
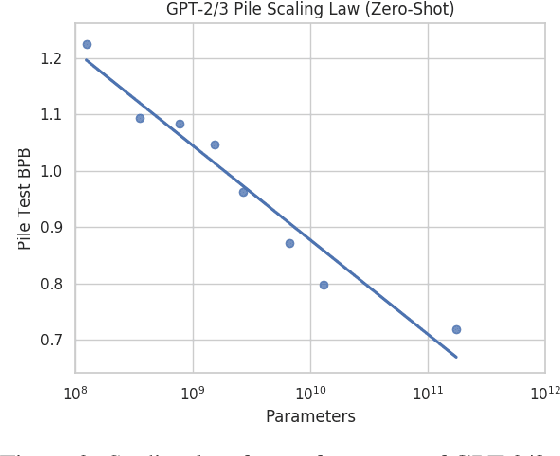
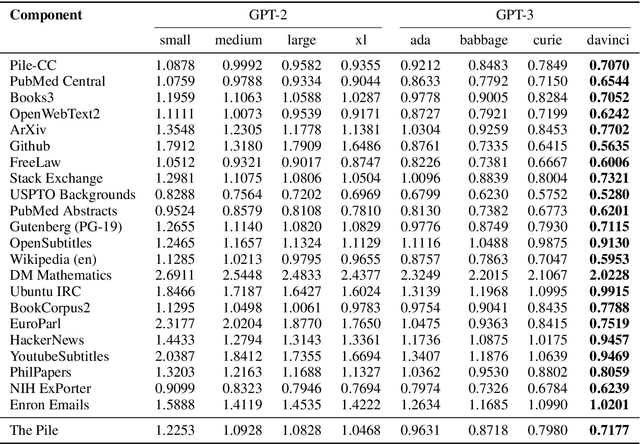
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.