 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManufacturing Micro-Patterned Surfaces with Multi-Robot Systems
Mar 18, 2026Applying micro-patterns to surfaces has been shown to impart useful physical properties such as drag reduction and hydrophobicity. However, current manufacturing techniques cannot produce micro-patterned surfaces at scale due to high-cost machinery and inefficient coverage techniques such as raster-scanning. In this work, we use multiple robots, each equipped with a patterning tool, to manufacture these surfaces. To allow these robots to coordinate during the patterning task, we use the ergodic control algorithm, which specifies coverage objectives using distributions. We demonstrate that robots can divide complicated coverage objectives by communicating compressed representations of their trajectory history both in simulations and experimental trials. Further, we show that robot-produced patterning can lower the coefficient of friction of metallic surfaces. This work demonstrates that distributed multi-robot systems can coordinate to manufacture products that were previously unrealizable at scale.
Sample-Efficient Online Control Policy Learning with Real-Time Recursive Model Updates
Sep 10, 2025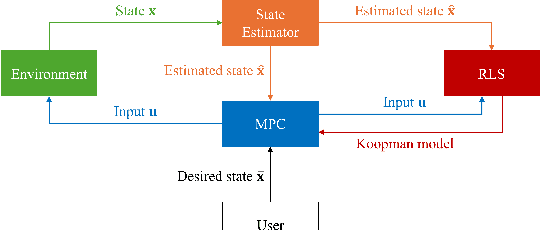



Data-driven control methods need to be sample-efficient and lightweight, especially when data acquisition and computational resources are limited -- such as during learning on hardware. Most modern data-driven methods require large datasets and struggle with real-time updates of models, limiting their performance in dynamic environments. Koopman theory formally represents nonlinear systems as linear models over observables, and Koopman representations can be determined from data in an optimization-friendly setting with potentially rapid model updates. In this paper, we present a highly sample-efficient, Koopman-based learning pipeline: Recursive Koopman Learning (RKL). We identify sufficient conditions for model convergence and provide formal algorithmic analysis supporting our claim that RKL is lightweight and fast, with complexity independent of dataset size. We validate our method on a simulated planar two-link arm and a hybrid nonlinear hardware system with soft actuators, showing that real-time recursive Koopman model updates improve the sample efficiency and stability of data-driven controller synthesis -- requiring only <10% of the data compared to benchmarks. The high-performance C++ codebase is open-sourced. Website: https://www.zixinatom990.com/home/robotics/corl-2025-recursive-koopman-learning.
Force and Speed in a Soft Stewart Platform
Apr 18, 2025



Many soft robots struggle to produce dynamic motions with fast, large displacements. We develop a parallel 6 degree-of-freedom (DoF) Stewart-Gough mechanism using Handed Shearing Auxetic (HSA) actuators. By using soft actuators, we are able to use one third as many mechatronic components as a rigid Stewart platform, while retaining a working payload of 2kg and an open-loop bandwidth greater than 16Hz. We show that the platform is capable of both precise tracing and dynamic disturbance rejection when controlling a ball and sliding puck using a Proportional Integral Derivative (PID) controller. We develop a machine-learning-based kinematics model and demonstrate a functional workspace of roughly 10cm in each translation direction and 28 degrees in each orientation. This 6DoF device has many of the characteristics associated with rigid components - power, speed, and total workspace - while capturing the advantages of soft mechanisms.
Data Augmentation for NeRFs in the Low Data Limit
Mar 03, 2025



