 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Generate to Discriminate: Expert Routing for Continual Learning
Dec 22, 2024In many real-world settings, regulations and economic incentives permit the sharing of models but not data across institutional boundaries. In such scenarios, practitioners might hope to adapt models to new domains, without losing performance on previous domains (so-called catastrophic forgetting). While any single model may struggle to achieve this goal, learning an ensemble of domain-specific experts offers the potential to adapt more closely to each individual institution. However, a core challenge in this context is determining which expert to deploy at test time. In this paper, we propose Generate to Discriminate (G2D), a domain-incremental continual learning method that leverages synthetic data to train a domain-discriminator that routes samples at inference time to the appropriate expert. Surprisingly, we find that leveraging synthetic data in this capacity is more effective than using the samples to \textit{directly} train the downstream classifier (the more common approach to leveraging synthetic data in the lifelong learning literature). We observe that G2D outperforms competitive domain-incremental learning methods on tasks in both vision and language modalities, providing a new perspective on the use of synthetic data in the lifelong learning literature.
The Limited Impact of Medical Adaptation of Large Language and Vision-Language Models
Nov 13, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare ten public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting and supervised fine-tuning regimes for medical question-answering (QA). For instance, across all tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 22.7% of cases, reach a (statistical) tie in 36.8% of cases, and are significantly worse than their base models in the remaining 40.5% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately in zero-/few-shot prompting; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Meanwhile, we find that after fine-tuning on specific QA tasks, medical LLMs can show performance improvements, but the benefits do not carry over to tasks based on clinical notes. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?
Nov 06, 2024



Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued pretraining on publicly available biomedical corpora. These works typically claim that such domain-adaptive pretraining (DAPT) improves performance on downstream medical tasks, such as answering medical licensing exam questions. In this paper, we compare seven public "medical" LLMs and two VLMs against their corresponding base models, arriving at a different conclusion: all medical VLMs and nearly all medical LLMs fail to consistently improve over their base models in the zero-/few-shot prompting regime for medical question-answering (QA) tasks. For instance, across the tasks and model pairs we consider in the 3-shot setting, medical LLMs only outperform their base models in 12.1% of cases, reach a (statistical) tie in 49.8% of cases, and are significantly worse than their base models in the remaining 38.2% of cases. Our conclusions are based on (i) comparing each medical model head-to-head, directly against the corresponding base model; (ii) optimizing the prompts for each model separately; and (iii) accounting for statistical uncertainty in comparisons. While these basic practices are not consistently adopted in the literature, our ablations show that they substantially impact conclusions. Our findings suggest that state-of-the-art general-domain models may already exhibit strong medical knowledge and reasoning capabilities, and offer recommendations to strengthen the conclusions of future studies.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
Jun 20, 2024Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning via an empirical study, followed by building a conceptual understanding of our observations. First, we find that while the typical approach of finetuning a model on synthetic correct or positive problem-solution pairs generated by capable models offers modest performance gains, sampling more correct solutions from the finetuned learner itself followed by subsequent fine-tuning on this self-generated data $\textbf{doubles}$ the efficiency of the same synthetic problems. At the same time, training on model-generated positives can amplify various spurious correlations, resulting in flat or even inverse scaling trends as the amount of data increases. Surprisingly, we find that several of these issues can be addressed if we also utilize negative responses, i.e., model-generated responses that are deemed incorrect by a final answer verifier. Crucially, these negatives must be constructed such that the training can appropriately recover the utility or advantage of each intermediate step in the negative response. With this per-step scheme, we are able to attain consistent gains over only positive data, attaining performance similar to amplifying the amount of synthetic data by $\mathbf{8 \times}$. We show that training on per-step negatives can help to unlearn spurious correlations in the positive data, and is equivalent to advantage-weighted reinforcement learning (RL), implying that it inherits robustness benefits of RL over imitating positive data alone.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Post-Hoc Reversal: Are We Selecting Models Prematurely?
