 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning
Oct 06, 2022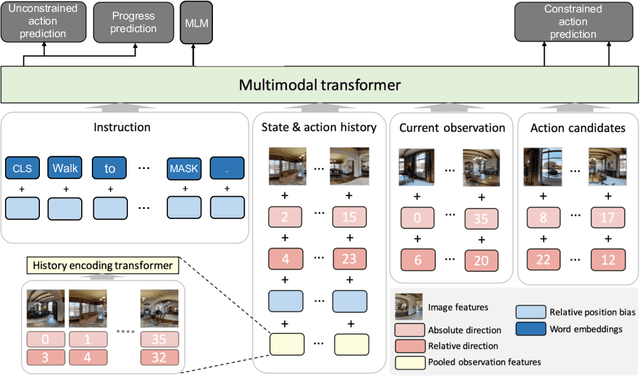
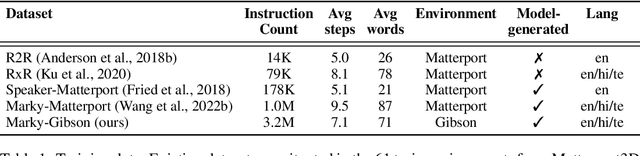
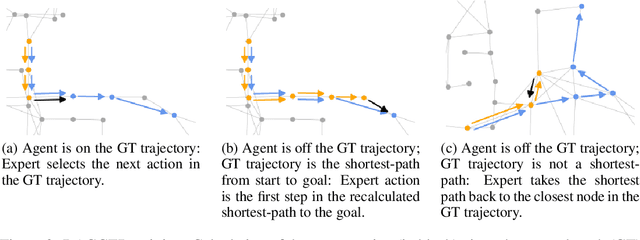
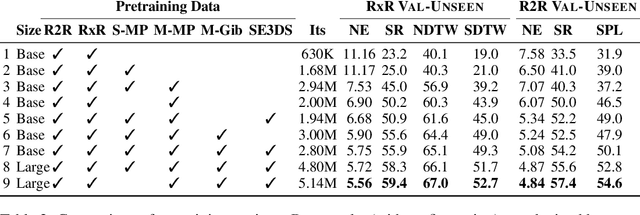
Recent studies in Vision-and-Language Navigation (VLN) train RL agents to execute natural-language navigation instructions in photorealistic environments, as a step towards intelligent agents or robots that can follow human instructions. However, given the scarcity of human instruction data and limited diversity in the training environments, these agents still struggle with complex language grounding and spatial language understanding. Pre-training on large text and image-text datasets from the web has been extensively explored but the improvements are limited. To address the scarcity of in-domain instruction data, we investigate large-scale augmentation with synthetic instructions. We take 500+ indoor environments captured in densely-sampled 360 deg panoramas, construct navigation trajectories through these panoramas, and generate a visually-grounded instruction for each trajectory using Marky (Wang et al., 2022), a high-quality multilingual navigation instruction generator. To further increase the variability of the trajectories, we also synthesize image observations from novel viewpoints using an image-to-image GAN. The resulting dataset of 4.2M instruction-trajectory pairs is two orders of magnitude larger than existing human-annotated datasets, and contains a wider variety of environments and viewpoints. To efficiently leverage data at this scale, we train a transformer agent with imitation learning for over 700M steps of experience. On the challenging Room-across-Room dataset, our approach outperforms all existing RL agents, improving the state-of-the-art NDTW from 71.1 to 79.1 in seen environments, and from 64.6 to 66.8 in unseen test environments. Our work points to a new path to improving instruction-following agents, emphasizing large-scale imitation learning and the development of synthetic instruction generation capabilities.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022


