 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Learning not to Regret
Mar 02, 2023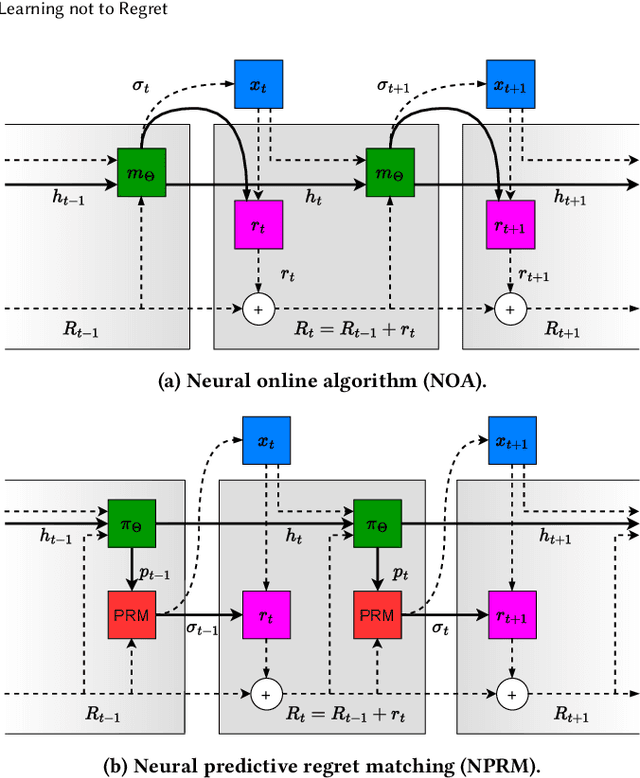
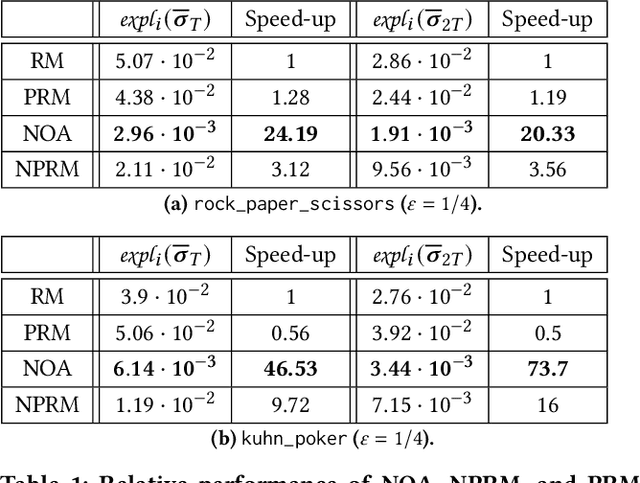
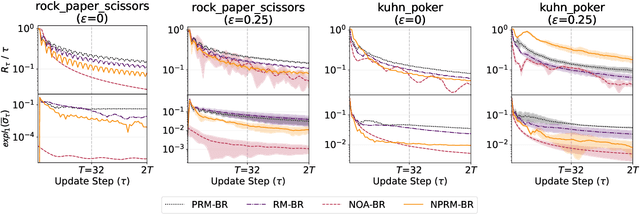
Regret minimization is a key component of many algorithms for finding Nash equilibria in imperfect-information games. To scale to games that cannot fit in memory, we can use search with value functions. However, calling the value functions repeatedly in search can be expensive. Therefore, it is desirable to minimize regret in the search tree as fast as possible. We propose to accelerate the regret minimization by introducing a general ``learning not to regret'' framework, where we meta-learn the regret minimizer. The resulting algorithm is guaranteed to minimize regret in arbitrary settings and is (meta)-learned to converge fast on a selected distribution of games. Our experiments show that meta-learned algorithms converge substantially faster than prior regret minimization algorithms.
