 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-communicate no more: Situated RL agents learn concise communication protocols
Nov 02, 2022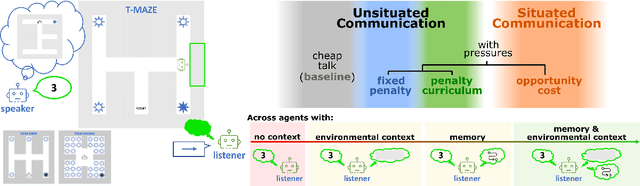
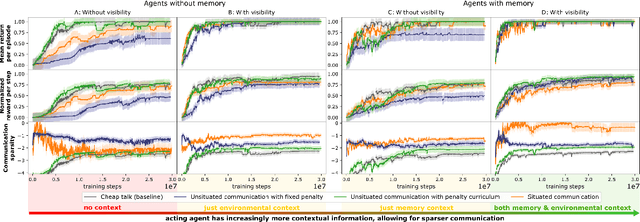
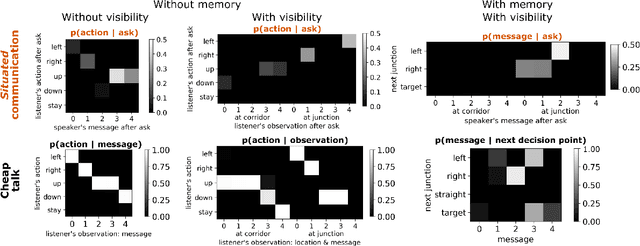
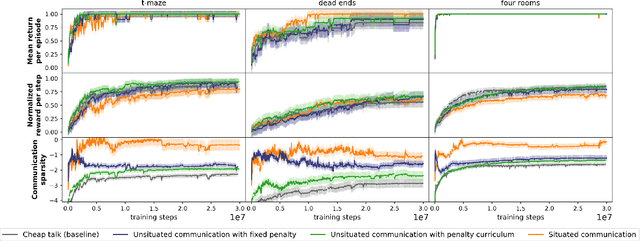
While it is known that communication facilitates cooperation in multi-agent settings, it is unclear how to design artificial agents that can learn to effectively and efficiently communicate with each other. Much research on communication emergence uses reinforcement learning (RL) and explores unsituated communication in one-step referential tasks -- the tasks are not temporally interactive and lack time pressures typically present in natural communication. In these settings, agents may successfully learn to communicate, but they do not learn to exchange information concisely -- they tend towards over-communication and an inefficient encoding. Here, we explore situated communication in a multi-step task, where the acting agent has to forgo an environmental action to communicate. Thus, we impose an opportunity cost on communication and mimic the real-world pressure of passing time. We compare communication emergence under this pressure against learning to communicate with a cost on articulation effort, implemented as a per-message penalty (fixed and progressively increasing). We find that while all tested pressures can disincentivise over-communication, situated communication does it most effectively and, unlike the cost on effort, does not negatively impact emergence. Implementing an opportunity cost on communication in a temporally extended environment is a step towards embodiment, and might be a pre-condition for incentivising efficient, human-like communication.
Ergodic imitation: Learning from what to do and what not to do
Mar 31, 2021
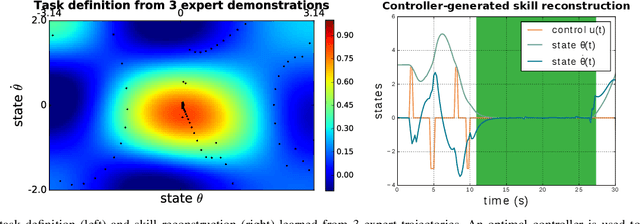
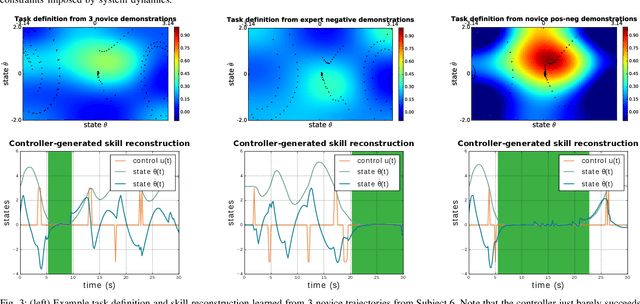
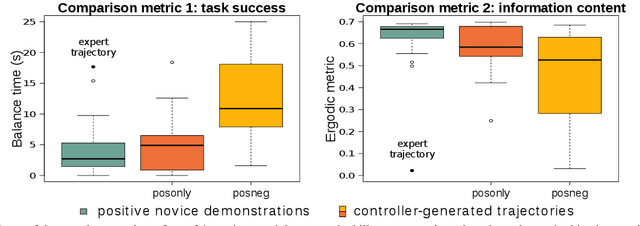
With growing access to versatile robotics, it is beneficial for end users to be able to teach robots tasks without needing to code a control policy. One possibility is to teach the robot through successful task executions. However, near-optimal demonstrations of a task can be difficult to provide and even successful demonstrations can fail to capture task aspects key to robust skill replication. Here, we propose a learning from demonstration (LfD) approach that enables learning of robust task definitions without the need for near-optimal demonstrations. We present a novel algorithmic framework for learning tasks based on the ergodic metric -- a measure of information content in motion. Moreover, we make use of