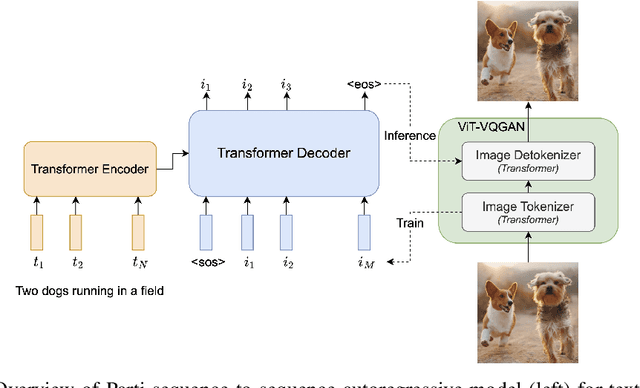
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Feb 11, 2021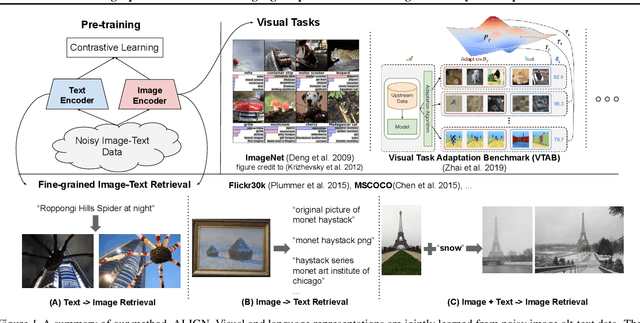
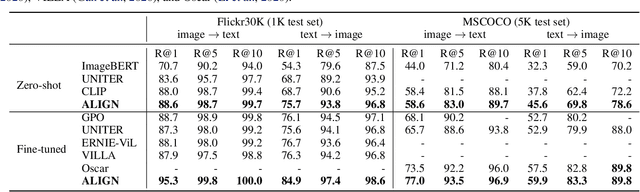


Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new state-of-the-art results on Flickr30K and MSCOCO benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.
TextSETTR: Label-Free Text Style Extraction and Tunable Targeted Restyling
Oct 08, 2020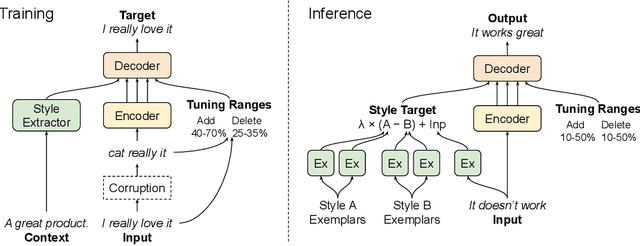
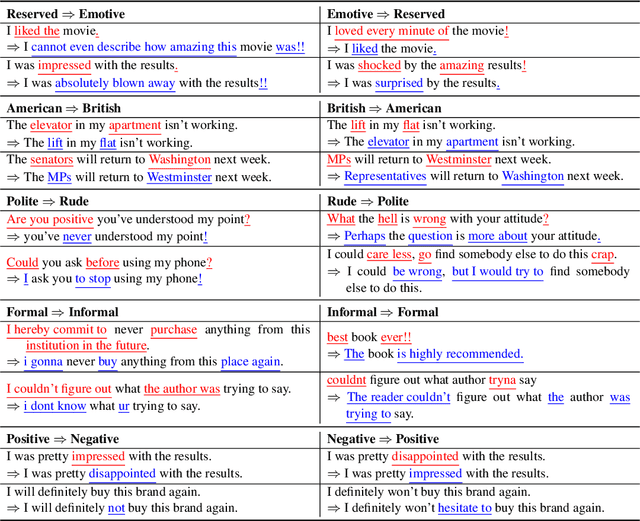
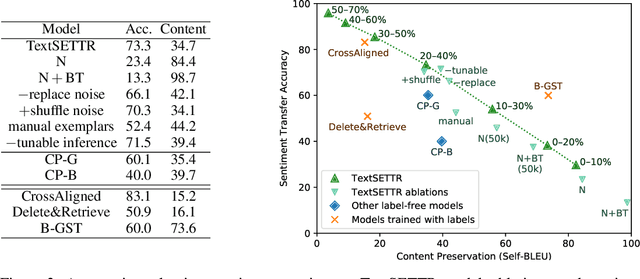

We present a novel approach to the problem of text style transfer. Unlike previous approaches that use parallel or non-parallel labeled data, our technique removes the need for labels entirely, relying instead on the implicit connection in style between adjacent sentences in unlabeled text. We show that T5 (Raffel et al., 2019), a strong pretrained text-to-text model, can be adapted to extract a style vector from arbitrary text and use this vector to condition the decoder to perform style transfer. As the resulting learned style vector space encodes many facets of textual style, we recast transfers as "targeted restyling" vector operations that adjust specific attributes of the input text while preserving others. When trained over unlabeled Amazon reviews data, our resulting TextSETTR model is competitive on sentiment transfer, even when given only four exemplars of each class. Furthermore, we demonstrate that a single model trained on unlabeled Common Crawl data is capable of transferring along multiple dimensions including dialect, emotiveness, formality, politeness, and sentiment.
Crisscrossed Captions: Extended Intramodal and Intermodal Semantic Similarity Judgments for MS-COCO
Apr 30, 2020



