 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes The Way You Plan Matter? An Empirical Study of Planning Representations for LLM Web Agents
May 28, 2026Despite recent advances, LLM-based web agents still struggle with limited exploration, omission of critical steps, and sensitivity to task constraints. Prior work suggests that many of these failures stem from weaknesses in planning, yet the impact of alternative natural language plan representation remains unexplored. To address this, we introduce PlanAhead, a static planner-executor framework that evaluates the impact of plan representation in agent performance. We first automatically categorize WebArena tasks into 3 difficulty levels, enabling consistent difficulty grading without human annotation. Then we systematically evaluate 4 different plan representations on the tasks categorized as hard: sequential subgoals, narrative, pseudocode, and checklist; across different families of multimodal LLM powered agents (OpenAI, Alibaba, and Google). To account for stochastic variability, we introduce two novel evaluation metrics: Achievement Rate (AR) and Solved-Task Consistency (STC). Our results show that both, the plan formulation and the underlying LLM generating the plan, significantly influence web-agent robustness and task success.
CLaC at SemEval-2026 Task 6: Response Clarity Detection in Political Discourse
May 04, 2026In this paper, we present our system for SemEval-2026 Task 6 (CLARITY) on response clarity and evasion detection in question-answer pairs from U.S. presidential interviews, comparing fine-tuned encoders with prompt-based LLMs. Our LLM ensemble achieves 80 macro-F1 on the 3-class Task 1 (9th/41) and 59 on the 9-class Task 2 (3rd/33). Across 8 transformer encoders optimized through a four-stage pipeline, partial encoder layer unfreezing outperforms full fine-tuning by a wide margin. Combining English and multilingual encoders further improves ensemble performance over either family alone, despite multilingual models being individually weaker. Prompt-based LLMs, without any task-specific parameter updates, outperform fine-tuned encoders, particularly on minority classes; among open-weight LLMs, parameter count does not predict performance. Enriched input, concatenating the full interviewer turn, improves LLM performance but not that of encoders, an effect that persists with Longformer's extended context window, suggesting the divergence is not attributable to sequence-length capacity alone in our settings. The Clear Reply/Ambivalent boundary remains the dominant failure mode, mirroring the disagreement among human annotators. Our code, prompts, model configurations, and results are publicly available.
On the Influence of Discourse Relations in Persuasive Texts
Oct 30, 2025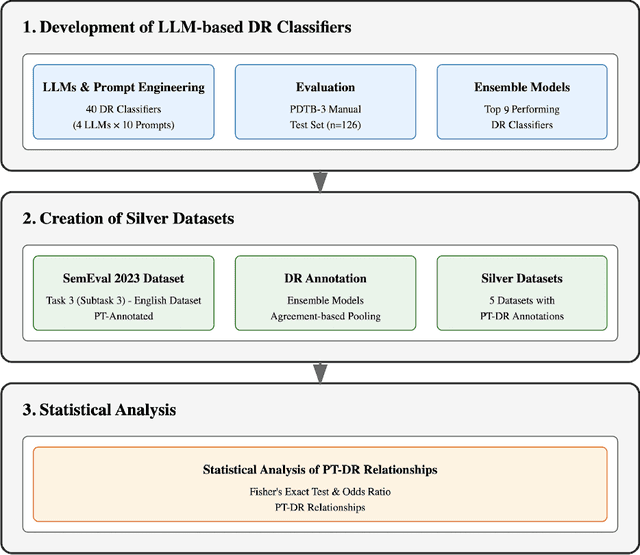
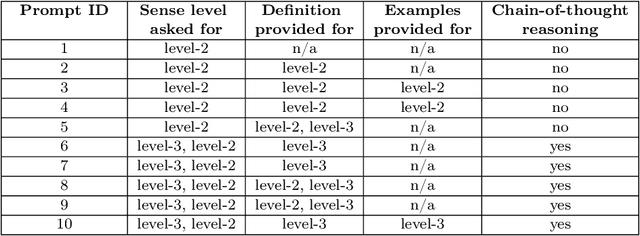


