 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025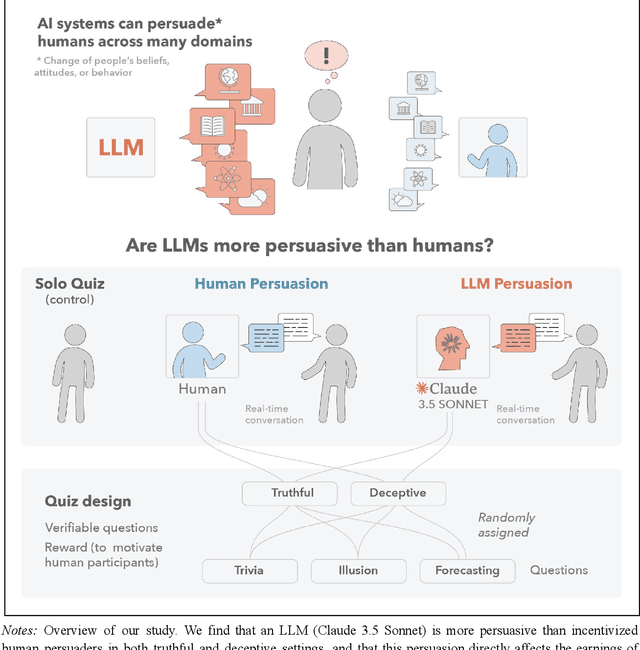
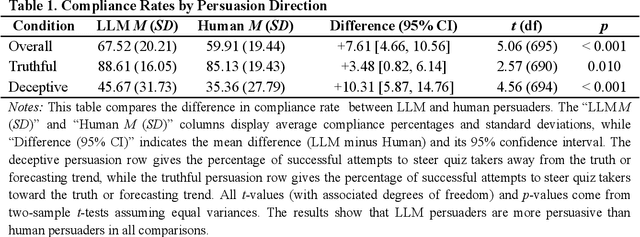
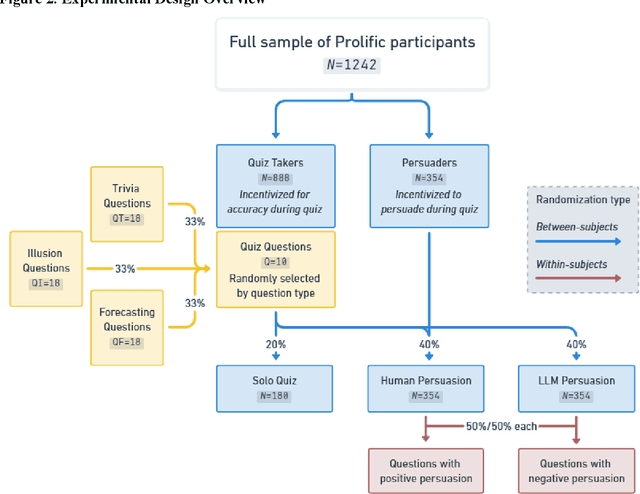
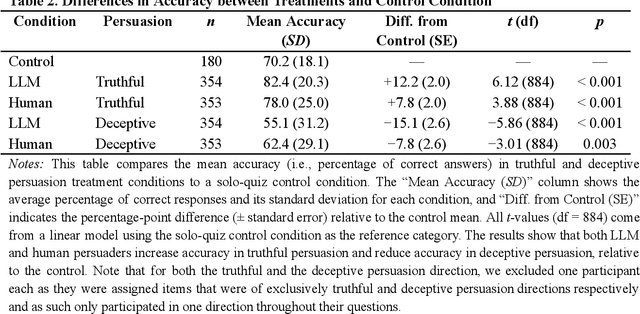
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
FindTheFlaws: Annotated Errors for Detecting Flawed Reasoning and Scalable Oversight Research
Mar 29, 2025



As AI models tackle increasingly complex problems, ensuring reliable human oversight becomes more challenging due to the difficulty of verifying solutions. Approaches to scaling AI supervision include debate, in which two agents engage in structured dialogue to help a judge evaluate claims; critique, in which models identify potential flaws in proposed solutions; and prover-verifier games, in which a capable 'prover' model generates solutions that must be verifiable by a less capable 'verifier'. Evaluations of the scalability of these and similar approaches to difficult problems benefit from datasets that include (1) long-form expert-verified correct solutions and (2) long-form flawed solutions with annotations highlighting specific errors, but few are available. To address this gap, we present FindTheFlaws, a group of five diverse datasets spanning medicine, mathematics, science, coding, and the Lojban language. Each dataset contains questions and long-form solutions with expert annotations validating their correctness or identifying specific error(s) in the reasoning. We evaluate frontier models' critiquing capabilities and observe a range of performance that can be leveraged for scalable oversight experiments: models performing more poorly on particular datasets can serve as judges/verifiers for more capable models. Additionally, for some task/dataset combinations, expert baselines exceed even top model performance, making them more beneficial for scalable oversight experiments.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024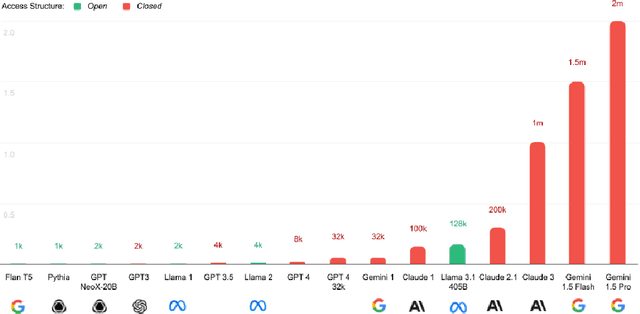



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Teaching Autoregressive Language Models Complex Tasks By Demonstration
Sep 11, 2021
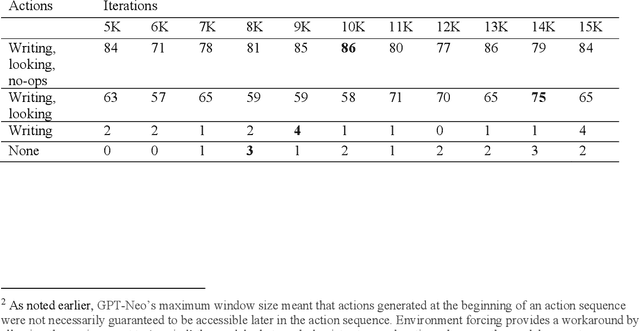


This paper demonstrates that by fine-tuning an autoregressive language model (GPT-Neo) on appropriately structured step-by-step demonstrations, it is possible to teach it to execute a mathematical task that has previously proved difficult for Transformers - longhand modulo operations - with a relatively small number of examples. Specifically, we fine-tune GPT-Neo to solve the numbers__div_remainder task from the DeepMind Mathematics Dataset; Saxton et al. (arXiv:1904.01557) reported below 40% accuracy on this task with 2 million training examples. We show that after fine-tuning on 200 appropriately structured demonstrations of solving long division problems and reporting the remainders, the smallest available GPT-Neo model achieves over 80% accuracy. This is achieved by constructing an appropriate dataset for fine-tuning, with no changes to the learning algorithm. These results suggest that fine-tuning autoregressive language models on small sets of well-crafted demonstrations may be a useful paradigm for enabling individuals without training in machine learning to coax such models to perform some kinds of complex multi-step tasks.