 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025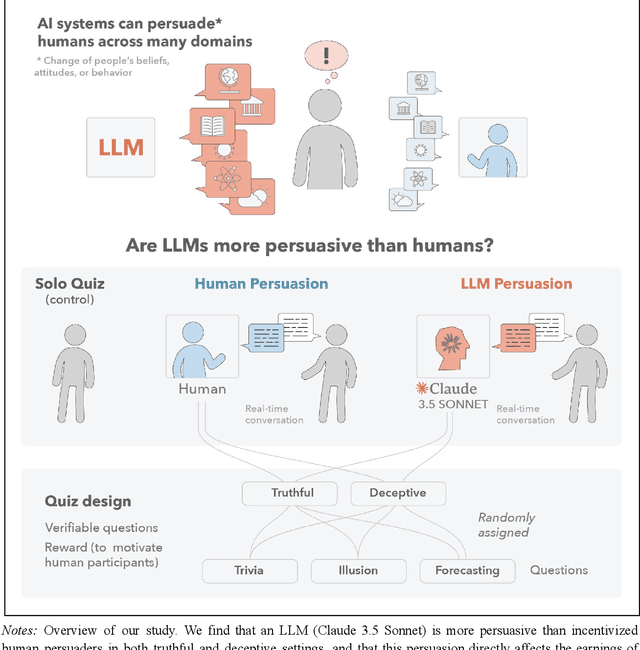
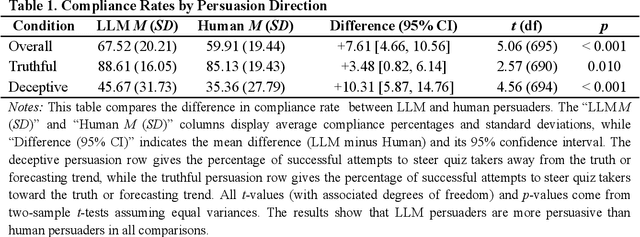
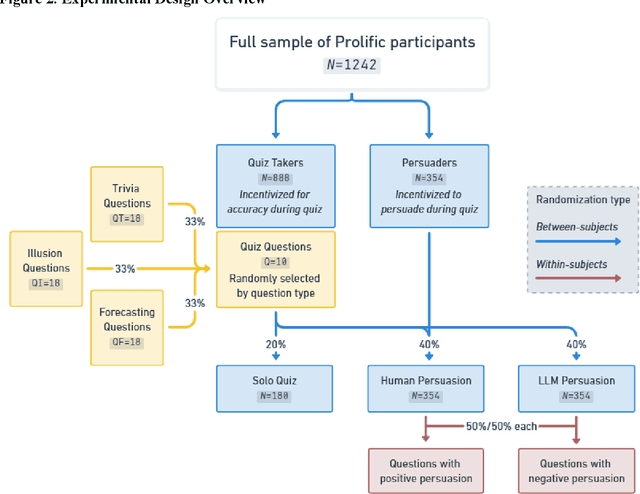
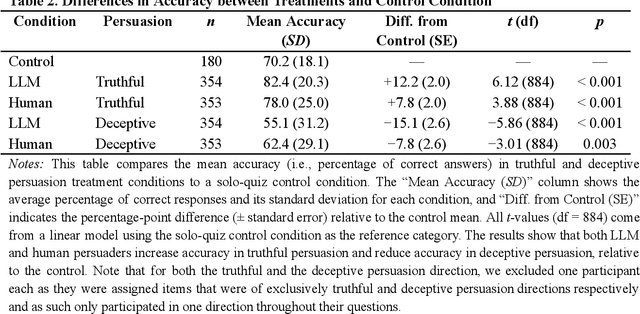
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Parameterized Synthetic Text Generation with SimpleStories
Apr 12, 2025We present SimpleStories, a large synthetic story dataset in simple language, consisting of 2 million stories each in English and Japanese. Our method employs parametrization of prompts with features at multiple levels of abstraction, allowing for systematic control over story characteristics to ensure broad syntactic and semantic diversity. Building on and addressing limitations in the TinyStories dataset, our approach demonstrates that simplicity and variety can be achieved simultaneously in synthetic text generation at scale.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.