 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks
Dec 11, 2023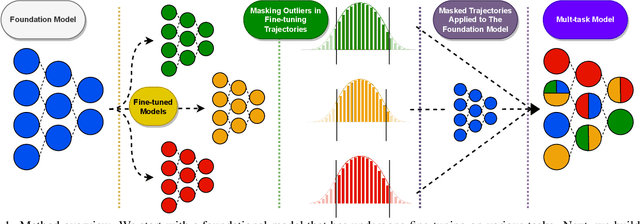

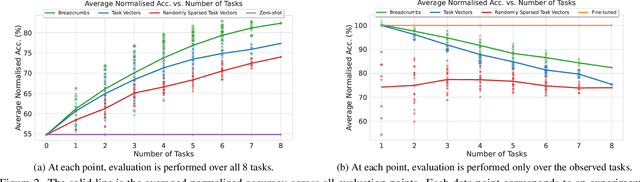
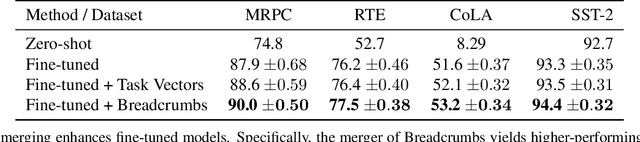
The rapid development of AI systems has been greatly influenced by the emergence of foundation models. A common approach for targeted problems involves fine-tuning these pre-trained foundation models for specific target tasks, resulting in a rapid spread of models fine-tuned across a diverse array of tasks. This work focuses on the problem of merging multiple fine-tunings of the same foundation model derived from a spectrum of auxiliary tasks. We introduce a new simple method, Model Breadcrumbs, which consists of a sparsely defined set of weights that carve out a trajectory within the weight space of a pre-trained model, enhancing task performance when traversed. These breadcrumbs are constructed by subtracting the weights from a pre-trained model before and after fine-tuning, followed by a sparsification process that eliminates weight outliers and negligible perturbations. Our experiments demonstrate the effectiveness of Model Breadcrumbs to simultaneously improve performance across multiple tasks. This contribution aligns with the evolving paradigm of updatable machine learning, reminiscent of the collaborative principles underlying open-source software development, fostering a community-driven effort to reliably update machine learning models. Our method is shown to be more efficient and unlike previous proposals does not require hyperparameter tuning for each new task added. Through extensive experimentation involving various models, tasks, and modalities we establish that integrating Model Breadcrumbs offers a simple, efficient, and highly effective approach for constructing multi-task models and facilitating updates to foundation models.
ToxBuster: In-game Chat Toxicity Buster with BERT
May 21, 2023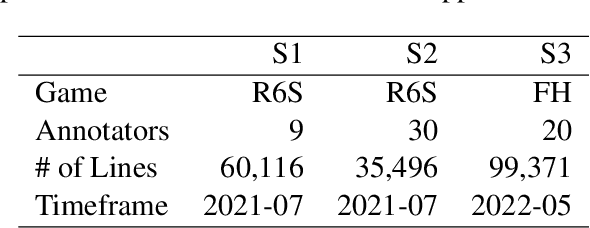
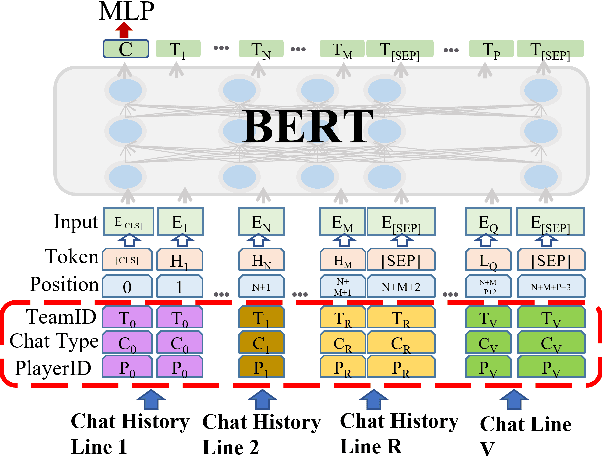
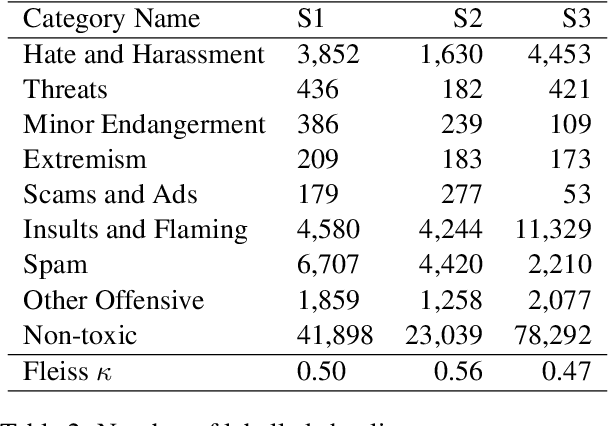
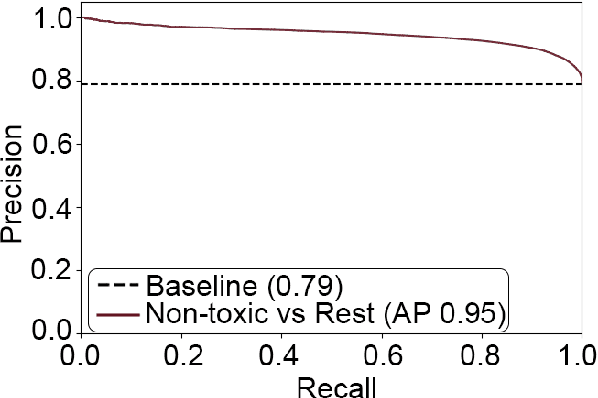
