 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Koopman Operators for Model-based Shared Control of Human-Machine Systems
Jun 12, 2020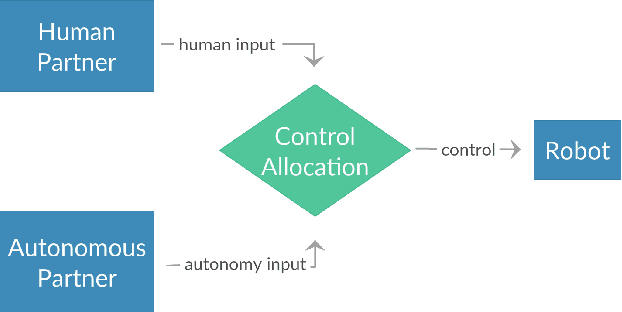


We present a data-driven shared control algorithm that can be used to improve a human operator's control of complex dynamic machines and achieve tasks that would otherwise be challenging, or impossible, for the user on their own. Our method assumes no a priori knowledge of the system dynamics. Instead, both the dynamics and information about the user's interaction are learned from observation through the use of a Koopman operator. Using the learned model, we define an optimization problem to compute the autonomous partner's control policy. Finally, we dynamically allocate control authority to each partner based on a comparison of the user input and the autonomously generated control. We refer to this idea as model-based shared control (MbSC). We evaluate the efficacy of our approach with two human subjects studies consisting of 32 total participants (16 subjects in each study). The first study imposes a linear constraint on the modeling and autonomous policy generation algorithms. The second study explores the more general, nonlinear variant. Overall, we find that model-based shared control significantly improves task and control metrics when compared to a natural learning, or user only, control paradigm. Our experiments suggest that models learned via the Koopman operator generalize across users, indicating that it is not necessary to collect data from each individual user before providing assistance with MbSC. We also demonstrate the data-efficiency of MbSC and consequently, it's usefulness in online learning paradigms. Finally, we find that the nonlinear variant has a greater impact on a user's ability to successfully achieve a defined task than the linear variant.
Hybrid Control for Learning Motor Skills
Jun 05, 2020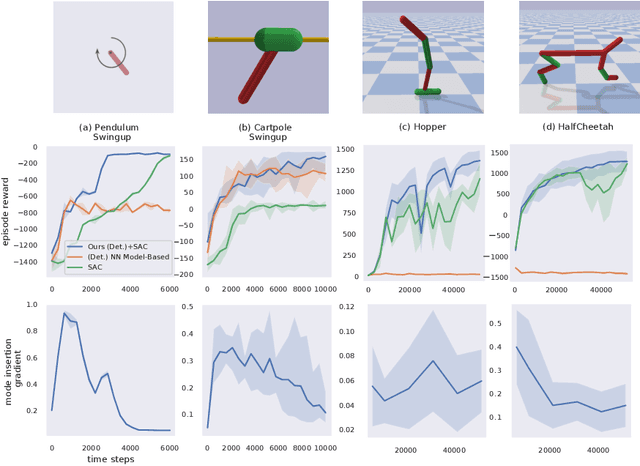

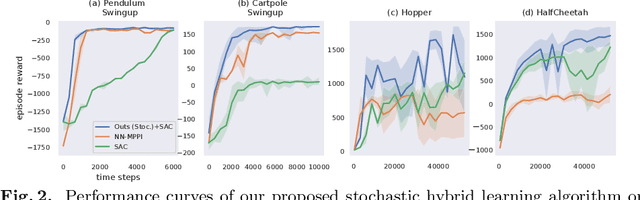

We develop a hybrid control approach for robot learning based on combining learned predictive models with experience-based state-action policy mappings to improve the learning capabilities of robotic systems. Predictive models provide an understanding of the task and the physics (which improves sample-efficiency), while experience-based policy mappings are treated as "muscle memory" that encode favorable actions as experiences that override planned actions. Hybrid control tools are used to create an algorithmic approach for combining learned predictive models with experience-based learning. Hybrid learning is presented as a method for efficiently learning motor skills by systematically combining and improving the performance of predictive models and experience-based policies. A deterministic variation of hybrid learning is derived and extended into a stochastic implementation that relaxes some of the key assumptions in the original derivation. Each variation is tested on experience-based learning methods (where the robot interacts with the environment to gain experience) as well as imitation learning methods (where experience is provided through demonstrations and tested in the environment). The results show that our method is capable of improving the performance and sample-efficiency of learning motor skills in a variety of experimental domains.
Highly Parallelized Data-driven MPC for Minimal Intervention Shared Control
Jun 05, 2019