This paper investigates the relationship between Persuasion Techniques (PTs) and Discourse Relations (DRs) by leveraging Large Language Models (LLMs) and prompt engineering. Since no dataset annotated with both PTs and DRs exists, we took the SemEval 2023 Task 3 dataset labelled with 19 PTs as a starting point and developed LLM-based classifiers to label each instance of the dataset with one of the 22 PDTB 3.0 level-2 DRs. In total, four LLMs were evaluated using 10 different prompts, resulting in 40 unique DR classifiers. Ensemble models using different majority-pooling strategies were used to create 5 silver datasets of instances labelled with both persuasion techniques and level-2 PDTB senses. The silver dataset sizes vary from 1,281 instances to 204 instances, depending on the majority pooling technique used. Statistical analysis of these silver datasets shows that six discourse relations (namely Cause, Purpose, Contrast, Cause+Belief, Concession, and Condition) play a crucial role in persuasive texts, especially in the use of Loaded Language, Exaggeration/Minimisation, Repetition and to cast Doubt. This insight can contribute to detecting online propaganda and misinformation, as well as to our general understanding of effective communication.
* Published in Proceedings of the 38th Canadian Conference on Artificial Intelligence CanAI 2025 Calgary Alberta May 26-27 2025. 5 figures 7 tables
Low-Resource Dialect Adaptation of Large Language Models: A French Dialect Case-Study
Oct 26, 2025Despite the widespread adoption of large language models (LLMs), their strongest capabilities remain largely confined to a small number of high-resource languages for which there is abundant training data. Recently, continual pre-training (CPT) has emerged as a means to fine-tune these models to low-resource regional dialects. In this paper, we study the use of CPT for dialect learning under tight data and compute budgets. Using low-rank adaptation (LoRA) and compute-efficient continual pre-training, we adapt three LLMs to the Qu\'ebec French dialect using a very small dataset and benchmark them on the COLE suite. Our experiments demonstrate an improvement on the minority dialect benchmarks with minimal regression on the prestige language benchmarks with under 1% of model parameters updated. Analysis of the results demonstrate that gains are highly contingent on corpus composition. These findings indicate that CPT with parameter-efficient fine-tuning (PEFT) can narrow the dialect gap by providing cost-effective and sustainable language resource creation, expanding high-quality LLM access to minority linguistic communities. We release the first Qu\'ebec French LLMs on HuggingFace.
Multi-Lingual Implicit Discourse Relation Recognition with Multi-Label Hierarchical Learning
Aug 28, 2025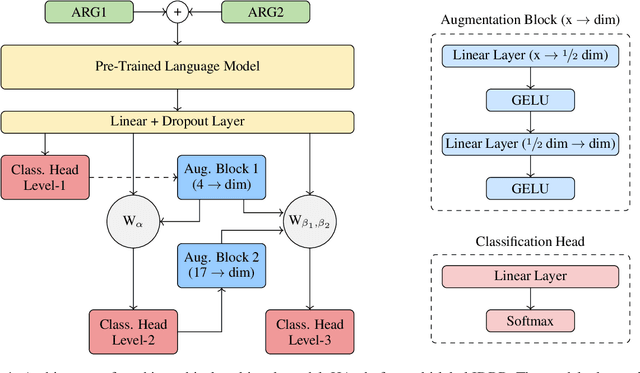
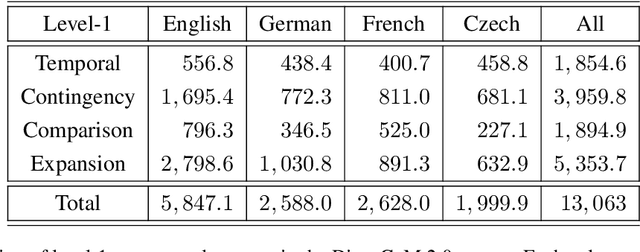
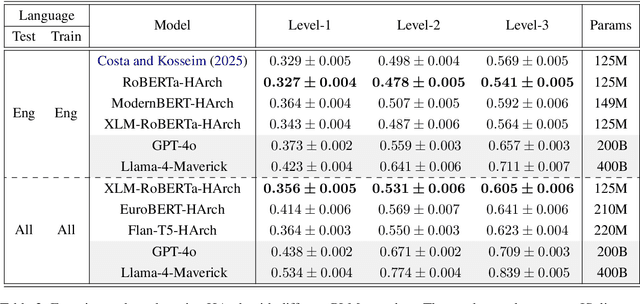