Current methods based on Neural Radiance Fields fail in the low data limit, particularly when training on incomplete scene data. Prior works augment training data only in next-best-view applications, which lead to hallucinations and model collapse with sparse data. In contrast, we propose adding a set of views during training by rejection sampling from a posterior uncertainty distribution, generated by combining a volumetric uncertainty estimator with spatial coverage. We validate our results on partially observed scenes; on average, our method performs 39.9% better with 87.5% less variability across established scene reconstruction benchmarks, as compared to state of the art baselines. We further demonstrate that augmenting the training set by sampling from any distribution leads to better, more consistent scene reconstruction in sparse environments. This work is foundational for robotic tasks where augmenting a dataset with informative data is critical in resource-constrained, a priori unknown environments. Videos and source code are available at https://murpheylab.github.io/low-data-nerf/.
Embodied Active Learning of Generative Sensor-Object Models
Oct 14, 2024When a robot encounters a novel object, how should it respond$\unicode{x2014}$what data should it collect$\unicode{x2014}$so that it can find the object in the future? In this work, we present a method for learning image features of an unknown number of novel objects. To do this, we use active coverage with respect to latent uncertainties of the novel descriptions. We apply ergodic stability and PAC-Bayes theory to extend statistical guarantees for VAEs to embodied agents. We demonstrate the method in hardware with a robotic arm; the pipeline is also implemented in a simulated environment. Algorithms and simulation are available open source, see http://sites.google.com/u.northwestern.edu/embodied-learning-hardware .
Active Exploration for Real-Time Haptic Training
May 20, 2024Tactile perception is important for robotic systems that interact with the world through touch. Touch is an active sense in which tactile measurements depend on the contact properties of an interaction--e.g., velocity, force, acceleration--as well as properties of the sensor and object under test. These dependencies make training tactile perceptual models challenging. Additionally, the effects of limited sensor life and the near-field nature of tactile sensors preclude the practical collection of exhaustive data sets even for fairly simple objects. Active learning provides a mechanism for focusing on only the most informative aspects of an object during data collection. Here we employ an active learning approach that uses a data-driven model's entropy as an uncertainty measure and explore relative to that entropy conditioned on the sensor state variables. Using a coverage-based ergodic controller, we train perceptual models in near-real time. We demonstrate our approach using a biomimentic sensor, exploring "tactile scenes" composed of shapes, textures, and objects. Each learned representation provides a perceptual sensor model for a particular tactile scene. Models trained on actively collected data outperform their randomly collected counterparts in real-time training tests. Additionally, we find that the resulting network entropy maps can be used to identify high salience portions of a tactile scene.
Automated Gait Generation For Walking, Soft Robotic Quadrupeds
Oct 07, 2023

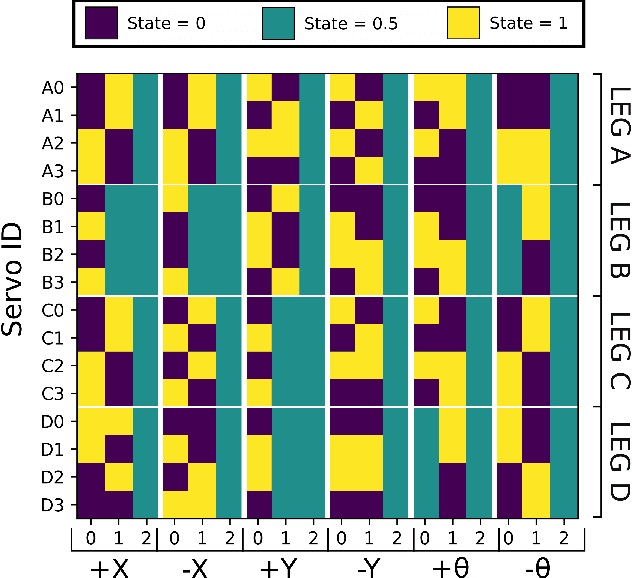
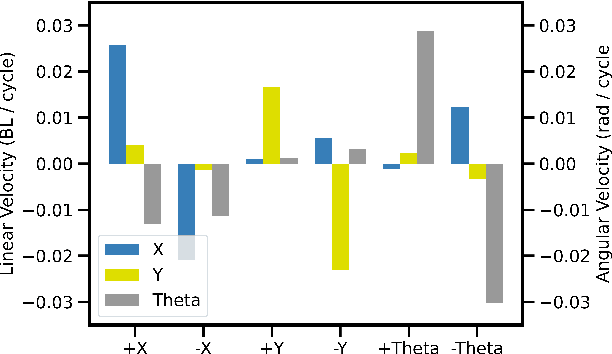
Gait generation for soft robots is challenging due to the nonlinear dynamics and high dimensional input spaces of soft actuators. Limitations in soft robotic control and perception force researchers to hand-craft open loop controllers for gait sequences, which is a non-trivial process. Moreover, short soft actuator lifespans and natural variations in actuator behavior limit machine learning techniques to settings that can be learned on the same time scales as robot deployment. Lastly, simulation is not always possible, due to heterogeneity and nonlinearity in soft robotic materials and their dynamics change due to wear. We present a sample-efficient, simulation free, method for self-generating soft robot gaits, using very minimal computation. This technique is demonstrated on a motorized soft robotic quadruped that walks using four legs constructed from 16 "handed shearing auxetic" (HSA) actuators. To manage the dimension of the search space, gaits are composed of two sequential sets of leg motions selected from 7 possible primitives. Pairs of primitives are executed on one leg at a time; we then select the best-performing pair to execute while moving on to subsequent legs. This method -- which uses no simulation, sophisticated computation, or user input -- consistently generates good translation and rotation gaits in as low as 4 minutes of hardware experimentation, outperforming hand-crafted gaits. This is the first demonstration of completely autonomous gait generation in a soft robot.
Maximum Diffusion Reinforcement Learning
Sep 28, 2023The assumption that data are independent and identically distributed underpins all machine learning. When data are collected sequentially from agent experiences this assumption does not generally hold, as in reinforcement learning. Here, we derive a method that overcomes these limitations by exploiting the statistical mechanics of ergodic processes, which we term maximum diffusion reinforcement learning. By decorrelating agent experiences, our approach provably enables agents to learn continually in single-shot deployments regardless of how they are initialized. Moreover, we prove our approach generalizes well-known maximum entropy techniques, and show that it robustly exceeds state-of-the-art performance across popular benchmarks. Our results at the nexus of physics, learning, and control pave the way towards more transparent and reliable decision-making in reinforcement learning agents, such as locomoting robots and self-driving cars.
A Game Benchmark for Real-Time Human-Swarm Control
Oct 28, 2022



