 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Exploration for Real-Time Haptic Training
May 20, 2024Tactile perception is important for robotic systems that interact with the world through touch. Touch is an active sense in which tactile measurements depend on the contact properties of an interaction--e.g., velocity, force, acceleration--as well as properties of the sensor and object under test. These dependencies make training tactile perceptual models challenging. Additionally, the effects of limited sensor life and the near-field nature of tactile sensors preclude the practical collection of exhaustive data sets even for fairly simple objects. Active learning provides a mechanism for focusing on only the most informative aspects of an object during data collection. Here we employ an active learning approach that uses a data-driven model's entropy as an uncertainty measure and explore relative to that entropy conditioned on the sensor state variables. Using a coverage-based ergodic controller, we train perceptual models in near-real time. We demonstrate our approach using a biomimentic sensor, exploring "tactile scenes" composed of shapes, textures, and objects. Each learned representation provides a perceptual sensor model for a particular tactile scene. Models trained on actively collected data outperform their randomly collected counterparts in real-time training tests. Additionally, we find that the resulting network entropy maps can be used to identify high salience portions of a tactile scene.
Scale-Invariant Specifications for Human-Swarm Systems
Dec 12, 2022



We present a method for controlling a swarm using its spectral decomposition -- that is, by describing the set of trajectories of a swarm in terms of a spatial distribution throughout the operational domain -- guaranteeing scale invariance with respect to the number of agents both for computation and for the operator tasked with controlling the swarm. We use ergodic control, decentralized across the network, for implementation. In the DARPA OFFSET program field setting, we test this interface design for the operator using the STOMP interface -- the same interface used by Raytheon BBN throughout the duration of the OFFSET program. In these tests, we demonstrate that our approach is scale-invariant -- the user specification does not depend on the number of agents; it is persistent -- the specification remains active until the user specifies a new command; and it is real-time -- the user can interact with and interrupt the swarm at any time. Moreover, we show that the spectral/ergodic specification of swarm behavior degrades gracefully as the number of agents goes down, enabling the operator to maintain the same approach as agents become disabled or are added to the network. We demonstrate the scale-invariance and dynamic response of our system in a field relevant simulator on a variety of tactical scenarios with up to 50 agents. We also demonstrate the dynamic response of our system in the field with a smaller team of agents. Lastly, we make the code for our system available.
User-specific, Adaptable Safety Controllers Facilitate User Adoption in Human-Robot Collaboration
Oct 14, 2022
As assistive and collaborative robots become more ubiquitous in the real-world, we need to develop interfaces and controllers that are safe for users to build trust and encourage adoption. In this Blue Sky paper, we discuss the need for co-evolving task and user-specific safety controllers that can accommodate people's safety preferences. We argue that while most adaptive controllers focus on behavioral adaptation, safety adaptation is also a major consideration for building trust in collaborative systems. Furthermore, we highlight the need for adaptation over time, to account for user's changes in preferences as experience and trust builds. We provide a general formulation for what these interfaces should look like and what features are necessary for making them feasible and successful. In this formulation, users provide demonstrations and labelled safety ratings from which a safety value function is learned. These value functions can be updated by updating the safety labels on demonstrations to learn an updated function. We discuss how this can be implemented at a high-level, as well as some promising approaches and techniques for enabling this.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2022
Sep 28, 2022The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration on AI theory and methods aimed at HRI since 2014. This year, after a review of the achievements of the AI-HRI community over the last decade in 2021, we are focusing on a visionary theme: exploring the future of AI-HRI. Accordingly, we added a Blue Sky Ideas track to foster a forward-thinking discussion on future research at the intersection of AI and HRI. As always, we appreciate all contributions related to any topic on AI/HRI and welcome new researchers who wish to take part in this growing community. With the success of past symposia, AI-HRI impacts a variety of communities and problems, and has pioneered the discussions in recent trends and interests. This year's AI-HRI Fall Symposium aims to bring together researchers and practitioners from around the globe, representing a number of university, government, and industry laboratories. In doing so, we hope to accelerate research in the field, support technology transition and user adoption, and determine future directions for our group and our research.
