 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Agentic AI Systems in Electrical Power Systems Engineering: Current State-of-the-Art and Challenges
Nov 19, 2025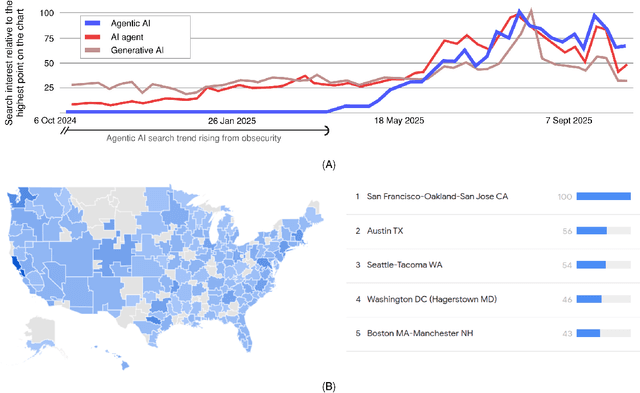
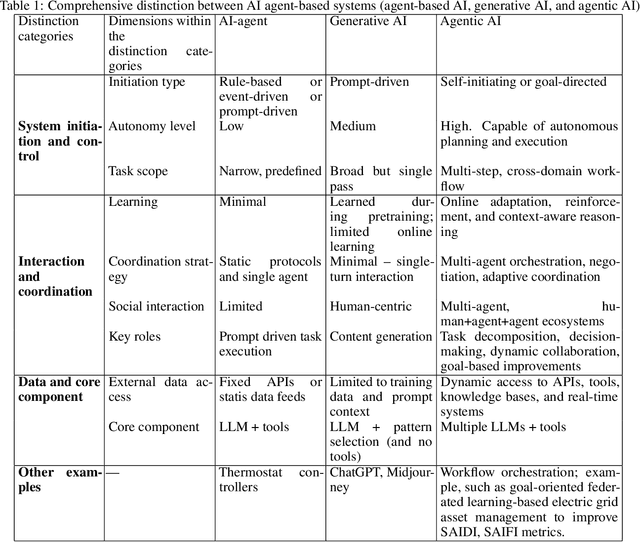
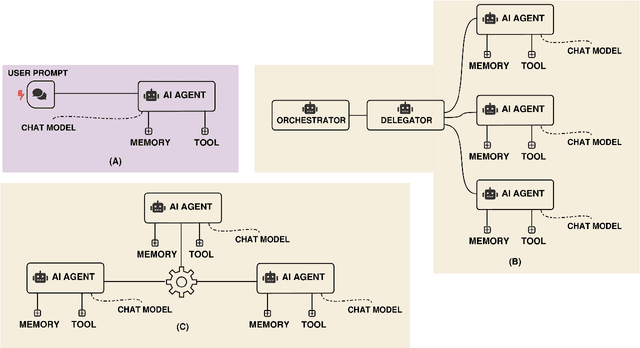
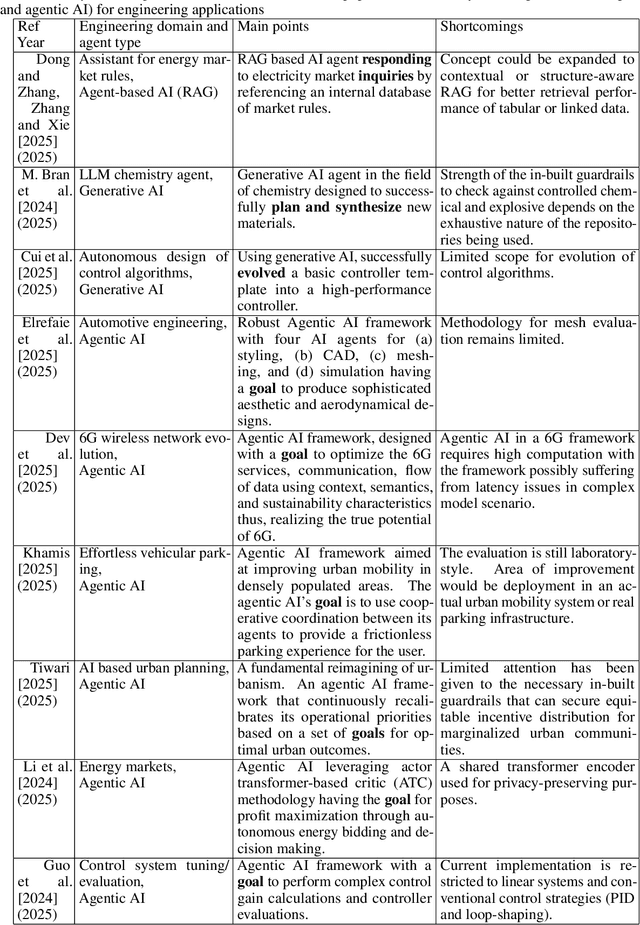
Agentic AI systems have recently emerged as a critical and transformative approach in artificial intelligence, offering capabilities that extend far beyond traditional AI agents and contemporary generative AI models. This rapid evolution necessitates a clear conceptual and taxonomical understanding to differentiate this new paradigm. Our paper addresses this gap by providing a comprehensive review that establishes a precise definition and taxonomy for "agentic AI," with the aim of distinguishing it from previous AI paradigms. The concepts are gradually introduced, starting with a highlight of its diverse applications across the broader field of engineering. The paper then presents four detailed, state-of-the-art use case applications specifically within electrical engineering. These case studies demonstrate practical impact, ranging from an advanced agentic framework for streamlining complex power system studies and benchmarking to a novel system developed for survival analysis of dynamic pricing strategies in battery swapping stations. Finally, to ensure robust deployment, the paper provides detailed failure mode investigations. From these findings, we derive actionable recommendations for the design and implementation of safe, reliable, and accountable agentic AI systems, offering a critical resource for researchers and practitioners.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
TIPS: Text-Image Pretraining with Spatial Awareness
Oct 21, 2024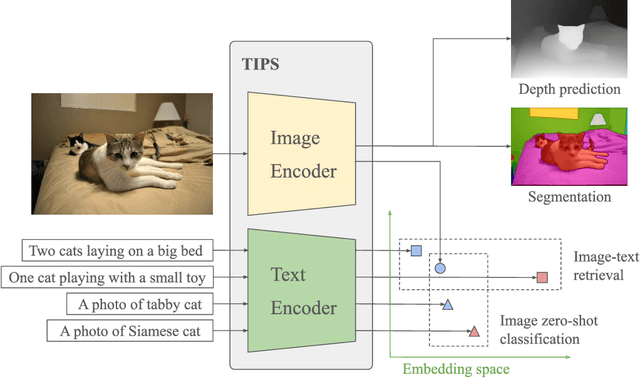
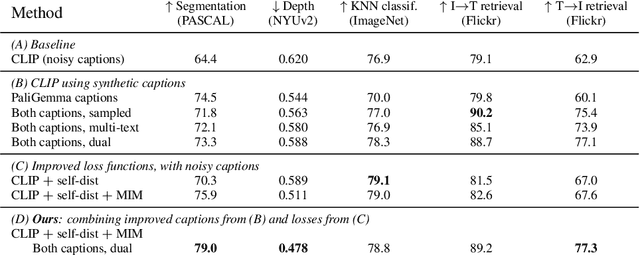
