 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Matching Ergodic Coverage
Apr 24, 2025Ergodic coverage effectively generates exploratory behaviors for embodied agents by aligning the spatial distribution of the agent's trajectory with a target distribution, where the difference between these two distributions is measured by the ergodic metric. However, existing ergodic coverage methods are constrained by the limited set of ergodic metrics available for control synthesis, fundamentally limiting their performance. In this work, we propose an alternative approach to ergodic coverage based on flow matching, a technique widely used in generative inference for efficient and scalable sampling. We formally derive the flow matching problem for ergodic coverage and show that it is equivalent to a linear quadratic regulator problem with a closed-form solution. Our formulation enables alternative ergodic metrics from generative inference that overcome the limitations of existing ones. These metrics were previously infeasible for control synthesis but can now be supported with no computational overhead. Specifically, flow matching with the Stein variational gradient flow enables control synthesis directly over the score function of the target distribution, improving robustness to the unnormalized distributions; on the other hand, flow matching with the Sinkhorn divergence flow enables an optimal transport-based ergodic metric, improving coverage performance on non-smooth distributions with irregular supports. We validate the improved performance and competitive computational efficiency of our method through comprehensive numerical benchmarks and across different nonlinear dynamics. We further demonstrate the practicality of our method through a series of drawing and erasing tasks on a Franka robot.
Embodied Active Learning of Generative Sensor-Object Models
Oct 14, 2024When a robot encounters a novel object, how should it respond$\unicode{x2014}$what data should it collect$\unicode{x2014}$so that it can find the object in the future? In this work, we present a method for learning image features of an unknown number of novel objects. To do this, we use active coverage with respect to latent uncertainties of the novel descriptions. We apply ergodic stability and PAC-Bayes theory to extend statistical guarantees for VAEs to embodied agents. We demonstrate the method in hardware with a robotic arm; the pipeline is also implemented in a simulated environment. Algorithms and simulation are available open source, see http://sites.google.com/u.northwestern.edu/embodied-learning-hardware .
Maximum Diffusion Reinforcement Learning
Sep 28, 2023The assumption that data are independent and identically distributed underpins all machine learning. When data are collected sequentially from agent experiences this assumption does not generally hold, as in reinforcement learning. Here, we derive a method that overcomes these limitations by exploiting the statistical mechanics of ergodic processes, which we term maximum diffusion reinforcement learning. By decorrelating agent experiences, our approach provably enables agents to learn continually in single-shot deployments regardless of how they are initialized. Moreover, we prove our approach generalizes well-known maximum entropy techniques, and show that it robustly exceeds state-of-the-art performance across popular benchmarks. Our results at the nexus of physics, learning, and control pave the way towards more transparent and reliable decision-making in reinforcement learning agents, such as locomoting robots and self-driving cars.
Scale-Invariant Specifications for Human-Swarm Systems
Dec 12, 2022



We present a method for controlling a swarm using its spectral decomposition -- that is, by describing the set of trajectories of a swarm in terms of a spatial distribution throughout the operational domain -- guaranteeing scale invariance with respect to the number of agents both for computation and for the operator tasked with controlling the swarm. We use ergodic control, decentralized across the network, for implementation. In the DARPA OFFSET program field setting, we test this interface design for the operator using the STOMP interface -- the same interface used by Raytheon BBN throughout the duration of the OFFSET program. In these tests, we demonstrate that our approach is scale-invariant -- the user specification does not depend on the number of agents; it is persistent -- the specification remains active until the user specifies a new command; and it is real-time -- the user can interact with and interrupt the swarm at any time. Moreover, we show that the spectral/ergodic specification of swarm behavior degrades gracefully as the number of agents goes down, enabling the operator to maintain the same approach as agents become disabled or are added to the network. We demonstrate the scale-invariance and dynamic response of our system in a field relevant simulator on a variety of tactical scenarios with up to 50 agents. We also demonstrate the dynamic response of our system in the field with a smaller team of agents. Lastly, we make the code for our system available.