Multimodal Sensory Learning for Real-time, Adaptive Manipulation
Oct 09, 2021
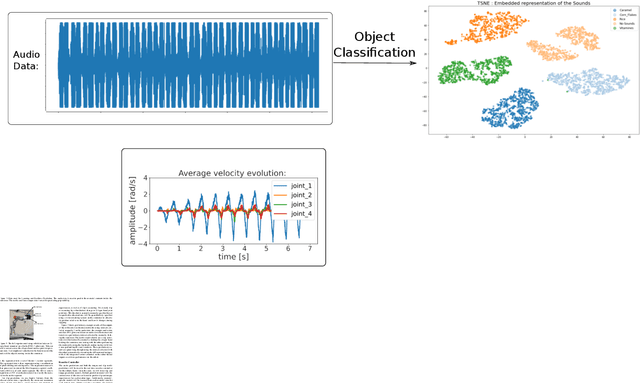

Adaptive control for real-time manipulation requires quick estimation and prediction of object properties. While robot learning in this area primarily focuses on using vision, many tasks cannot rely on vision due to object occlusion. Here, we formulate a learning framework that uses multimodal sensory fusion of tactile and audio data in order to quickly characterize and predict an object's properties. The predictions are used in a developed reactive controller to adapt the grip on the object to compensate for the predicted inertial forces experienced during motion. Drawing inspiration from how humans interact with objects, we propose an experimental setup from which we can understand how to best utilize different sensory signals and actively interact with and manipulate objects to quickly learn their object properties for safe manipulation.
Credit Assignment Safety Learning from Human Demonstrations
Oct 09, 2021


A critical need in assistive robotics, such as assistive wheelchairs for navigation, is a need to learn task intent and safety guarantees through user interactions in order to ensure safe task performance. For tasks where the objectives from the user are not easily defined, learning from user demonstrations has been a key step in enabling learning. However, most robot learning from demonstration (LfD) methods primarily rely on optimal demonstration in order to successfully learn a control policy, which can be challenging to acquire from novice users. Recent work does use suboptimal and failed demonstrations to learn about task intent; few focus on learning safety guarantees to prevent repeat failures experienced, essential for assistive robots. Furthermore, interactive human-robot learning aims to minimize effort from the human user to facilitate deployment in the real-world. As such, requiring users to label the unsafe states or keyframes from the demonstrations should not be a necessary requirement for learning. Here, we propose an algorithm to learn a safety value function from a set of suboptimal and failed demonstrations that is used to generate a real-time safety control filter. Importantly, we develop a credit assignment method that extracts the failure states from the failed demonstrations without requiring human labelling or prespecified knowledge of unsafe regions. Furthermore, we extend our formulation to allow for user-specific safety functions, by incorporating user-defined safety rankings from which we can generate safety level sets according to the users' preferences. By using both suboptimal and failed demonstrations and the developed credit assignment formulation, we enable learning a safety value function with minimal effort needed from the user, making it more feasible for widespread use in human-robot interactive learning tasks.