negative demonstrations -- demonstrations of what not to do -- and show that they can help compensate for imperfect demonstrations, reduce the number of demonstrations needed, and highlight crucial task elements improving robot performance. In a proof-of-concept example of cart-pole inversion, we show that negative demonstrations alone can be sufficient to successfully learn and recreate a skill. Through a human subject study with 24 participants, we show that consistently more information about a task can be captured from combined positive and negative (posneg) demonstrations than from the same amount of just positive demonstrations. Finally, we demonstrate our learning approach on simulated tasks of target reaching and table cleaning with a 7-DoF Franka arm. Our results point towards a future with robust, data-efficient LfD for novice users.
* Kalinowska and Prabhakar contributed equally to this work
Task-Based Hybrid Shared Control for Training Through Forceful Interaction
Nov 18, 2019

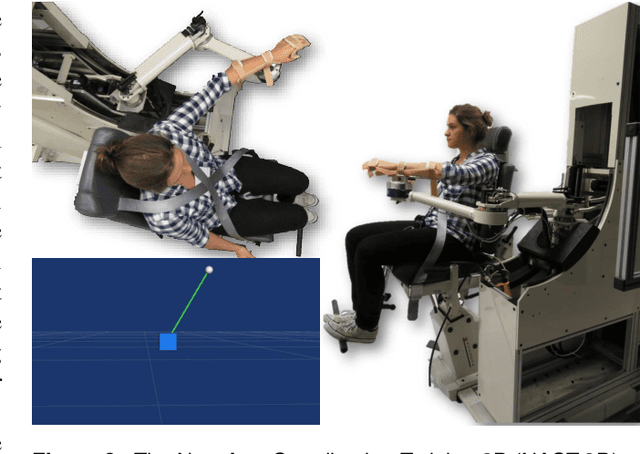
Despite the fact that robotic platforms can provide both consistent practice and objective assessments of users over the course of their training, there are relatively few instances where physical human robot interaction has been significantly more effective than unassisted practice or human-mediated training. This paper describes a hybrid shared control robot, which enhances task learning through kinesthetic feedback. The assistance assesses user actions using a task-specific evaluation criterion and selectively accepts or rejects them at each time instant. Through two human subject studies (total n=68), we show that this hybrid approach of switching between full transparency and full rejection of user inputs leads to increased skill acquisition and short-term retention compared to unassisted practice. Moreover, we show that the shared control paradigm exhibits features previously shown to promote successful training. It avoids user passivity by only rejecting user actions and allowing failure at the task. It improves performance during assistance, providing meaningful task-specific feedback. It is sensitive to initial skill of the user and behaves as an `assist-as-needed' control scheme---adapting its engagement in real time based on the performance and needs of the user. Unlike other successful algorithms, it does not require explicit modulation of the level of impedance or error amplification during training and it is permissive to a range of strategies because of its evaluation criterion. We demonstrate that the proposed hybrid shared control paradigm with a task-based minimal intervention criterion significantly enhances task-specific training.