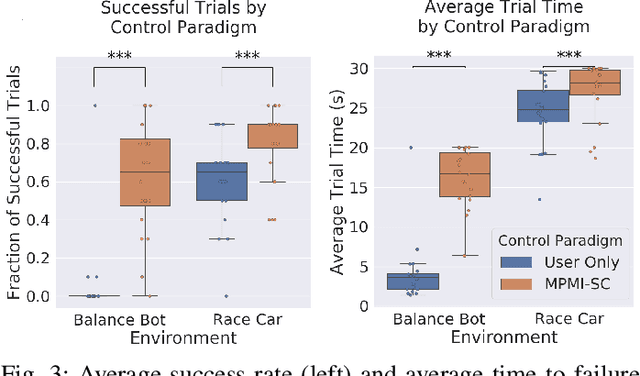

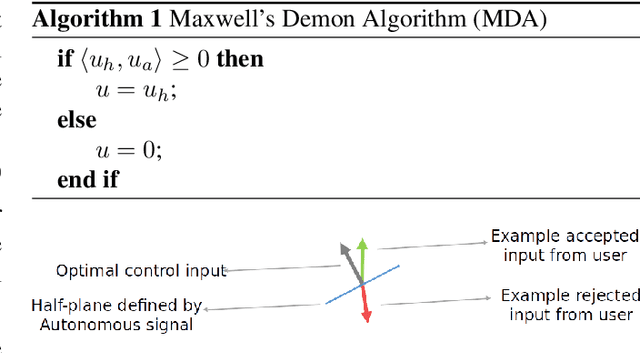
We present a shared control paradigm that improves a user's ability to operate complex, dynamic systems in potentially dangerous environments without a priori knowledge of the user's objective. In this paradigm, the role of the autonomous partner is to improve the general safety of the system without constraining the user's ability to achieve unspecified behaviors. Our approach relies on a data-driven, model-based representation of the joint human-machine system to evaluate, in parallel, a significant number of potential inputs that the user may wish to provide. These samples are used to (1) predict the safety of the system over a receding horizon, and (2) minimize the influence of the autonomous partner. The resulting shared control algorithm maximizes the authority allocated to the human partner to improve their sense of agency, while improving safety. We evaluate the efficacy of our shared control algorithm with a human subjects study (n=20) conducted in two simulated environments: a balance bot and a race car. During the experiment, users are free to operate each system however they would like (i.e., there is no specified task) and are only asked to try to avoid unsafe regions of the state space. Using modern computational resources (i.e., GPUs) our approach is able to consider more than 10,000 potential trajectories at each time step in a control loop running at 100Hz for the balance bot and 60Hz for the race car. The results of the study show that our shared control paradigm improves system safety without knowledge of the user's goal, while maintaining high-levels of user satisfaction and low-levels of frustration. Our code is available online at https://github.com/asbroad/mpmi_shared_control.
Operation and Imitation under Safety-Aware Shared Control
May 26, 2019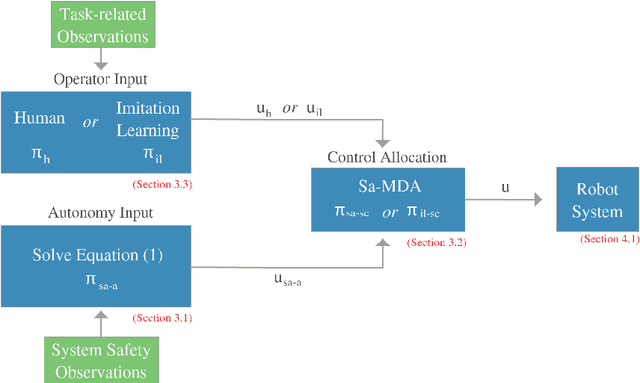