Ergodic imitation: Learning from what to do and what not to do
Mar 31, 2021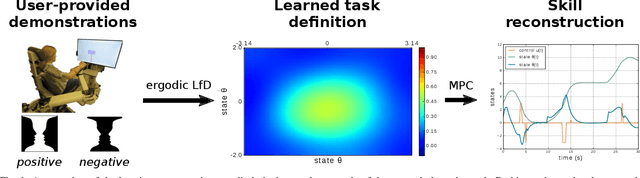
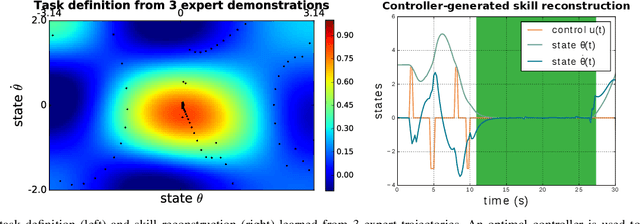
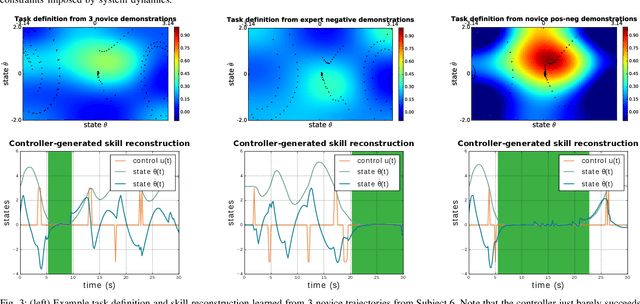
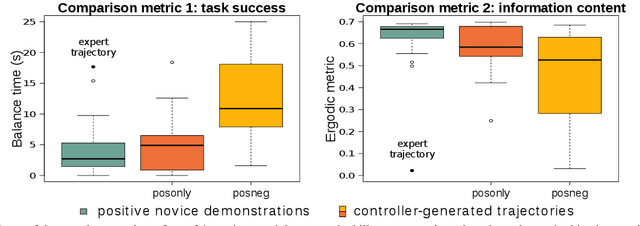
With growing access to versatile robotics, it is beneficial for end users to be able to teach robots tasks without needing to code a control policy. One possibility is to teach the robot through successful task executions. However, near-optimal demonstrations of a task can be difficult to provide and even successful demonstrations can fail to capture task aspects key to robust skill replication. Here, we propose a learning from demonstration (LfD) approach that enables learning of robust task definitions without the need for near-optimal demonstrations. We present a novel algorithmic framework for learning tasks based on the ergodic metric -- a measure of information content in motion. Moreover, we make use of negative demonstrations -- demonstrations of what not to do -- and show that they can help compensate for imperfect demonstrations, reduce the number of demonstrations needed, and highlight crucial task elements improving robot performance. In a proof-of-concept example of cart-pole inversion, we show that negative demonstrations alone can be sufficient to successfully learn and recreate a skill. Through a human subject study with 24 participants, we show that consistently more information about a task can be captured from combined positive and negative (posneg) demonstrations than from the same amount of just positive demonstrations. Finally, we demonstrate our learning approach on simulated tasks of target reaching and table cleaning with a 7-DoF Franka arm. Our results point towards a future with robust, data-efficient LfD for novice users.
* Kalinowska and Prabhakar contributed equally to this work
Ergodic Specifications for Flexible Swarm Control: From User Commands to Persistent Adaptation
Jun 10, 2020
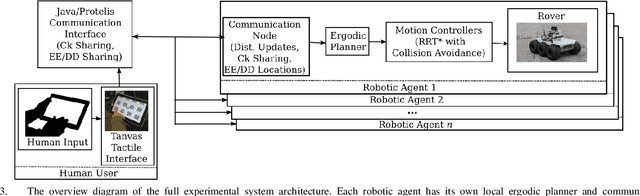
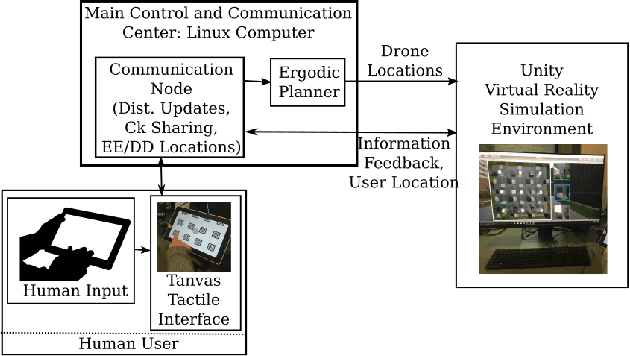

This paper presents a formulation for swarm control and high-level task planning that is dynamically responsive to user commands and adaptable to environmental changes. We design an end-to-end pipeline from a tactile tablet interface for user commands to onboard control of robotic agents based on decentralized ergodic coverage. Our approach demonstrates reliable and dynamic control of a swarm collective through the use of ergodic specifications for planning and executing agent trajectories as well as responding to user and external inputs. We validate our approach in a virtual reality simulation environment and in real-world experiments at the DARPA OFFSET Urban Swarm Challenge FX3 field tests with a robotic swarm where user-based control of the swarm and mission-based tasks require a dynamic and flexible response to changing conditions and objectives in real-time.
