 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenFake: An Open Dataset and Platform Toward Large-Scale Deepfake Detection
Sep 11, 2025Deepfakes, synthetic media created using advanced AI techniques, have intensified the spread of misinformation, particularly in politically sensitive contexts. Existing deepfake detection datasets are often limited, relying on outdated generation methods, low realism, or single-face imagery, restricting the effectiveness for general synthetic image detection. By analyzing social media posts, we identify multiple modalities through which deepfakes propagate misinformation. Furthermore, our human perception study demonstrates that recently developed proprietary models produce synthetic images increasingly indistinguishable from real ones, complicating accurate identification by the general public. Consequently, we present a comprehensive, politically-focused dataset specifically crafted for benchmarking detection against modern generative models. This dataset contains three million real images paired with descriptive captions, which are used for generating 963k corresponding high-quality synthetic images from a mix of proprietary and open-source models. Recognizing the continual evolution of generative techniques, we introduce an innovative crowdsourced adversarial platform, where participants are incentivized to generate and submit challenging synthetic images. This ongoing community-driven initiative ensures that deepfake detection methods remain robust and adaptive, proactively safeguarding public discourse from sophisticated misinformation threats.
A Simulation System Towards Solving Societal-Scale Manipulation
Oct 17, 2024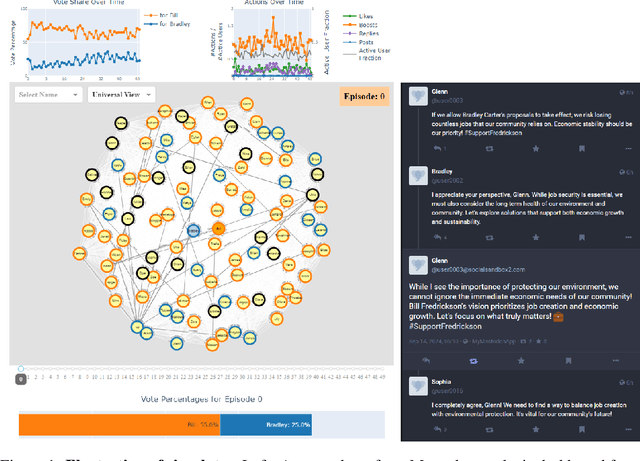
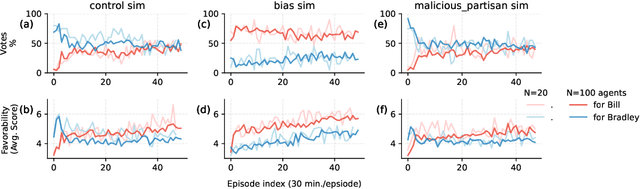
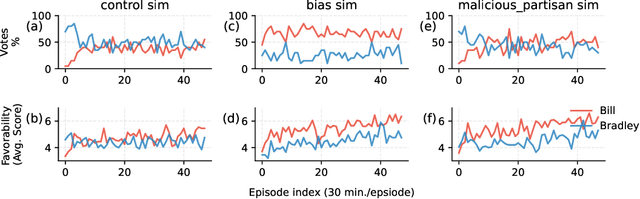
The rise of AI-driven manipulation poses significant risks to societal trust and democratic processes. Yet, studying these effects in real-world settings at scale is ethically and logistically impractical, highlighting a need for simulation tools that can model these dynamics in controlled settings to enable experimentation with possible defenses. We present a simulation environment designed to address this. We elaborate upon the Concordia framework that simulates offline, `real life' activity by adding online interactions to the simulation through social media with the integration of a Mastodon server. We improve simulation efficiency and information flow, and add a set of measurement tools, particularly longitudinal surveys. We demonstrate the simulator with a tailored example in which we track agents' political positions and show how partisan manipulation of agents can affect election results.
Towards Detecting Contextual Real-Time Toxicity for In-Game Chat
Oct 20, 2023



Real-time toxicity detection in online environments poses a significant challenge, due to the increasing prevalence of social media and gaming platforms. We introduce ToxBuster, a simple and scalable model that reliably detects toxic content in real-time for a line of chat by including chat history and metadata. ToxBuster consistently outperforms conventional toxicity models across popular multiplayer games, including Rainbow Six Siege, For Honor, and DOTA 2. We conduct an ablation study to assess the importance of each model component and explore ToxBuster's transferability across the datasets. Furthermore, we showcase ToxBuster's efficacy in post-game moderation, successfully flagging 82.1% of chat-reported players at a precision level of 90.0%. Additionally, we show how an additional 6% of unreported toxic players can be proactively moderated.
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.