Data-Driven Gait Segmentation for Walking Assistance in a Lower-Limb Assistive Device
Feb 28, 2019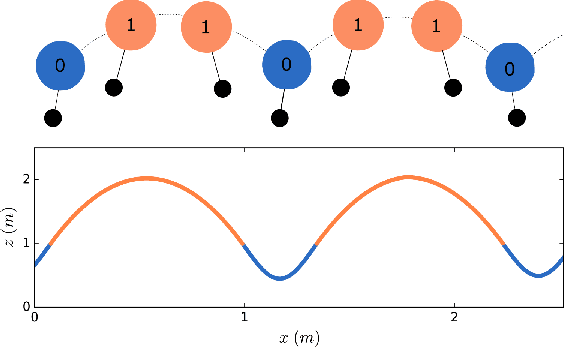
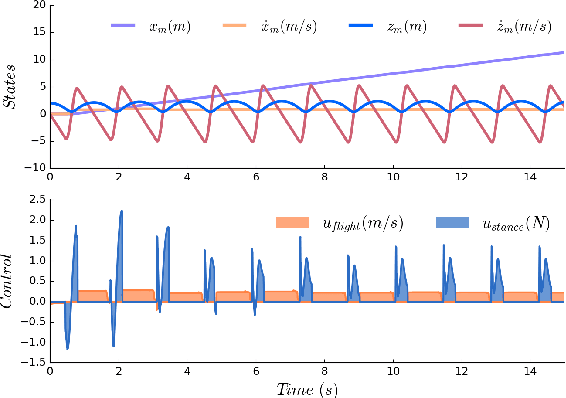

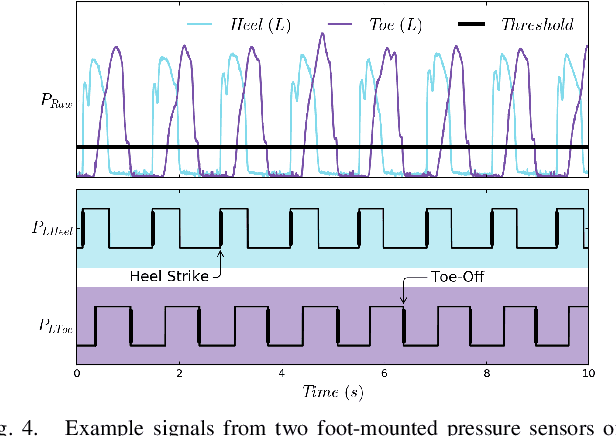
Hybrid systems, such as bipedal walkers, are challenging to control because of discontinuities in their nonlinear dynamics. Little can be predicted about the systems' evolution without modeling the guard conditions that govern transitions between hybrid modes, so even systems with reliable state sensing can be difficult to control. We propose an algorithm that allows for determining the hybrid mode of a system in real-time using data-driven analysis. The algorithm is used with data-driven dynamics identification to enable model predictive control based entirely on data. Two examples---a simulated hopper and experimental data from a bipedal walker---are used. In the context of the first example, we are able to closely approximate the dynamics of a hybrid SLIP model and then successfully use them for control in simulation. In the second example, we demonstrate gait partitioning of human walking data, accurately differentiating between stance and swing, as well as selected subphases of swing. We identify contact events, such as heel strike and toe-off, without a contact sensor using only kinematics data from the knee and hip joints, which could be particularly useful in providing online assistance during walking. Our algorithm does not assume a predefined gait structure or gait phase transitions, lending itself to segmentation of both healthy and pathological gaits. With this flexibility, impairment-specific rehabilitation strategies or assistance could be designed.