Over-communicate no more: Situated RL agents learn concise communication protocols
Nov 02, 2022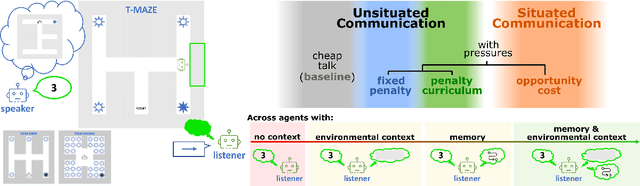
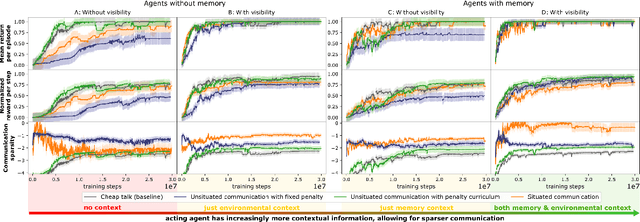
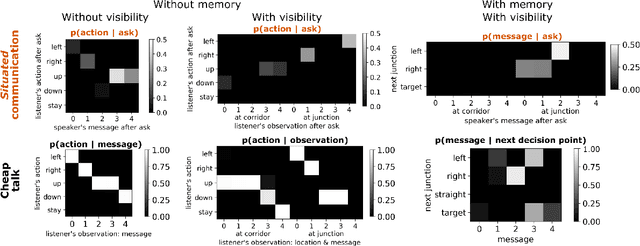
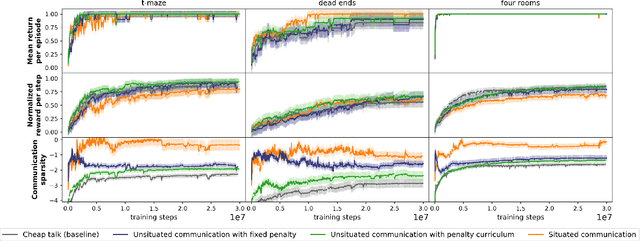
While it is known that communication facilitates cooperation in multi-agent settings, it is unclear how to design artificial agents that can learn to effectively and efficiently communicate with each other. Much research on communication emergence uses reinforcement learning (RL) and explores unsituated communication in one-step referential tasks -- the tasks are not temporally interactive and lack time pressures typically present in natural communication. In these settings, agents may successfully learn to communicate, but they do not learn to exchange information concisely -- they tend towards over-communication and an inefficient encoding. Here, we explore situated communication in a multi-step task, where the acting agent has to forgo an environmental action to communicate. Thus, we impose an opportunity cost on communication and mimic the real-world pressure of passing time. We compare communication emergence under this pressure against learning to communicate with a cost on articulation effort, implemented as a per-message penalty (fixed and progressively increasing). We find that while all tested pressures can disincentivise over-communication, situated communication does it most effectively and, unlike the cost on effort, does not negatively impact emergence. Implementing an opportunity cost on communication in a temporally extended environment is a step towards embodiment, and might be a pre-condition for incentivising efficient, human-like communication.