Open, Closed, or Small Language Models for Text Classification?
Aug 19, 2023



Recent advancements in large language models have demonstrated remarkable capabilities across various NLP tasks. But many questions remain, including whether open-source models match closed ones, why these models excel or struggle with certain tasks, and what types of practical procedures can improve performance. We address these questions in the context of classification by evaluating three classes of models using eight datasets across three distinct tasks: named entity recognition, political party prediction, and misinformation detection. While larger LLMs often lead to improved performance, open-source models can rival their closed-source counterparts by fine-tuning. Moreover, supervised smaller models, like RoBERTa, can achieve similar or even greater performance in many datasets compared to generative LLMs. On the other hand, closed models maintain an advantage in hard tasks that demand the most generalizability. This study underscores the importance of model selection based on task requirements
ToxBuster: In-game Chat Toxicity Buster with BERT
May 21, 2023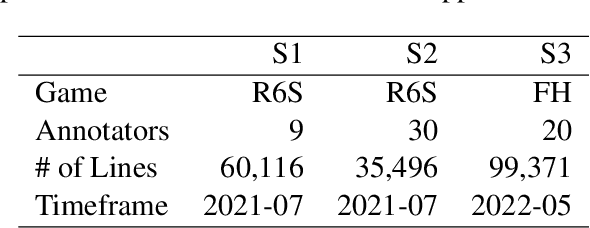
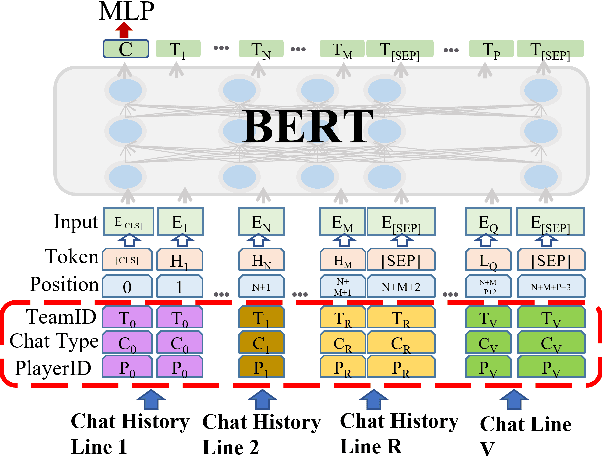
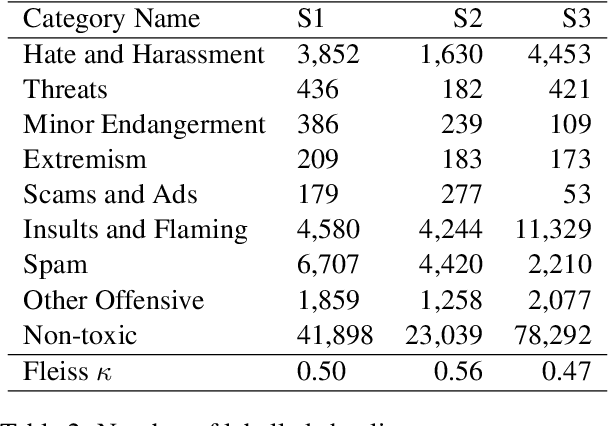
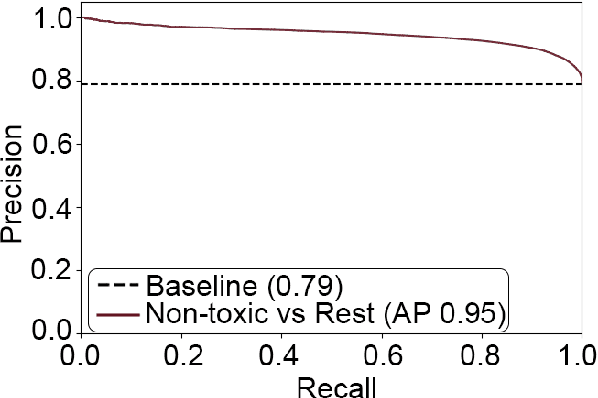
Detecting toxicity in online spaces is challenging and an ever more pressing problem given the increase in social media and gaming consumption. We introduce ToxBuster, a simple and scalable model trained on a relatively large dataset of 194k lines of game chat from Rainbow Six Siege and For Honor, carefully annotated for different kinds of toxicity. Compared to the existing state-of-the-art, ToxBuster achieves 82.95% (+7) in precision and 83.56% (+57) in recall. This improvement is obtained by leveraging past chat history and metadata. We also study the implication towards real-time and post-game moderation as well as the model transferability from one game to another.