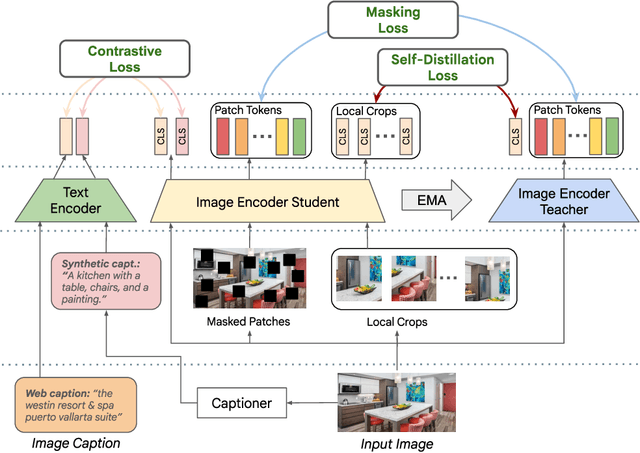
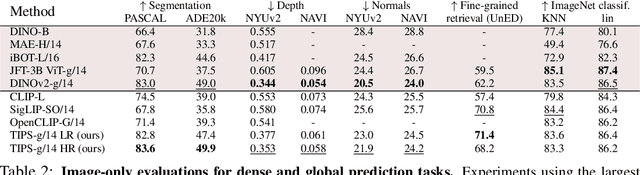
While image-text representation learning has become very popular in recent years, existing models tend to lack spatial awareness and have limited direct applicability for dense understanding tasks. For this reason, self-supervised image-only pretraining is still the go-to method for many dense vision applications (e.g. depth estimation, semantic segmentation), despite the lack of explicit supervisory signals. In this paper, we close this gap between image-text and self-supervised learning, by proposing a novel general-purpose image-text model, which can be effectively used off-the-shelf for dense and global vision tasks. Our method, which we refer to as Text-Image Pretraining with Spatial awareness (TIPS), leverages two simple and effective insights. First, on textual supervision: we reveal that replacing noisy web image captions by synthetically generated textual descriptions boosts dense understanding performance significantly, due to a much richer signal for learning spatially aware representations. We propose an adapted training method that combines noisy and synthetic captions, resulting in improvements across both dense and global understanding tasks. Second, on the learning technique: we propose to combine contrastive image-text learning with self-supervised masked image modeling, to encourage spatial coherence, unlocking substantial enhancements for downstream applications. Building on these two ideas, we scale our model using the transformer architecture, trained on a curated set of public images. Our experiments are conducted on 8 tasks involving 16 datasets in total, demonstrating strong off-the-shelf performance on both dense and global understanding, for several image-only and image-text tasks.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
