 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Personalized AI Mentoring with Large Language Models in the Computing Field
Dec 11, 2024This paper provides an in-depth evaluation of three state-of-the-art Large Language Models (LLMs) for personalized career mentoring in the computing field, using three distinct student profiles that consider gender, race, and professional levels. We evaluated the performance of GPT-4, LLaMA 3, and Palm 2 using a zero-shot learning approach without human intervention. A quantitative evaluation was conducted through a custom natural language processing analytics pipeline to highlight the uniqueness of the responses and to identify words reflecting each student's profile, including race, gender, or professional level. The analysis of frequently used words in the responses indicates that GPT-4 offers more personalized mentoring compared to the other two LLMs. Additionally, a qualitative evaluation was performed to see if human experts reached similar conclusions. The analysis of survey responses shows that GPT-4 outperformed the other two LLMs in delivering more accurate and useful mentoring while addressing specific challenges with encouragement languages. Our work establishes a foundation for developing personalized mentoring tools based on LLMs, incorporating human mentors in the process to deliver a more impactful and tailored mentoring experience.
Measuring the Effect of Discourse Relations on Blog Summarization
Aug 19, 2017
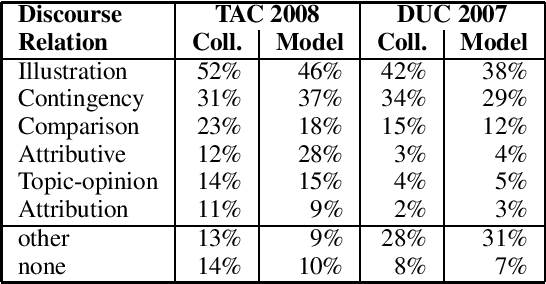

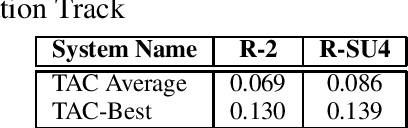
The work presented in this paper attempts to evaluate and quantify the use of discourse relations in the context of blog summarization and compare their use to more traditional and factual texts. Specifically, we measured the usefulness of 6 discourse relations - namely comparison, contingency, illustration, attribution, topic-opinion, and attributive for the task of text summarization from blogs. We have evaluated the effect of each relation using the TAC 2008 opinion summarization dataset and compared them with the results with the DUC 2007 dataset. The results show that in both textual genres, contingency, comparison, and illustration relations provide a significant improvement on summarization content; while attribution, topic-opinion, and attributive relations do not provide a consistent and significant improvement. These results indicate that, at least for summarization, discourse relations are just as useful for informal and affective texts as for more traditional news articles.