 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Classifier-Free Diffusion Guidance via Online Feedback
Sep 19, 2025



Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Over-communicate no more: Situated RL agents learn concise communication protocols
Nov 02, 2022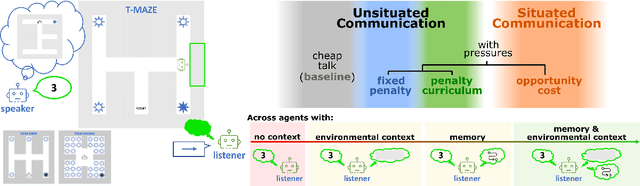
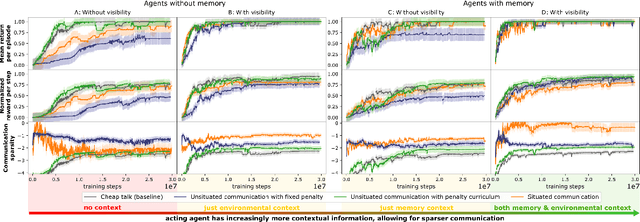
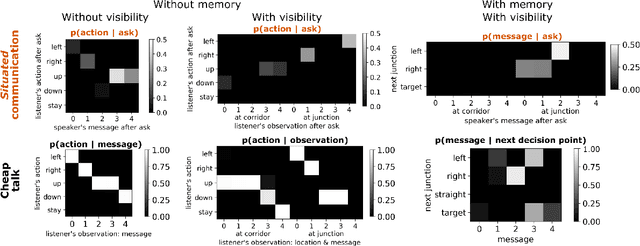
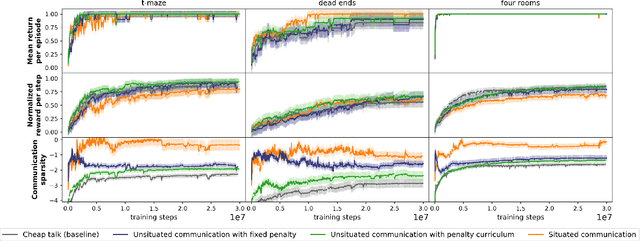
While it is known that communication facilitates cooperation in multi-agent settings, it is unclear how to design artificial agents that can learn to effectively and efficiently communicate with each other. Much research on communication emergence uses reinforcement learning (RL) and explores unsituated communication in one-step referential tasks -- the tasks are not temporally interactive and lack time pressures typically present in natural communication. In these settings, agents may successfully learn to communicate, but they do not learn to exchange information concisely -- they tend towards over-communication and an inefficient encoding. Here, we explore situated communication in a multi-step task, where the acting agent has to forgo an environmental action to communicate. Thus, we impose an opportunity cost on communication and mimic the real-world pressure of passing time. We compare communication emergence under this pressure against learning to communicate with a cost on articulation effort, implemented as a per-message penalty (fixed and progressively increasing). We find that while all tested pressures can disincentivise over-communication, situated communication does it most effectively and, unlike the cost on effort, does not negatively impact emergence. Implementing an opportunity cost on communication in a temporally extended environment is a step towards embodiment, and might be a pre-condition for incentivising efficient, human-like communication.