 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Synthetic Text Generation with SimpleStories
Apr 12, 2025We present SimpleStories, a large synthetic story dataset in simple language, consisting of 2 million stories each in English and Japanese. Our method employs parametrization of prompts with features at multiple levels of abstraction, allowing for systematic control over story characteristics to ensure broad syntactic and semantic diversity. Building on and addressing limitations in the TinyStories dataset, our approach demonstrates that simplicity and variety can be achieved simultaneously in synthetic text generation at scale.
Adversarial Training for High-Stakes Reliability
May 04, 2022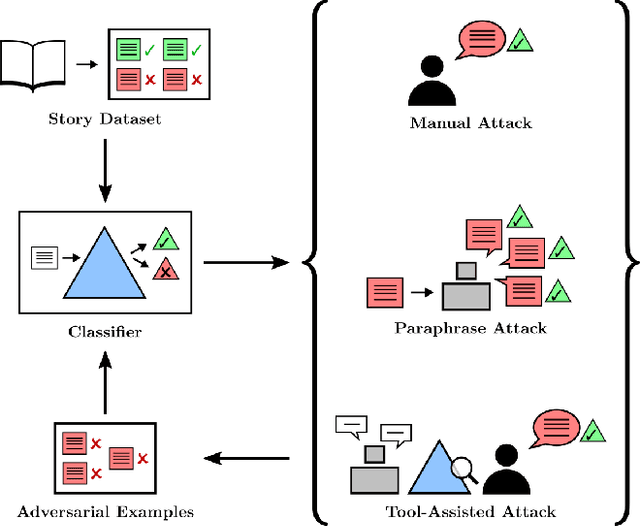
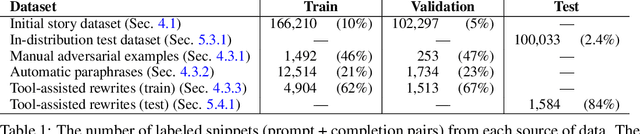


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Dec 31, 2020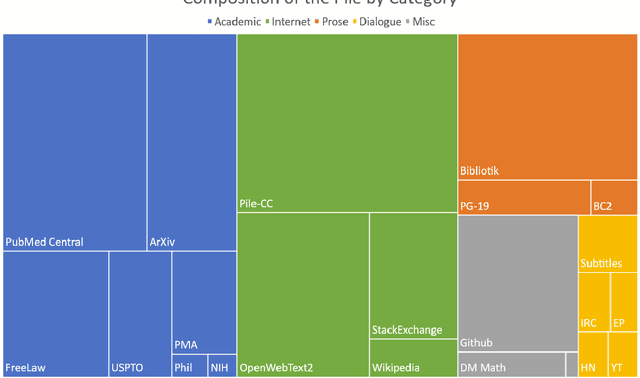
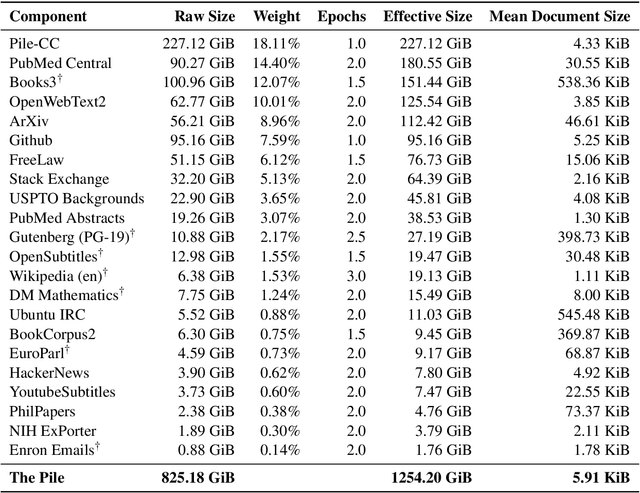
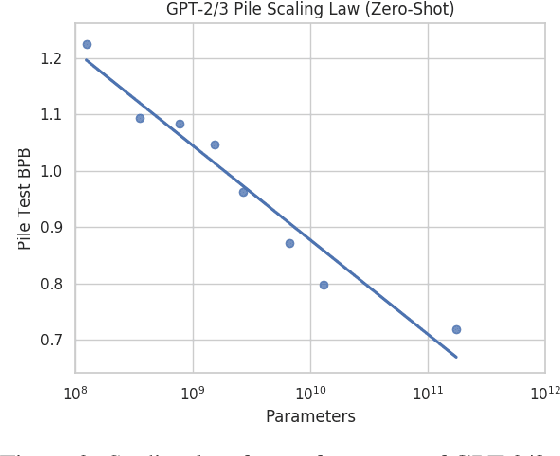
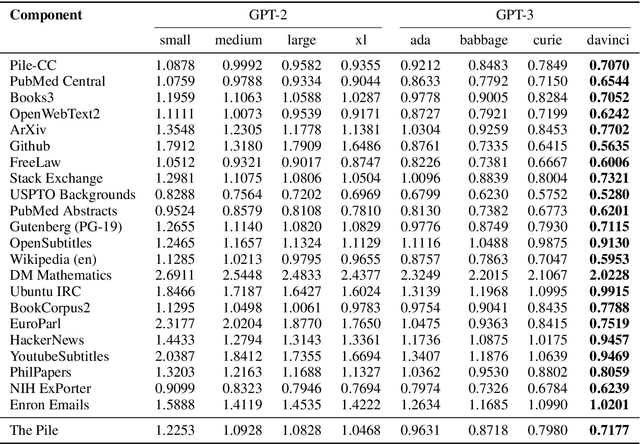
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets -- both existing and newly constructed -- many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.