ConDense: Consistent 2D/3D Pre-training for Dense and Sparse Features from Multi-View Images
Aug 30, 2024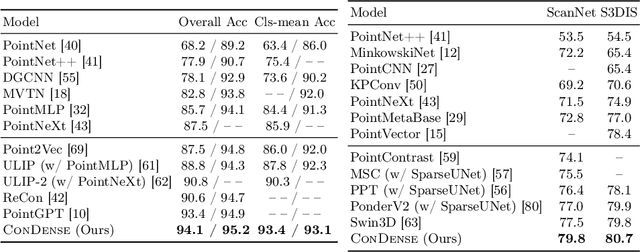
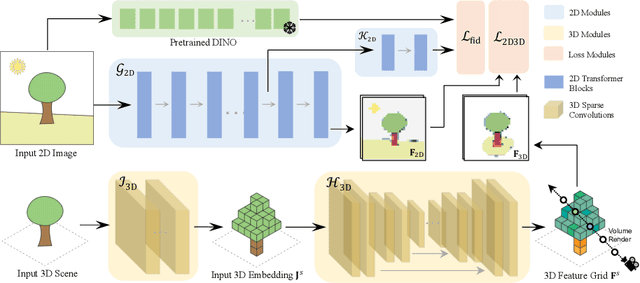
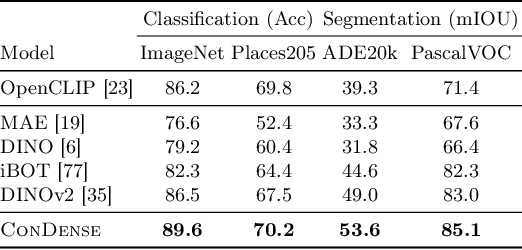
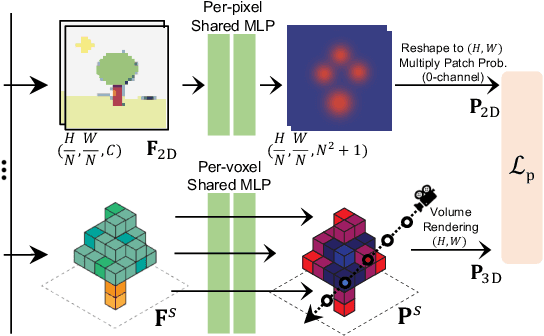
To advance the state of the art in the creation of 3D foundation models, this paper introduces the ConDense framework for 3D pre-training utilizing existing pre-trained 2D networks and large-scale multi-view datasets. We propose a novel 2D-3D joint training scheme to extract co-embedded 2D and 3D features in an end-to-end pipeline, where 2D-3D feature consistency is enforced through a volume rendering NeRF-like ray marching process. Using dense per pixel features we are able to 1) directly distill the learned priors from 2D models to 3D models and create useful 3D backbones, 2) extract more consistent and less noisy 2D features, 3) formulate a consistent embedding space where 2D, 3D, and other modalities of data (e.g., natural language prompts) can be jointly queried. Furthermore, besides dense features, ConDense can be trained to extract sparse features (e.g., key points), also with 2D-3D consistency -- condensing 3D NeRF representations into compact sets of decorated key points. We demonstrate that our pre-trained model provides good initialization for various 3D tasks including 3D classification and segmentation, outperforming other 3D pre-training methods by a significant margin. It also enables, by exploiting our sparse features, additional useful downstream tasks, such as matching 2D images to 3D scenes, detecting duplicate 3D scenes, and querying a repository of 3D scenes through natural language -- all quite efficiently and without any per-scene fine-tuning.
Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
Dec 09, 2022