We describe a shared control methodology that can, without knowledge of the task, be used to improve a human's control of a dynamic system, be used as a training mechanism, and be used in conjunction with Imitation Learning to generate autonomous policies that recreate novel behaviors. Our algorithm introduces autonomy that assists the human partner by enforcing safety and stability constraints. The autonomous agent has no a priori knowledge of the desired task and therefore only adds control information when there is concern for the safety of the system. We evaluate the efficacy of our approach with a human subjects study consisting of 20 participants. We find that our shared control algorithm significantly improves the rate at which users are able to successfully execute novel behaviors. Experimental results suggest that the benefits of our safety-aware shared control algorithm also extend to the human partner's understanding of the system and their control skill. Finally, we demonstrate how a combination of our safety-aware shared control algorithm and Imitation Learning can be used to autonomously recreate the demonstrated behaviors.
Learning Models for Shared Control of Human-Machine Systems with Unknown Dynamics
Aug 24, 2018
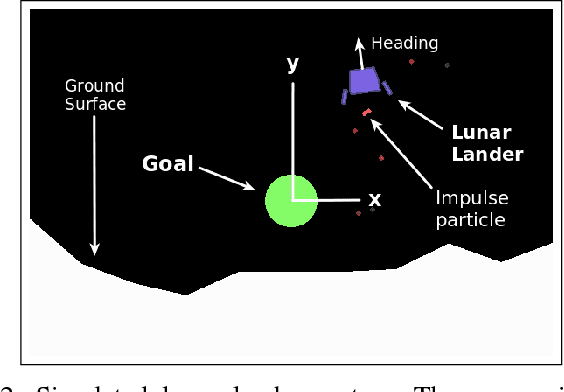
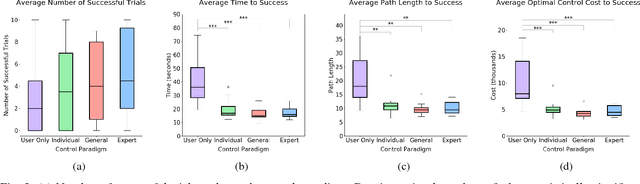
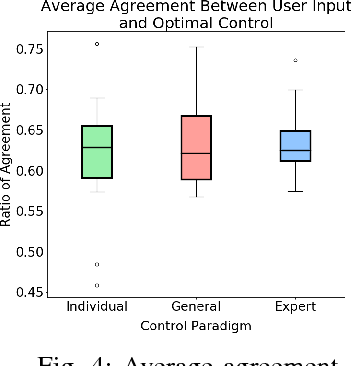
We present a novel approach to shared control of human-machine systems. Our method assumes no a priori knowledge of the system dynamics. Instead, we learn both the dynamics and information about the user's interaction from observation through the use of the Koopman operator. Using the learned model, we define an optimization problem to compute the optimal policy for a given task, and compare the user input to the optimal input. We demonstrate the efficacy of our approach with a user study. We also analyze the individual nature of the learned models by comparing the effectiveness of our approach when the demonstration data comes from a user's own interactions, from the interactions of a group of users and from a domain expert. Positive results include statistically significant improvements on task metrics when comparing a user-only control paradigm with our shared control paradigm. Surprising results include findings that suggest that individualizing the model based on a user's own data does not effect the ability to learn a useful dynamic system. We explore this tension as it relates to developing human-in-the-loop systems further in the discussion.
Structured Neural Network Dynamics for Model-based Control
Aug 03, 2018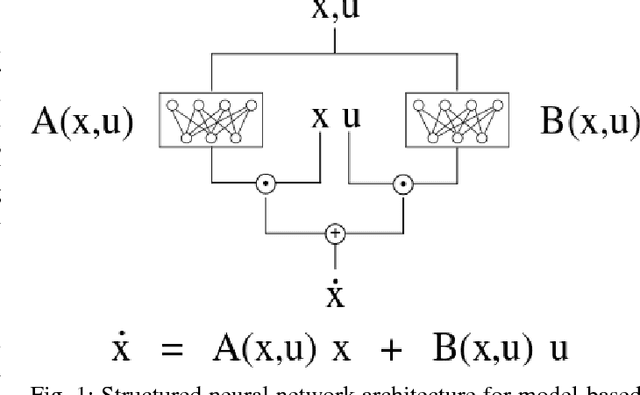

We present a structured neural network architecture that is inspired by linear time-varying dynamical systems. The network is designed to mimic the properties of linear dynamical systems which makes analysis and control simple. The architecture facilitates the integration of learned system models with gradient-based model predictive control algorithms, and removes the requirement of computing potentially costly derivatives online. We demonstrate the efficacy of this modeling technique in computing autonomous control policies through evaluation in a variety of standard continuous control domains.
Geometry-Based Region Proposals for Real-Time Robot Detection of Tabletop Objects
Mar 14, 2017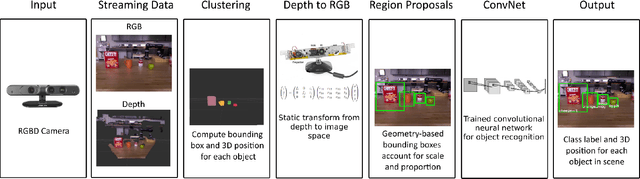
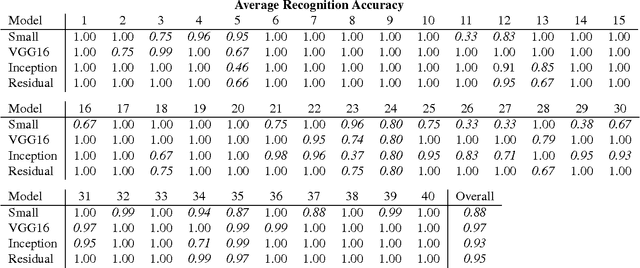


We present a novel object detection pipeline for localization and recognition in three dimensional environments. Our approach makes use of an RGB-D sensor and combines state-of-the-art techniques from the robotics and computer vision communities to create a robust, real-time detection system. We focus specifically on solving the object detection problem for tabletop scenes, a common environment for assistive manipulators. Our detection pipeline locates objects in a point cloud representation of the scene. These clusters are subsequently used to compute a bounding box around each object in the RGB space. Each defined patch is then fed into a Convolutional Neural Network (CNN) for object recognition. We also demonstrate that our region proposal method can be used to develop novel datasets that are both large and diverse enough to train deep learning models, and easy enough to collect that end-users can develop their own datasets. Lastly, we validate the resulting system through an extensive analysis of the accuracy and run-time of the full pipeline.