An Ergodic Measure for Active Learning From Equilibrium
Jun 05, 2020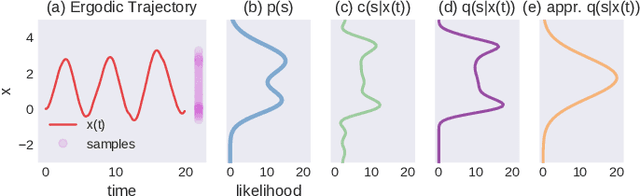

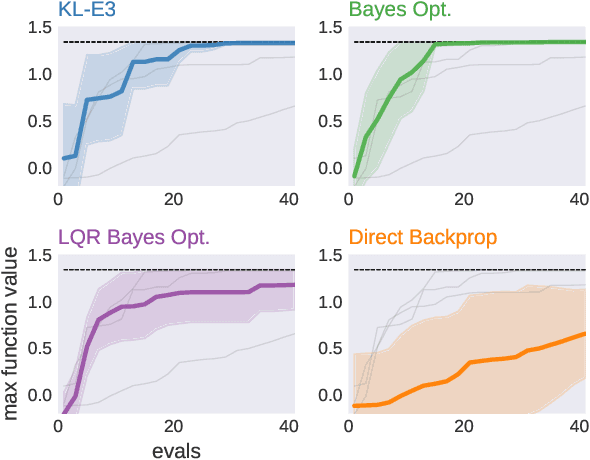
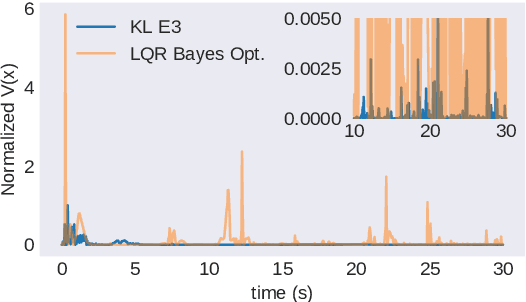
This paper develops KL-Ergodic Exploration from Equilibrium ($\text{KL-E}^3$), a method for robotic systems to integrate stability into actively generating informative measurements through ergodic exploration. Ergodic exploration enables robotic systems to indirectly sample from informative spatial distributions globally, avoiding local optima, and without the need to evaluate the derivatives of the distribution against the robot dynamics. Using hybrid systems theory, we derive a controller that allows a robot to exploit equilibrium policies (i.e., policies that solve a task) while allowing the robot to explore and generate informative data using an ergodic measure that can extend to high-dimensional states. We show that our method is able to maintain Lyapunov attractiveness with respect to the equilibrium task while actively generating data for learning tasks such, as Bayesian optimization, model learning, and off-policy reinforcement learning. In each example, we show that our proposed method is capable of generating an informative distribution of data while synthesizing smooth control signals. We illustrate these examples using simulated systems and provide simplification of our method for real-time online learning in robotic systems.
Active Area Coverage from Equilibrium
Feb 08, 2019



This paper develops a method for robots to integrate stability into actively seeking out informative measurements through coverage. We derive a controller using hybrid systems theory that allows us to consider safe equilibrium policies during active data collection. We show that our method is able to maintain Lyapunov attractiveness while still actively seeking out data. Using incremental sparse Gaussian processes, we define distributions which allow a robot to actively seek out informative measurements. We illustrate our methods for shape estimation using a cart double pendulum, dynamic model learning of a hovering quadrotor, and generating galloping gaits starting from stationary equilibrium by learning a dynamics model for the half-cheetah system from the Roboschool environment.
* 16 pages