A Game Benchmark for Real-Time Human-Swarm Control
Oct 28, 2022



We present a game benchmark for testing human-swarm control algorithms and interfaces in a real-time, high-cadence scenario. Our benchmark consists of a swarm vs. swarm game in a virtual ROS environment in which the goal of the game is to capture all agents from the opposing swarm; the game's high-cadence is a result of the capture rules, which cause agent team sizes to fluctuate rapidly. These rules require players to consider both the number of agents currently at their disposal and the behavior of their opponent's swarm when they plan actions. We demonstrate our game benchmark with a default human-swarm control system that enables a player to interact with their swarm through a high-level touchscreen interface. The touchscreen interface transforms player gestures into swarm control commands via a low-level decentralized ergodic control framework. We compare our default human-swarm control system to a flocking-based control system, and discuss traits that are crucial for swarm control algorithms and interfaces operating in real-time, high-cadence scenarios like our game benchmark. Our game benchmark code is available on Github; more information can be found at https://sites.google.com/view/swarm-game-benchmark.
Scale-Invariant Fast Functional Registration
Sep 26, 2022
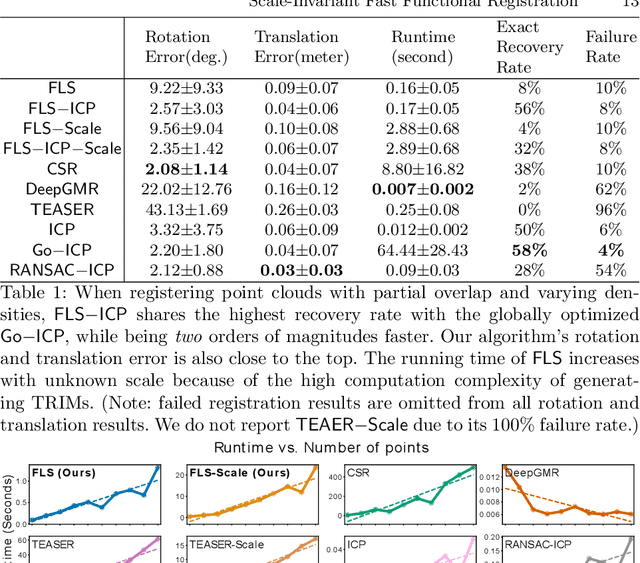
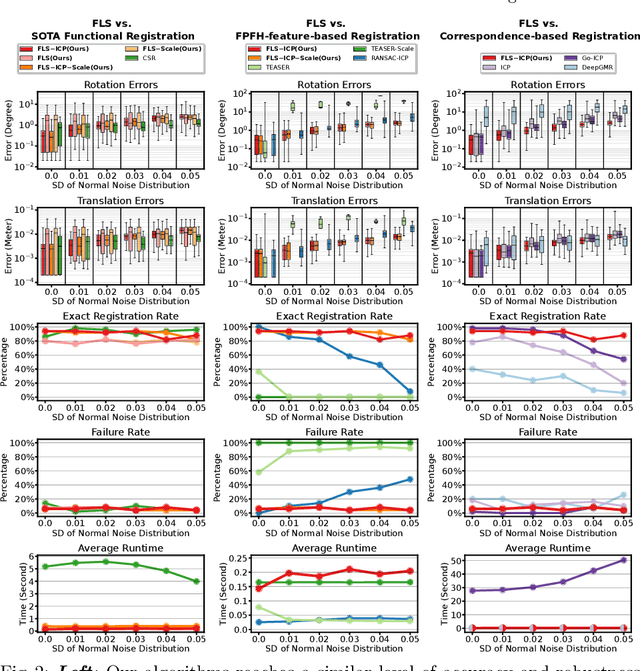
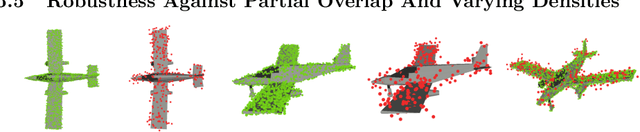
Functional registration algorithms represent point clouds as functions (e.g. spacial occupancy field) avoiding unreliable correspondence estimation in conventional least-squares registration algorithms. However, existing functional registration algorithms are computationally expensive. Furthermore, the capability of registration with unknown scale is necessary in tasks such as CAD model-based object localization, yet no such support exists in functional registration. In this work, we propose a scale-invariant, linear time complexity functional registration algorithm. We achieve linear time complexity through an efficient approximation of L2-distance between functions using orthonormal basis functions. The use of orthonormal basis functions leads to a formulation that is compatible with least-squares registration. Benefited from the least-square