Apr 11, 2024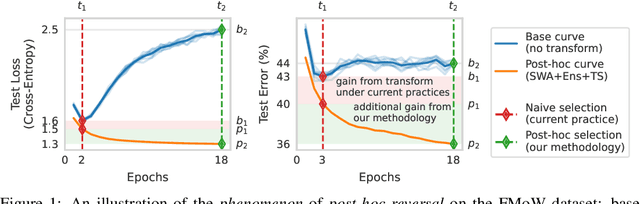
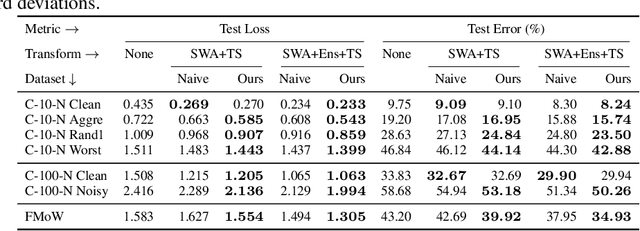
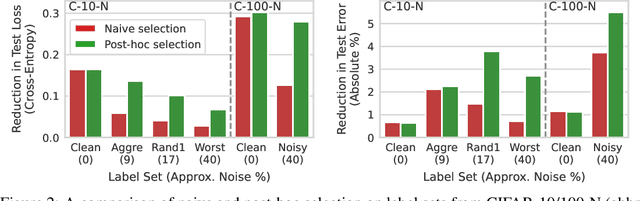

Trained models are often composed with post-hoc transforms such as temperature scaling (TS), ensembling and stochastic weight averaging (SWA) to improve performance, robustness, uncertainty estimation, etc. However, such transforms are typically applied only after the base models have already been finalized by standard means. In this paper, we challenge this practice with an extensive empirical study. In particular, we demonstrate a phenomenon that we call post-hoc reversal, where performance trends are reversed after applying these post-hoc transforms. This phenomenon is especially prominent in high-noise settings. For example, while base models overfit badly early in training, both conventional ensembling and SWA favor base models trained for more epochs. Post-hoc reversal can also suppress the appearance of double descent and mitigate mismatches between test loss and test error seen in base models. Based on our findings, we propose post-hoc selection, a simple technique whereby post-hoc metrics inform model development decisions such as early stopping, checkpointing, and broader hyperparameter choices. Our experimental analyses span real-world vision, language, tabular and graph datasets from domains like satellite imaging, language modeling, census prediction and social network analysis. On an LLM instruction tuning dataset, post-hoc selection results in > 1.5x MMLU improvement compared to naive selection. Code is available at https://github.com/rishabh-ranjan/post-hoc-reversal.
Complementary Benefits of Contrastive Learning and Self-Training Under Distribution Shift
Dec 06, 2023Self-training and contrastive learning have emerged as leading techniques for incorporating unlabeled data, both under distribution shift (unsupervised domain adaptation) and when it is absent (semi-supervised learning). However, despite the popularity and compatibility of these techniques, their efficacy in combination remains unexplored. In this paper, we undertake a systematic empirical investigation of this combination, finding that (i) in domain adaptation settings, self-training and contrastive learning offer significant complementary gains; and (ii) in semi-supervised learning settings, surprisingly, the benefits are not synergistic. Across eight distribution shift datasets (e.g., BREEDs, WILDS), we demonstrate that the combined method obtains 3--8% higher accuracy than either approach independently. We then theoretically analyze these techniques in a simplified model of distribution shift, demonstrating scenarios under which the features produced by contrastive learning can yield a good initialization for self-training to further amplify gains and achieve optimal performance, even when either method alone would fail.