Rethinking Evaluation Practices in Visual Question Answering: A Case Study on Out-of-Distribution Generalization
May 24, 2022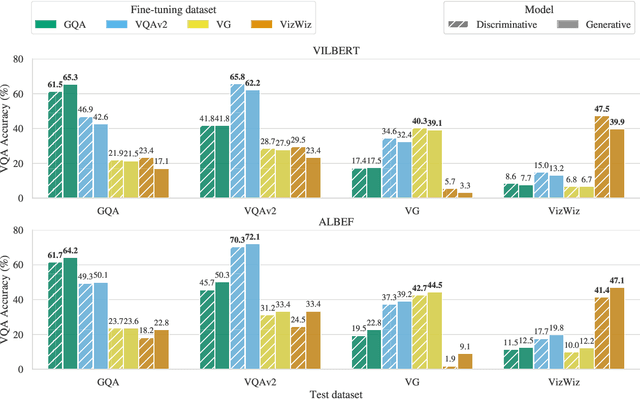
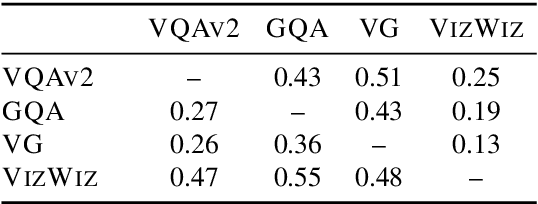
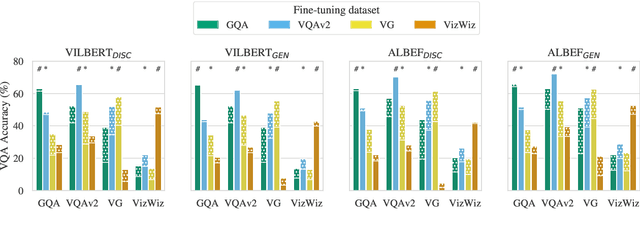
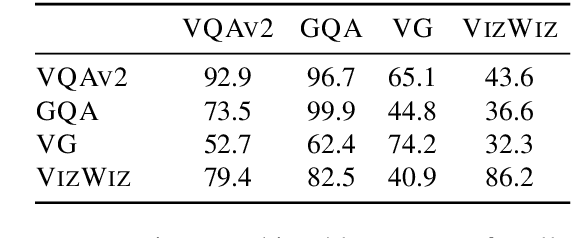
Vision-and-language (V&L) models pretrained on large-scale multimodal data have demonstrated strong performance on various tasks such as image captioning and visual question answering (VQA). The quality of such models is commonly assessed by measuring their performance on unseen data that typically comes from the same distribution as the training data. However, we observe that these models exhibit poor out-of-distribution (OOD) generalization on the task of VQA. To better understand the underlying causes of poor generalization, we comprehensively investigate performance of two pretrained V&L models under different settings (i.e. classification and open-ended text generation) by conducting cross-dataset evaluations. We find that these models tend to learn to solve the benchmark, rather than learning the high-level skills required by the VQA task. We also argue that in most cases generative models are less susceptible to shifts in data distribution, while frequently performing better on our tested benchmarks. Moreover, we find that multimodal pretraining improves OOD performance in most settings. Finally, we revisit assumptions underlying the use of automatic VQA evaluation metrics, and empirically show that their stringent nature repeatedly penalizes models for correct responses.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022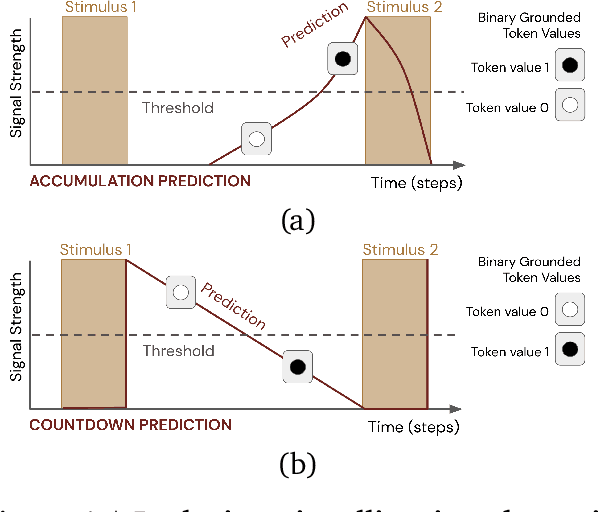

