 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Opinions Towards Climate Change on Social Media
Dec 02, 2023



Social media platforms such as Twitter (now known as X) have revolutionized how the public engage with important societal and political topics. Recently, climate change discussions on social media became a catalyst for political polarization and the spreading of misinformation. In this work, we aim to understand how real world events influence the opinions of individuals towards climate change related topics on social media. To this end, we extracted and analyzed a dataset of 13.6 millions tweets sent by 3.6 million users from 2006 to 2019. Then, we construct a temporal graph from the user-user mentions network and utilize the Louvain community detection algorithm to analyze the changes in community structure around Conference of the Parties on Climate Change~(COP) events. Next, we also apply tools from the Natural Language Processing literature to perform sentiment analysis and topic modeling on the tweets. Our work acts as a first step towards understanding the evolution of pro-climate change communities around COP events. Answering these questions helps us understand how to raise people's awareness towards climate change thus hopefully calling on more individuals to join the collaborative effort in slowing down climate change.
Party Prediction for Twitter
Aug 25, 2023



A large number of studies on social media compare the behaviour of users from different political parties. As a basic step, they employ a predictive model for inferring their political affiliation. The accuracy of this model can change the conclusions of a downstream analysis significantly, yet the choice between different models seems to be made arbitrarily. In this paper, we provide a comprehensive survey and an empirical comparison of the current party prediction practices and propose several new approaches which are competitive with or outperform state-of-the-art methods, yet require less computational resources. Party prediction models rely on the content generated by the users (e.g., tweet texts), the relations they have (e.g., who they follow), or their activities and interactions (e.g., which tweets they like). We examine all of these and compare their signal strength for the party prediction task. This paper lets the practitioner select from a wide range of data types that all give strong performance. Finally, we conduct extensive experiments on different aspects of these methods, such as data collection speed and transfer capabilities, which can provide further insights for both applied and methodological research.
Active Keyword Selection to Track Evolving Topics on Twitter
Sep 22, 2022
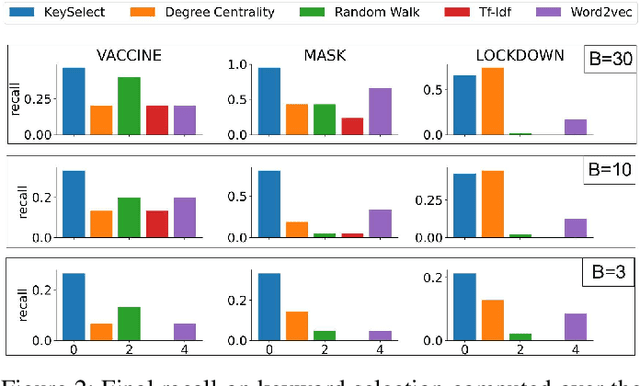
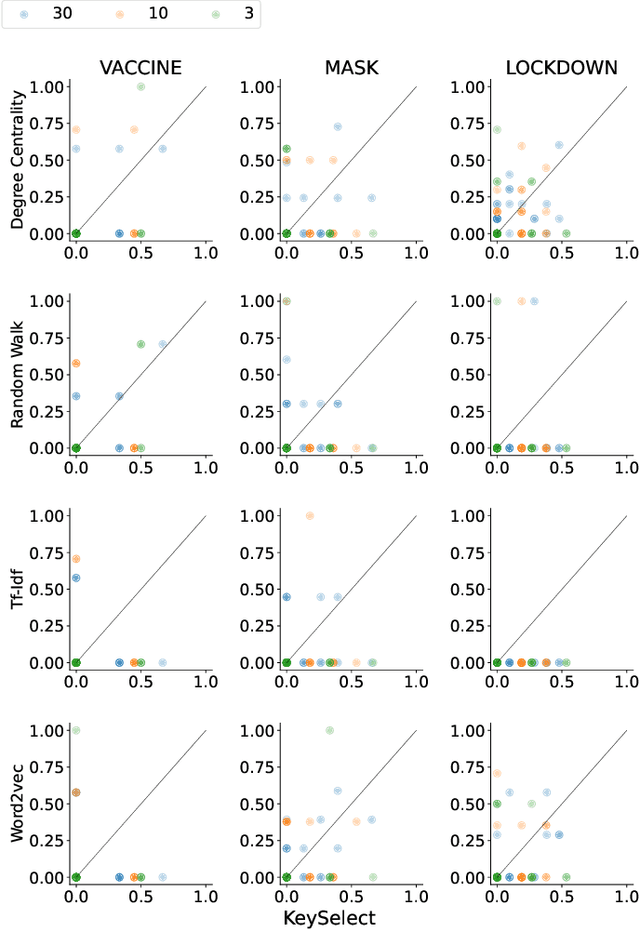
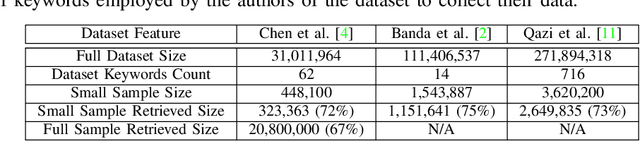
How can we study social interactions on evolving topics at a mass scale? Over the past decade, researchers from diverse fields such as economics, political science, and public health have often done this by querying Twitter's public API endpoints with hand-picked topical keywords to search or stream discussions. However, despite the API's accessibility, it remains difficult to select and update keywords to collect high-quality data relevant to topics of interest. In this paper, we propose an active learning method for rapidly refining query keywords to increase both the yielded topic relevance and dataset size. We leverage a large open-source COVID-19 Twitter dataset to illustrate the applicability of our method in tracking Tweets around the key sub-topics of Vaccine, Mask, and Lockdown. Our experiments show that our method achieves an average topic-related keyword recall 2x higher than baselines. We open-source our code along with a web interface for keyword selection to make data collection from Twitter more systematic for researchers.