This paper introduces the first multi-lingual and multi-label classification model for implicit discourse relation recognition (IDRR). Our model, HArch, is evaluated on the recently released DiscoGeM 2.0 corpus and leverages hierarchical dependencies between discourse senses to predict probability distributions across all three sense levels in the PDTB 3.0 framework. We compare several pre-trained encoder backbones and find that RoBERTa-HArch achieves the best performance in English, while XLM-RoBERTa-HArch performs best in the multi-lingual setting. In addition, we compare our fine-tuned models against GPT-4o and Llama-4-Maverick using few-shot prompting across all language configurations. Our results show that our fine-tuned models consistently outperform these LLMs, highlighting the advantages of task-specific fine-tuning over prompting in IDRR. Finally, we report SOTA results on the DiscoGeM 1.0 corpus, further validating the effectiveness of our hierarchical approach.
CLaC at SemEval-2025 Task 6: A Multi-Architecture Approach for Corporate Environmental Promise Verification
May 29, 2025This paper presents our approach to the SemEval-2025 Task~6 (PromiseEval), which focuses on verifying promises in corporate ESG (Environmental, Social, and Governance) reports. We explore three model architectures to address the four subtasks of promise identification, supporting evidence assessment, clarity evaluation, and verification timing. Our first model utilizes ESG-BERT with task-specific classifier heads, while our second model enhances this architecture with linguistic features tailored for each subtask. Our third approach implements a combined subtask model with attention-based sequence pooling, transformer representations augmented with document metadata, and multi-objective learning. Experiments on the English portion of the ML-Promise dataset demonstrate progressive improvement across our models, with our combined subtask approach achieving a leaderboard score of 0.5268, outperforming the provided baseline of 0.5227. Our work highlights the effectiveness of linguistic feature extraction, attention pooling, and multi-objective learning in promise verification tasks, despite challenges posed by class imbalance and limited training data.
A Multi-Task and Multi-Label Classification Model for Implicit Discourse Relation Recognition
Aug 16, 2024



In this work, we address the inherent ambiguity in Implicit Discourse Relation Recognition (IDRR) by introducing a novel multi-task classification model capable of learning both multi-label and single-label representations of discourse relations. Leveraging the DiscoGeM corpus, we train and evaluate our model on both multi-label and traditional single-label classification tasks. To the best of our knowledge, our work presents the first truly multi-label classifier in IDRR, establishing a benchmark for multi-label classification and achieving SOTA results in single-label classification on DiscoGeM. Additionally, we evaluate our model on the PDTB 3.0 corpus for single-label classification without any prior exposure to its data. While the performance is below the current SOTA, our model demonstrates promising results indicating potential for effective transfer learning across both corpora.