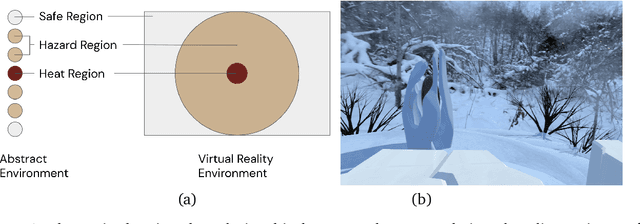
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
Pavlovian Signalling with General Value Functions in Agent-Agent Temporal Decision Making
Jan 11, 2022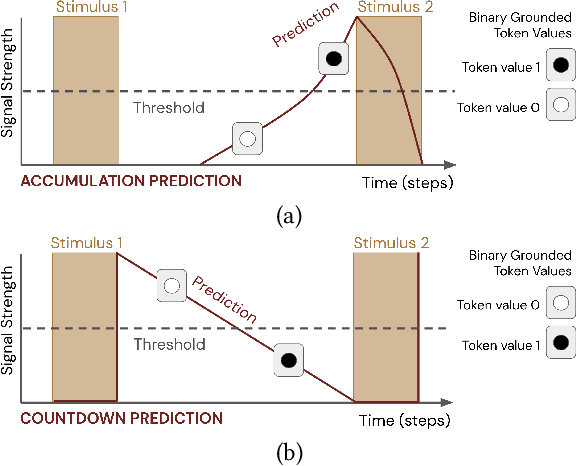
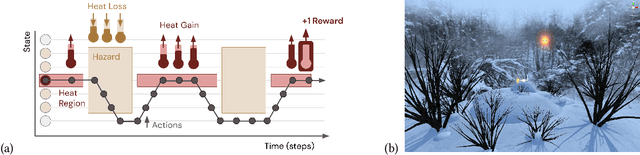
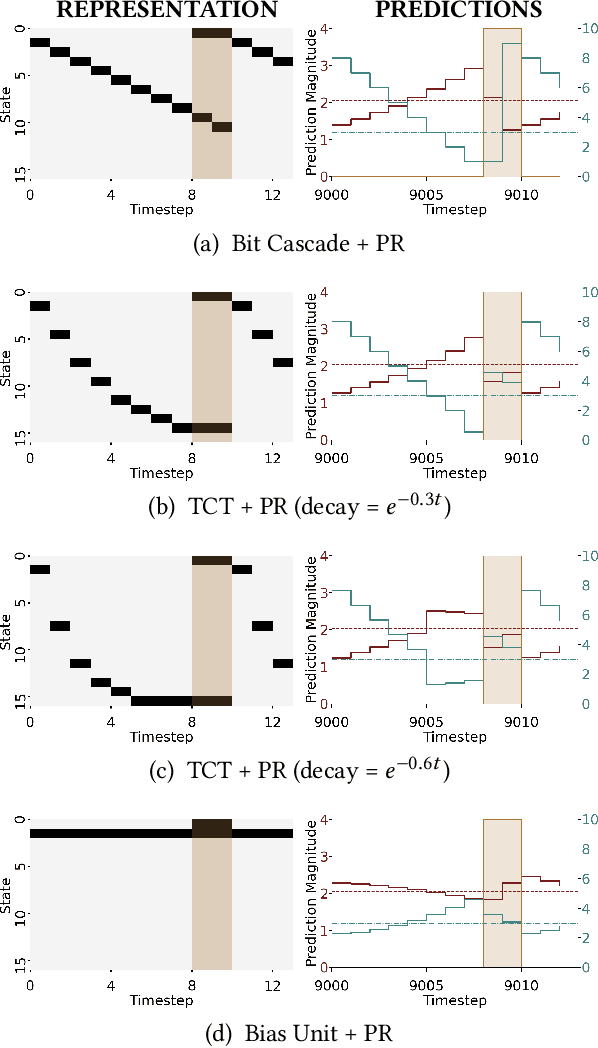
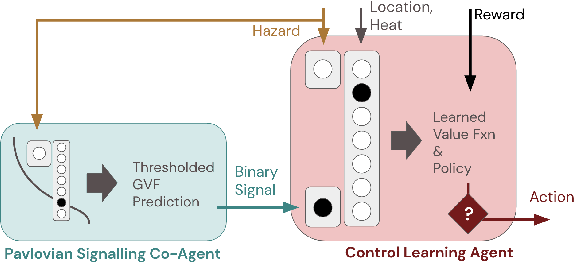
In this paper, we contribute a multi-faceted study into Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent. Signalling is intimately connected to time and timing. In service of generating and receiving signals, humans and other animals are known to represent time, determine time since past events, predict the time until a future stimulus, and both recognize and generate patterns that unfold in time. We investigate how different temporal processes impact coordination and signalling between learning agents by introducing a partially observable decision-making domain we call the Frost Hollow. In this domain, a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that works to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: machine agents interacting in a seven-state linear walk, and human-machine interaction in a virtual-reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning between two agents. We further show how to computationally build this adaptive signalling process out of a fixed signalling process, characterized by fast continual prediction learning and minimal constraints on the nature of the agent receiving signals. Our results therefore suggest an actionable, constructivist path towards communication learning between reinforcement learning agents.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021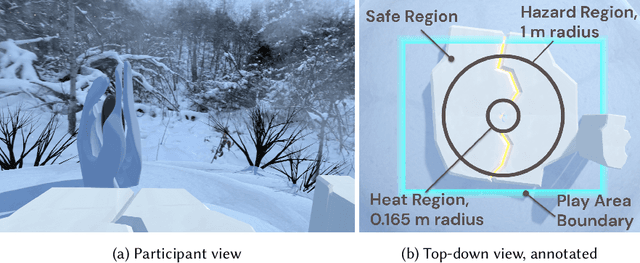