* 7 pages
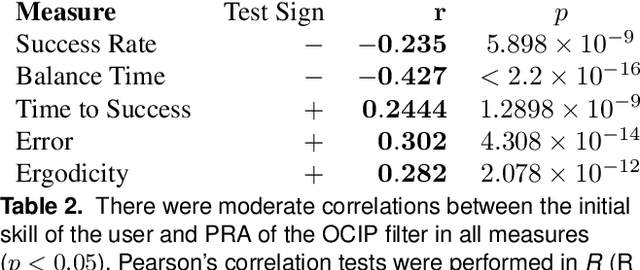
Online User Assessment for Minimal Intervention During Task-Based Robotic Assistance
Jun 06, 2018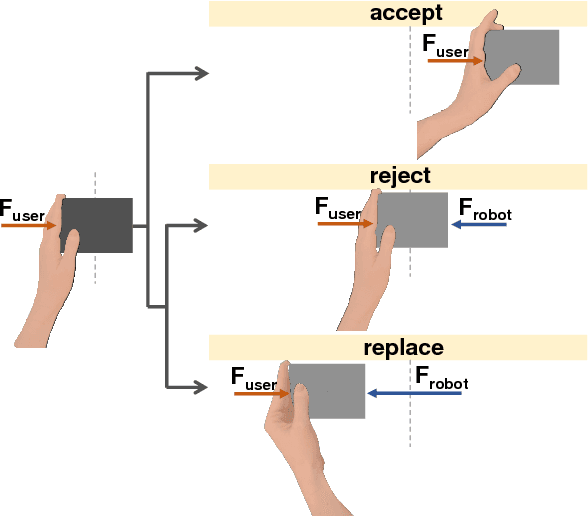
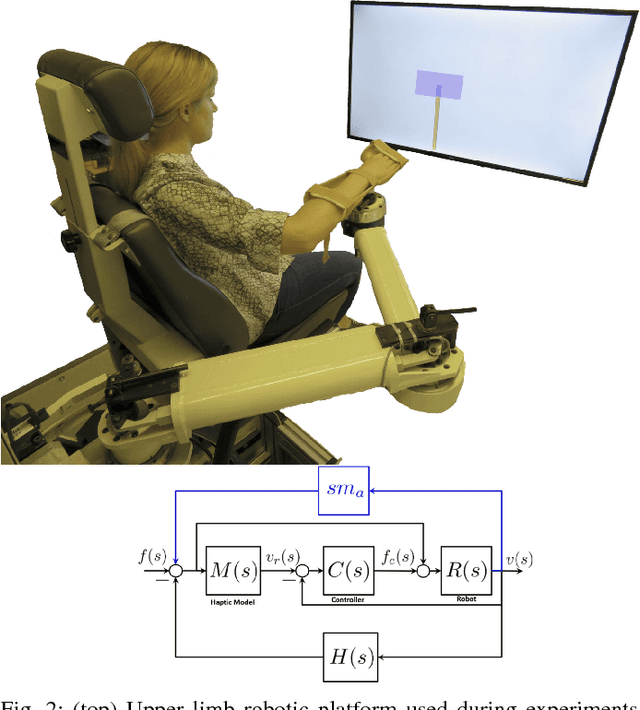
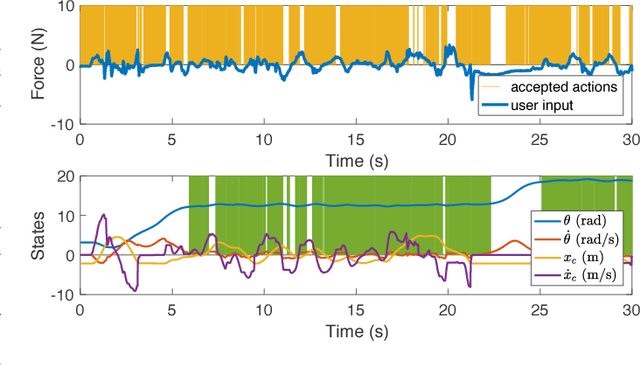
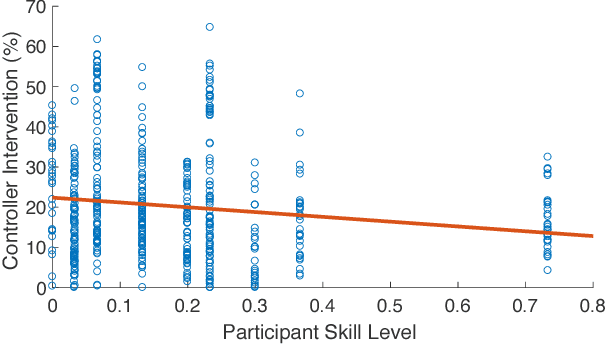
We propose a novel criterion for evaluating user input for human-robot interfaces for known tasks. We use the mode insertion gradient (MIG)---a tool from hybrid control theory---as a filtering criterion that instantaneously assesses the impact of user actions on a dynamic system over a time window into the future. As a result, the filter is permissive to many chosen strategies, minimally engaging, and skill-sensitive---qualities desired when evaluating human actions. Through a human study with 28 healthy volunteers, we show that the criterion exhibits a low, but significant, negative correlation between skill level, as estimated from task-specific measures in unassisted trials, and the rate of controller intervention during assistance. Moreover, a MIG-based filter can be utilized to create a shared control scheme for training or assistance. In the human study, we observe a substantial training effect when using a MIG-based filter to perform cart-pendulum inversion, particularly when comparing improvement via the RMS error measure. Using simulation of a controlled spring-loaded inverted pendulum (SLIP) as a test case, we observe that the MIG criterion could be used for assistance to guarantee either task completion or safety of a joint human-robot system, while maintaining the system's flexibility with respect to user-chosen strategies.
* 10 pages