Deep Learning for Plant Identification and Disease Classification from Leaf Images: Multi-prediction Approaches
Oct 25, 2023
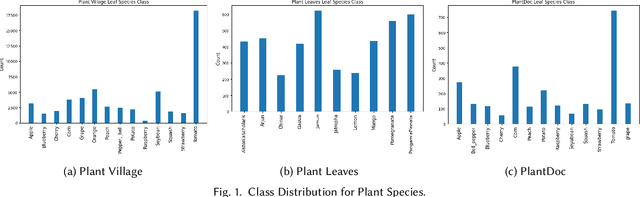
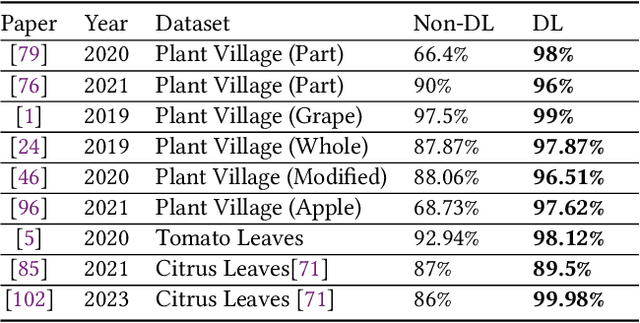
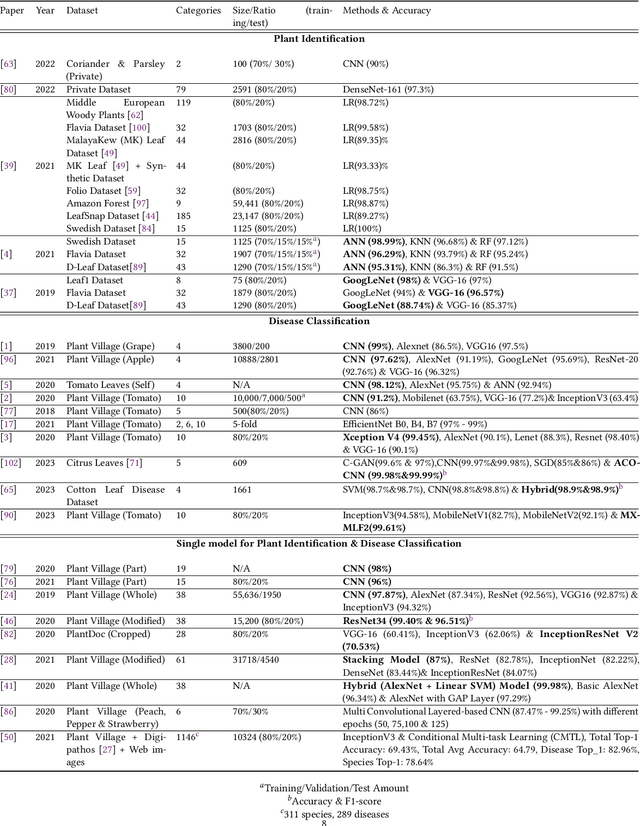
Deep learning plays an important role in modern agriculture, especially in plant pathology using leaf images where convolutional neural networks (CNN) are attracting a lot of attention. While numerous reviews have explored the applications of deep learning within this research domain, there remains a notable absence of an empirical study to offer insightful comparisons due to the employment of varied datasets in the evaluation. Furthermore, a majority of these approaches tend to address the problem as a singular prediction task, overlooking the multifaceted nature of predicting various aspects of plant species and disease types. Lastly, there is an evident need for a more profound consideration of the semantic relationships that underlie plant species and disease types. In this paper, we start our study by surveying current deep learning approaches for plant identification and disease classification. We categorise the approaches into multi-model, multi-label, multi-output, and multi-task, in which different backbone CNNs can be employed. Furthermore, based on the survey of existing approaches in plant pathology and the study of available approaches in machine learning, we propose a new model named Generalised Stacking Multi-output CNN (GSMo-CNN). To investigate the effectiveness of different backbone CNNs and learning approaches, we conduct an intensive experiment on three benchmark datasets Plant Village, Plant Leaves, and PlantDoc. The experimental results demonstrate that InceptionV3 can be a good choice for a backbone CNN as its performance is better than AlexNet, VGG16, ResNet101, EfficientNet, MobileNet, and a custom CNN developed by us. Interestingly, empirical results support the hypothesis that using a single model can be comparable or better than using two models. Finally, we show that the proposed GSMo-CNN achieves state-of-the-art performance on three benchmark datasets.