Analyzing Persuasive Strategies in Meme Texts: A Fusion of Language Models with Paraphrase Enrichment
Jul 01, 2024



This paper describes our approach to hierarchical multi-label detection of persuasion techniques in meme texts. Our model, developed as a part of the recent SemEval task, is based on fine-tuning individual language models (BERT, XLM-RoBERTa, and mBERT) and leveraging a mean-based ensemble model in addition to dataset augmentation through paraphrase generation from ChatGPT. The scope of the study encompasses enhancing model performance through innovative training techniques and data augmentation strategies. The problem addressed is the effective identification and classification of multiple persuasive techniques in meme texts, a task complicated by the diversity and complexity of such content. The objective of the paper is to improve detection accuracy by refining model training methods and examining the impact of balanced versus unbalanced training datasets. Novelty in the results and discussion lies in the finding that training with paraphrases enhances model performance, yet a balanced training set proves more advantageous than a larger unbalanced one. Additionally, the analysis reveals the potential pitfalls of indiscriminate incorporation of paraphrases from diverse distributions, which can introduce substantial noise. Results with the SemEval 2024 data confirm these insights, demonstrating improved model efficacy with the proposed methods.
* 15 pages, 8 figures, 1 table, Proceedings of 5th International Conference on Natural Language Processing and Applications (NLPA 2024)
Deep Hedging with Market Impact
Feb 22, 2024



Dynamic hedging is the practice of periodically transacting financial instruments to offset the risk caused by an investment or a liability. Dynamic hedging optimization can be framed as a sequential decision problem; thus, Reinforcement Learning (RL) models were recently proposed to tackle this task. However, existing RL works for hedging do not consider market impact caused by the finite liquidity of traded instruments. Integrating such feature can be crucial to achieve optimal performance when hedging options on stocks with limited liquidity. In this paper, we propose a novel general market impact dynamic hedging model based on Deep Reinforcement Learning (DRL) that considers several realistic features such as convex market impacts, and impact persistence through time. The optimal policy obtained from the DRL model is analysed using several option hedging simulations and compared to commonly used procedures such as delta hedging. Results show our DRL model behaves better in contexts of low liquidity by, among others: 1) learning the extent to which portfolio rebalancing actions should be dampened or delayed to avoid high costs, 2) factoring in the impact of features not considered by conventional approaches, such as previous hedging errors through the portfolio value, and the underlying asset's drift (i.e. the magnitude of its expected return).
Toponym Identification in Epidemiology Articles - A Deep Learning Approach
Apr 28, 2019
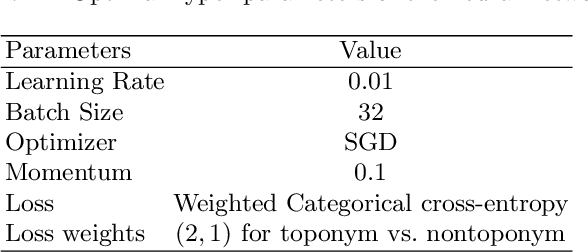
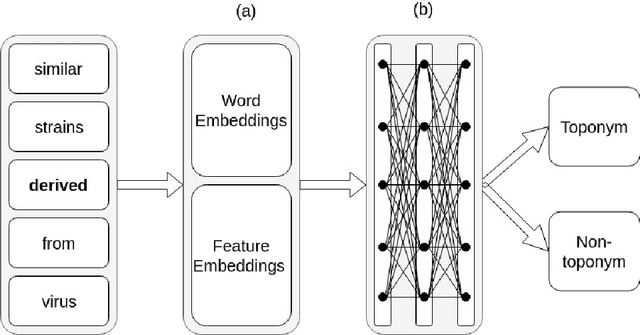

When analyzing the spread of viruses, epidemiologists often need to identify the location of infected hosts. This information can be found in public databases, such as GenBank, however, information provided in these databases are usually limited to the country or state level. More fine-grained localization information requires phylogeographers to manually read relevant scientific articles. In this work we propose an approach to automate the process of place name identification from medical (epidemiology) articles. The focus of this paper is to propose a deep learning based model for toponym detection and experiment with the use of external linguistic features and domain specific information. The model was evaluated using a collection of 105 epidemiology articles from PubMed Central provided by the recent SemEval task 12. Our best detection model achieves an F1 score of $80.13\%$, a significant improvement compared to the state of the art of $69.84\%$. These results underline the importance of domain specific embedding as well as specific linguistic features in toponym detection in medical journals.