Image captioning datasets have proven useful for multimodal representation learning, and a common evaluation paradigm based on multimodal retrieval has emerged. Unfortunately, datasets have only limited cross-modal associations: images are not paired with others, captions are only paired with others that describe the same image, there are no negative associations and there are missing positive cross-modal associations. This undermines retrieval evaluation and limits research into how inter-modality learning impacts intra-modality tasks. To address this gap, we create the \textit{Crisscrossed Captions} (CxC) dataset, extending MS-COCO with new semantic similarity judgments for \textbf{247,315} intra- and inter-modality pairs. We provide baseline model performance results for both retrieval and correlations with human rankings, emphasizing both intra- and inter-modality learning.
Learning a Multitask Curriculum for Neural Machine Translation
Aug 28, 2019

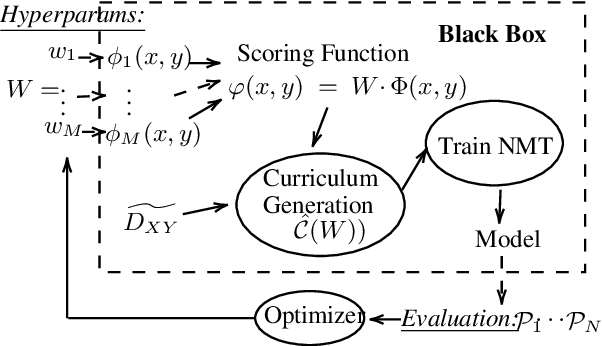

Existing curriculum learning research in neural machine translation (NMT) mostly focuses on a single final task such as selecting data for a domain or for denoising, and considers in-task example selection. This paper studies the data selection problem in multitask setting. We present a method to learn a multitask curriculum on a single, diverse, potentially noisy training dataset. It computes multiple data selection scores for each training example, each score measuring how useful the example is to a certain task. It uses Bayesian optimization to learn a linear weighting of these per-instance scores, and then sorts the data to form a curriculum. We experiment with three domain translation tasks: two specific domains and the general domain, and demonstrate that the learned multitask curriculum delivers results close to individually optimized models and brings solid gains over no curriculum training, across all test sets.
ExCL: Extractive Clip Localization Using Natural Language Descriptions
Apr 04, 2019
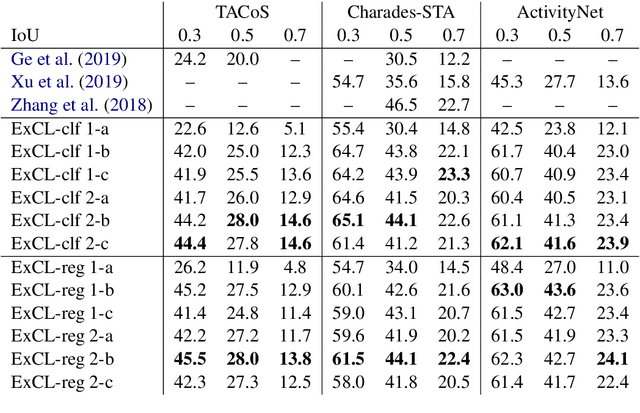
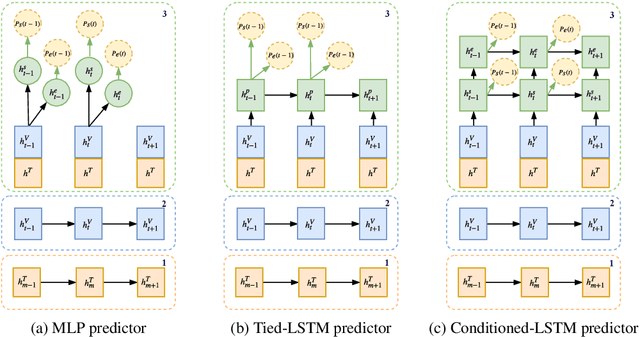
The task of retrieving clips within videos based on a given natural language query requires cross-modal reasoning over multiple frames. Prior approaches such as sliding window classifiers are inefficient, while text-clip similarity driven ranking-based approaches such as segment proposal networks are far more complicated. In order to select the most relevant video clip corresponding to the given text description, we propose a novel extractive approach that predicts the start and end frames by leveraging cross-modal interactions between the text and video - this removes the need to retrieve and re-rank multiple proposal segments. Using recurrent networks we encode the two modalities into a joint representation which is then used in different variants of start-end frame predictor networks. Through extensive experimentation and ablative analysis, we demonstrate that our simple and elegant approach significantly outperforms state of the art on two datasets and has comparable performance on a third.