Detecting toxicity in online spaces is challenging and an ever more pressing problem given the increase in social media and gaming consumption. We introduce ToxBuster, a simple and scalable model trained on a relatively large dataset of 194k lines of game chat from Rainbow Six Siege and For Honor, carefully annotated for different kinds of toxicity. Compared to the existing state-of-the-art, ToxBuster achieves 82.95% (+7) in precision and 83.56% (+57) in recall. This improvement is obtained by leveraging past chat history and metadata. We also study the implication towards real-time and post-game moderation as well as the model transferability from one game to another.
Reliability of CKA as a Similarity Measure in Deep Learning
Nov 16, 2022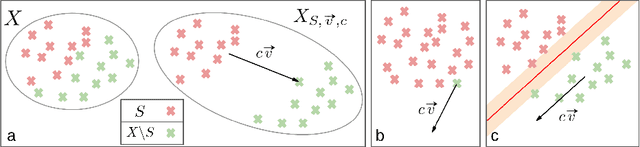

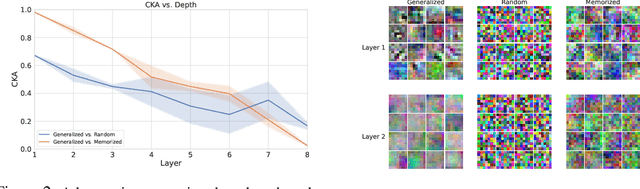
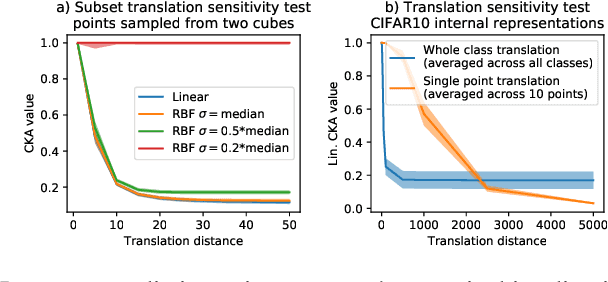
Comparing learned neural representations in neural networks is a challenging but important problem, which has been approached in different ways. The Centered Kernel Alignment (CKA) similarity metric, particularly its linear variant, has recently become a popular approach and has been widely used to compare representations of a network's different layers, of architecturally similar networks trained differently, or of models with different architectures trained on the same data. A wide variety of conclusions about similarity and dissimilarity of these various representations have been made using CKA. In this work we present analysis that formally characterizes CKA sensitivity to a large class of simple transformations, which can naturally occur in the context of modern machine learning. This provides a concrete explanation of CKA sensitivity to outliers, which has been observed in past works, and to transformations that preserve the linear separability of the data, an important generalization attribute. We empirically investigate several weaknesses of the CKA similarity metric, demonstrating situations in which it gives unexpected or counter-intuitive results. Finally we study approaches for modifying representations to maintain functional behaviour while changing the CKA value. Our results illustrate that, in many cases, the CKA value can be easily manipulated without substantial changes to the functional behaviour of the models, and call for caution when leveraging activation alignment metrics.
