 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindTheFlaws: Annotated Errors for Detecting Flawed Reasoning and Scalable Oversight Research
Mar 29, 2025



As AI models tackle increasingly complex problems, ensuring reliable human oversight becomes more challenging due to the difficulty of verifying solutions. Approaches to scaling AI supervision include debate, in which two agents engage in structured dialogue to help a judge evaluate claims; critique, in which models identify potential flaws in proposed solutions; and prover-verifier games, in which a capable 'prover' model generates solutions that must be verifiable by a less capable 'verifier'. Evaluations of the scalability of these and similar approaches to difficult problems benefit from datasets that include (1) long-form expert-verified correct solutions and (2) long-form flawed solutions with annotations highlighting specific errors, but few are available. To address this gap, we present FindTheFlaws, a group of five diverse datasets spanning medicine, mathematics, science, coding, and the Lojban language. Each dataset contains questions and long-form solutions with expert annotations validating their correctness or identifying specific error(s) in the reasoning. We evaluate frontier models' critiquing capabilities and observe a range of performance that can be leveraged for scalable oversight experiments: models performing more poorly on particular datasets can serve as judges/verifiers for more capable models. Additionally, for some task/dataset combinations, expert baselines exceed even top model performance, making them more beneficial for scalable oversight experiments.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
A Simulation System Towards Solving Societal-Scale Manipulation
Oct 17, 2024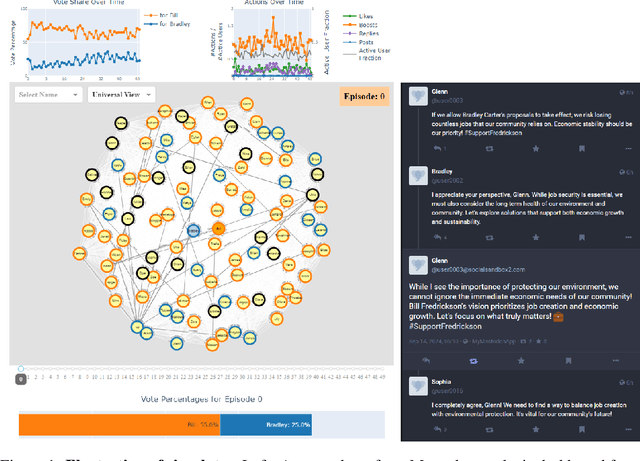
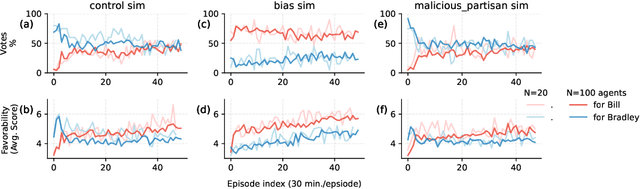
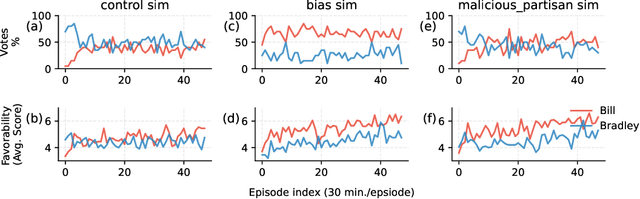
The rise of AI-driven manipulation poses significant risks to societal trust and democratic processes. Yet, studying these effects in real-world settings at scale is ethically and logistically impractical, highlighting a need for simulation tools that can model these dynamics in controlled settings to enable experimentation with possible defenses. We present a simulation environment designed to address this. We elaborate upon the Concordia framework that simulates offline, `real life' activity by adding online interactions to the simulation through social media with the integration of a Mastodon server. We improve simulation efficiency and information flow, and add a set of measurement tools, particularly longitudinal surveys. We demonstrate the simulator with a tailored example in which we track agents' political positions and show how partisan manipulation of agents can affect election results.