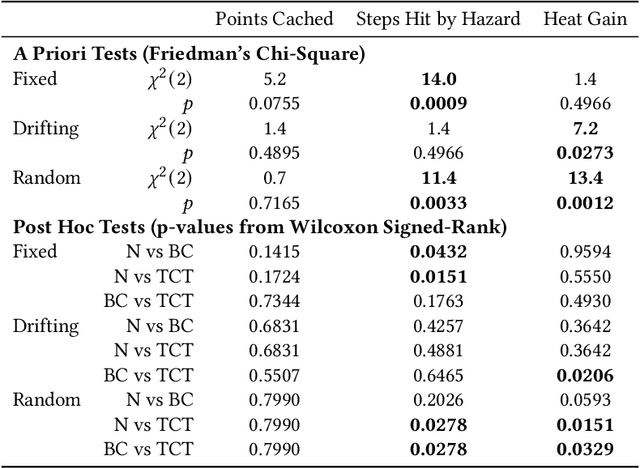
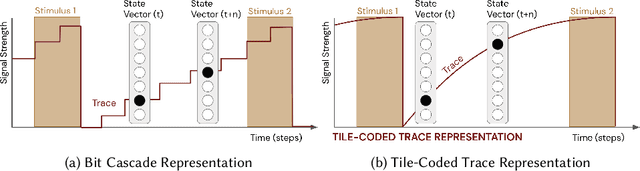
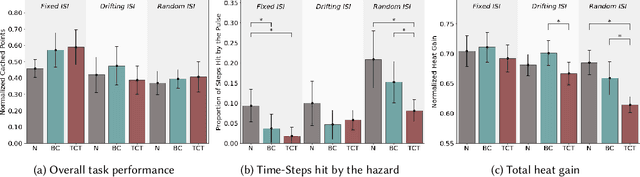
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .
Player of Games
Dec 06, 2021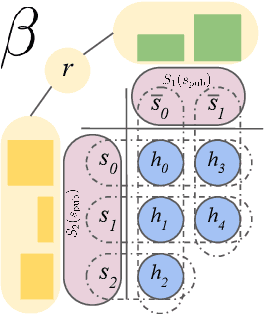

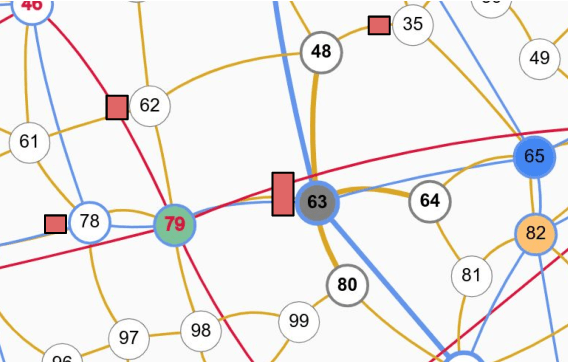
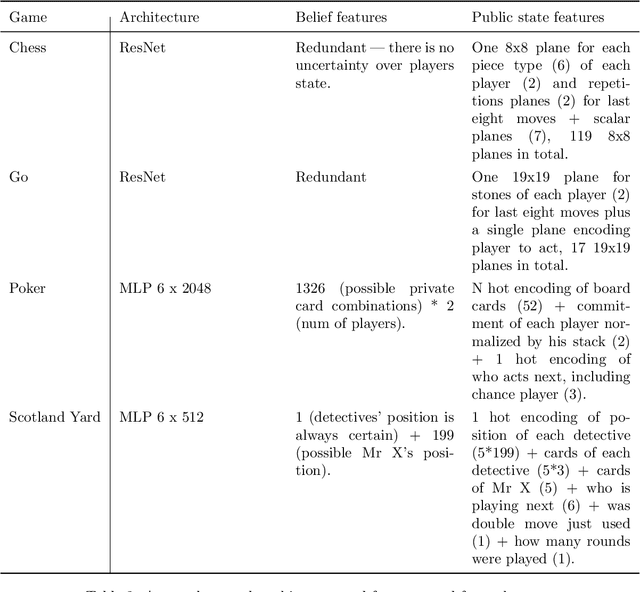
Games have a long history of serving as a benchmark for progress in artificial intelligence. Recently, approaches using search and learning have shown strong performance across a set of perfect information games, and approaches using game-theoretic reasoning and learning have shown strong performance for specific imperfect information poker variants. We introduce Player of Games, a general-purpose algorithm that unifies previous approaches, combining guided search, self-play learning, and game-theoretic reasoning. Player of Games is the first algorithm to achieve strong empirical performance in large perfect and imperfect information games -- an important step towards truly general algorithms for arbitrary environments. We prove that Player of Games is sound, converging to perfect play as available computation time and approximation capacity increases. Player of Games reaches strong performance in chess and Go, beats the strongest openly available agent in heads-up no-limit Texas hold'em poker (Slumbot), and defeats the state-of-the-art agent in Scotland Yard, an imperfect information game that illustrates the value of guided search, learning, and game-theoretic reasoning.