Probing Representation Forgetting in Supervised and Unsupervised Continual Learning
Apr 05, 2022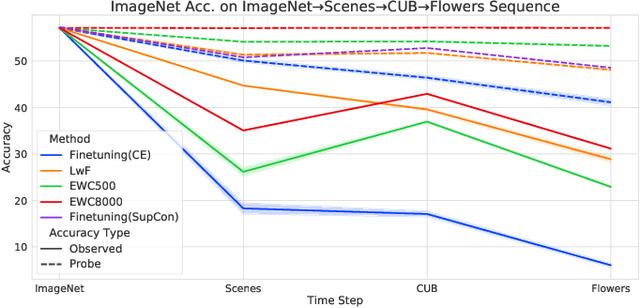
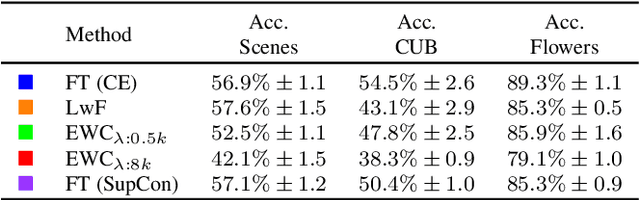
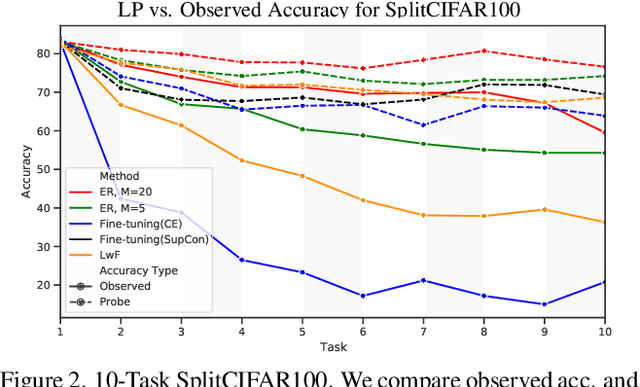
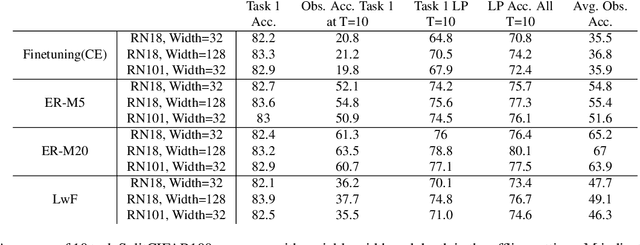
Continual Learning research typically focuses on tackling the phenomenon of catastrophic forgetting in neural networks. Catastrophic forgetting is associated with an abrupt loss of knowledge previously learned by a model when the task, or more broadly the data distribution, being trained on changes. In supervised learning problems this forgetting, resulting from a change in the model's representation, is typically measured or observed by evaluating the decrease in old task performance. However, a model's representation can change without losing knowledge about prior tasks. In this work we consider the concept of representation forgetting, observed by using the difference in performance of an optimal linear classifier before and after a new task is introduced. Using this tool we revisit a number of standard continual learning benchmarks and observe that, through this lens, model representations trained without any explicit control for forgetting often experience small representation forgetting and can sometimes be comparable to methods which explicitly control for forgetting, especially in longer task sequences. We also show that representation forgetting can lead to new insights on the effect of model capacity and loss function used in continual learning. Based on our results, we show that a simple yet competitive approach is to learn representations continually with standard supervised contrastive learning while constructing prototypes of class samples when queried on old samples.
Toponym Identification in Epidemiology Articles - A Deep Learning Approach
Apr 28, 2019
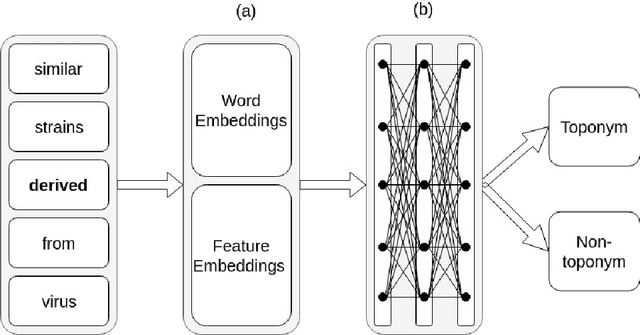

When analyzing the spread of viruses, epidemiologists often need to identify the location of infected hosts. This information can be found in public databases, such as GenBank, however, information provided in these databases are usually limited to the country or state level. More fine-grained localization information requires phylogeographers to manually read relevant scientific articles. In this work we propose an approach to automate the process of place name identification from medical (epidemiology) articles. The focus of this paper is to propose a deep learning based model for toponym detection and experiment with the use of external linguistic features and domain specific information. The model was evaluated using a collection of 105 epidemiology articles from PubMed Central provided by the recent SemEval task 12. Our best detection model achieves an F1 score of $80.13\%$, a significant improvement compared to the state of the art of $69.84\%$. These results underline the importance of domain specific embedding as well as specific linguistic features in toponym detection in medical journals.