This work explores an efficient approach to establish a foundational video-text model for tasks including open-vocabulary video classification, text-to-video retrieval, video captioning and video question-answering. We present VideoCoCa that reuses a pretrained image-text contrastive captioner (CoCa) model and adapt it to video-text tasks with minimal extra training. While previous works adapt image-text models with various cross-frame fusion modules (for example, cross-frame attention layer or perceiver resampler) and finetune the modified architecture on video-text data, we surprisingly find that the generative attentional pooling and contrastive attentional pooling layers in the image-text CoCa design are instantly adaptable to ``flattened frame embeddings'', yielding a strong zero-shot transfer baseline for many video-text tasks. Specifically, the frozen image encoder of a pretrained image-text CoCa takes each video frame as inputs and generates \(N\) token embeddings per frame for totally \(T\) video frames. We flatten \(N \times T\) token embeddings as a long sequence of frozen video representation and apply CoCa's generative attentional pooling and contrastive attentional pooling on top. All model weights including pooling layers are directly loaded from an image-text CoCa pretrained model. Without any video or video-text data, VideoCoCa's zero-shot transfer baseline already achieves state-of-the-art results on zero-shot video classification on Kinetics 400/600/700, UCF101, HMDB51, and Charades, as well as zero-shot text-to-video retrieval on MSR-VTT and ActivityNet Captions. We also explore lightweight finetuning on top of VideoCoCa, and achieve strong results on video question-answering (iVQA, MSRVTT-QA, MSVD-QA) and video captioning (MSR-VTT, ActivityNet, Youcook2). Our approach establishes a simple and effective video-text baseline for future research.