Solving Common-Payoff Games with Approximate Policy Iteration
Jan 11, 2021
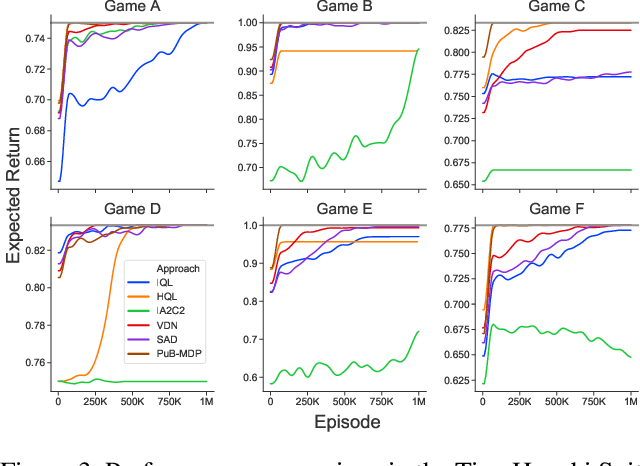
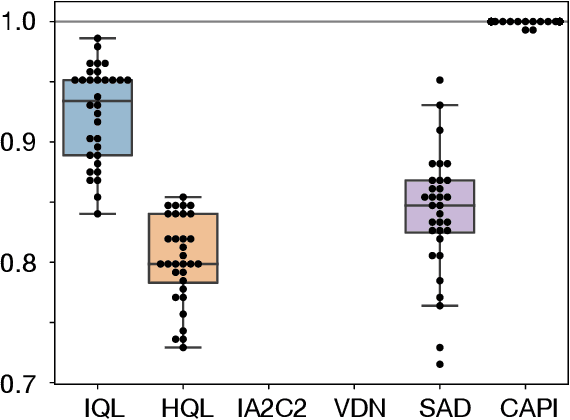
For artificially intelligent learning systems to have widespread applicability in real-world settings, it is important that they be able to operate decentrally. Unfortunately, decentralized control is difficult -- computing even an epsilon-optimal joint policy is a NEXP complete problem. Nevertheless, a recently rediscovered insight -- that a team of agents can coordinate via common knowledge -- has given rise to algorithms capable of finding optimal joint policies in small common-payoff games. The Bayesian action decoder (BAD) leverages this insight and deep reinforcement learning to scale to games as large as two-player Hanabi. However, the approximations it uses to do so prevent it from discovering optimal joint policies even in games small enough to brute force optimal solutions. This work proposes CAPI, a novel algorithm which, like BAD, combines common knowledge with deep reinforcement learning. However, unlike BAD, CAPI prioritizes the propensity to discover optimal joint policies over scalability. While this choice precludes CAPI from scaling to games as large as Hanabi, empirical results demonstrate that, on the games to which CAPI does scale, it is capable of discovering optimal joint policies even when other modern multi-agent reinforcement learning algorithms are unable to do so. Code is available at https://github.com/ssokota/capi .