We present a game benchmark for testing human-swarm control algorithms and interfaces in a real-time, high-cadence scenario. Our benchmark consists of a swarm vs. swarm game in a virtual ROS environment in which the goal of the game is to capture all agents from the opposing swarm; the game's high-cadence is a result of the capture rules, which cause agent team sizes to fluctuate rapidly. These rules require players to consider both the number of agents currently at their disposal and the behavior of their opponent's swarm when they plan actions. We demonstrate our game benchmark with a default human-swarm control system that enables a player to interact with their swarm through a high-level touchscreen interface. The touchscreen interface transforms player gestures into swarm control commands via a low-level decentralized ergodic control framework. We compare our default human-swarm control system to a flocking-based control system, and discuss traits that are crucial for swarm control algorithms and interfaces operating in real-time, high-cadence scenarios like our game benchmark. Our game benchmark code is available on Github; more information can be found at https://sites.google.com/view/swarm-game-benchmark.
Active Learning in Robotics: A Review of Control Principles
Jun 25, 2021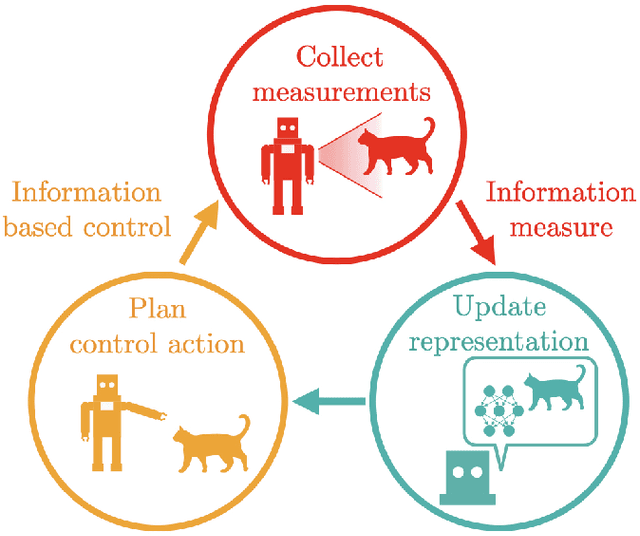
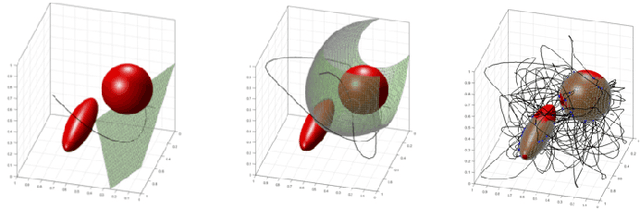

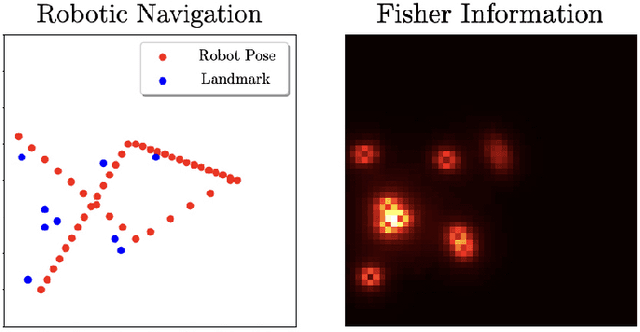
Active learning is a decision-making process. In both abstract and physical settings, active learning demands both analysis and action. This is a review of active learning in robotics, focusing on methods amenable to the demands of embodied learning systems. Robots must be able to learn efficiently and flexibly through continuous online deployment. This poses a distinct set of control-oriented challenges -- one must choose suitable measures as objectives, synthesize real-time control, and produce analyses that guarantee performance and safety with limited knowledge of the environment or robot itself. In this work, we survey the fundamental components of robotic active learning systems. We discuss classes of learning tasks that robots typically encounter, measures with which they gauge the information content of observations, and algorithms for generating action plans. Moreover, we provide a variety of examples -- from environmental mapping to nonparametric shape estimation -- that highlight the qualitative differences between learning tasks, information measures, and control techniques. We conclude with a discussion of control-oriented open challenges, including safety-constrained learning and distributed learning.
* 25 pages