formulation, we use the theory of translation-rotation-invariant measurement to decouple scale estimation and therefore achieve scale-invariant registration. We evaluate the proposed algorithm, named FLS (functional least-squares), on standard 3D registration benchmarks, showing FLS is an order of magnitude faster than state-of-the-art functional registration algorithm without compromising accuracy and robustness. FLS also outperforms state-of-the-art correspondence-based least-squares registration algorithm on accuracy and robustness, with known and unknown scale. Finally, we demonstrate applying FLS to register point clouds with varying densities and partial overlaps, point clouds from different objects within the same category, and point clouds from real world objects with noisy RGB-D measurements.
* 17 pages
Hybrid Control for Learning Motor Skills
Jun 05, 2020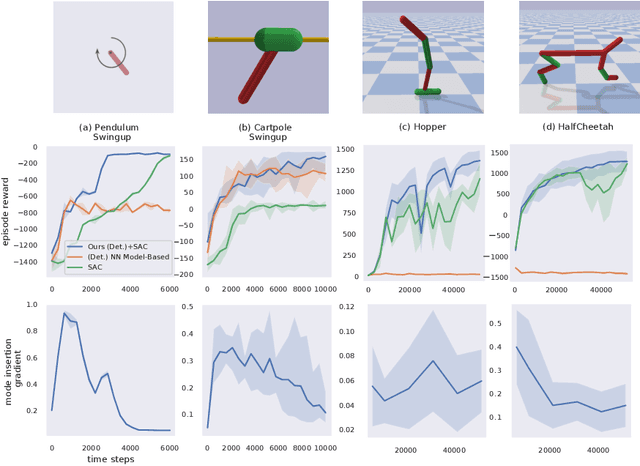

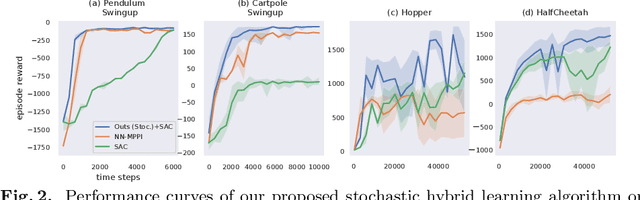

We develop a hybrid control approach for robot learning based on combining learned predictive models with experience-based state-action policy mappings to improve the learning capabilities of robotic systems. Predictive models provide an understanding of the task and the physics (which improves sample-efficiency), while experience-based policy mappings are treated as "muscle memory" that encode favorable actions as experiences that override planned actions. Hybrid control tools are used to create an algorithmic approach for combining learned predictive models with experience-based learning. Hybrid learning is presented as a method for efficiently learning motor skills by systematically combining and improving the performance of predictive models and experience-based policies. A deterministic variation of hybrid learning is derived and extended into a stochastic implementation that relaxes some of the key assumptions in the original derivation. Each variation is tested on experience-based learning methods (where the robot interacts with the environment to gain experience) as well as imitation learning methods (where experience is provided through demonstrations and tested in the environment). The results show that our method is capable of improving the performance and sample-efficiency of learning motor skills in a variety of experimental domains.