ExCL: Extractive Clip Localization Using Natural Language Descriptions
Apr 04, 2019
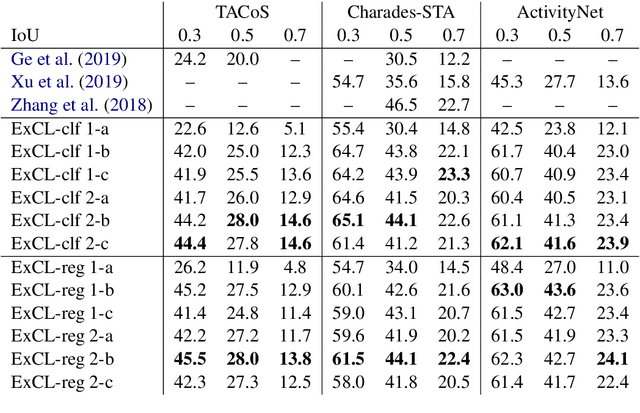
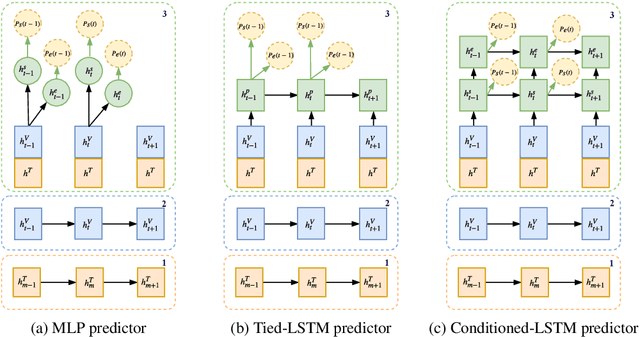
The task of retrieving clips within videos based on a given natural language query requires cross-modal reasoning over multiple frames. Prior approaches such as sliding window classifiers are inefficient, while text-clip similarity driven ranking-based approaches such as segment proposal networks are far more complicated. In order to select the most relevant video clip corresponding to the given text description, we propose a novel extractive approach that predicts the start and end frames by leveraging cross-modal interactions between the text and video - this removes the need to retrieve and re-rank multiple proposal segments. Using recurrent networks we encode the two modalities into a joint representation which is then used in different variants of start-end frame predictor networks. Through extensive experimentation and ablative analysis, we demonstrate that our simple and elegant approach significantly outperforms state of the art on two datasets and has comparable performance on a third.
Concurrent Meta Reinforcement Learning
Mar 07, 2019

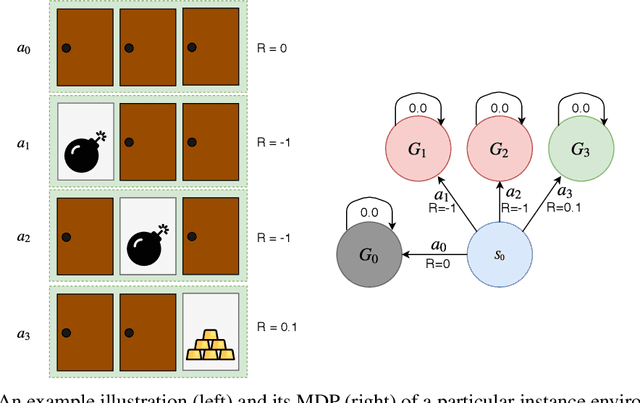

State-of-the-art meta reinforcement learning algorithms typically assume the setting of a single agent interacting with its environment in a sequential manner. A negative side-effect of this sequential execution paradigm is that, as the environment becomes more and more challenging, and thus requiring more interaction episodes for the meta-learner, it needs the agent to reason over longer and longer time-scales. To combat the difficulty of long time-scale credit assignment, we propose an alternative parallel framework, which we name "Concurrent Meta-Reinforcement Learning" (CMRL), that transforms the temporal credit assignment problem into a multi-agent reinforcement learning one. In this multi-agent setting, a set of parallel agents are executed in the same environment and each of these "rollout" agents are given the means to communicate with each other. The goal of the communication is to coordinate, in a collaborative manner, the most efficient exploration of the shared task the agents are currently assigned. This coordination therefore represents the meta-learning aspect of the framework, as each agent can be assigned or assign itself a particular section of the current task's state space. This framework is in contrast to standard RL methods that assume that each parallel rollout occurs independently, which can potentially waste computation if many of the rollouts end up sampling the same part of the state space. Furthermore, the parallel setting enables us to define several reward sharing functions and auxiliary losses that are non-trivial to apply in the sequential setting. We demonstrate the effectiveness of our proposed CMRL at improving over sequential methods in a variety of challenging tasks.