 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-output Deep-Supervised Classifier Chains for Plant Pathology
Jul 27, 2025Plant leaf disease classification is an important task in smart agriculture which plays a critical role in sustainable production. Modern machine learning approaches have shown unprecedented potential in this classification task which offers an array of benefits including time saving and cost reduction. However, most recent approaches directly employ convolutional neural networks where the effect of the relationship between plant species and disease types on prediction performance is not properly studied. In this study, we proposed a new model named Multi-output Deep Supervised Classifier Chains (Mo-DsCC) which weaves the prediction of plant species and disease by chaining the output layers for the two labels. Mo-DsCC consists of three components: A modified VGG-16 network as the backbone, deep supervision training, and a stack of classification chains. To evaluate the advantages of our model, we perform intensive experiments on two benchmark datasets Plant Village and PlantDoc. Comparison to recent approaches, including multi-model, multi-label (Power-set), multi-output and multi-task, demonstrates that Mo-DsCC achieves better accuracy and F1-score. The empirical study in this paper shows that the application of Mo-DsCC could be a useful puzzle for smart agriculture to benefit farms and bring new ideas to industry and academia.
Wine Characterisation with Spectral Information and Predictive Artificial Intelligence
Jul 27, 2025The purpose of this paper is to use absorbance data obtained by human tasting and an ultraviolet-visible (UV-Vis) scanning spectrophotometer to predict the attributes of grape juice (GJ) and to classify the wine's origin, respectively. The approach combined machine learning (ML) techniques with spectroscopy to find a relatively simple way to apply them in two stages of winemaking and help improve the traditional wine analysis methods regarding sensory data and wine's origins. This new technique has overcome the disadvantages of the complex sensors by taking advantage of spectral fingerprinting technology and forming a comprehensive study of the employment of AI in the wine analysis domain. In the results, Support Vector Machine (SVM) was the most efficient and robust in both attributes and origin prediction tasks. Both the accuracy and F1 score of the origin prediction exceed 91%. The feature ranking approach found that the more influential wavelengths usually appear at the lower end of the scan range, 250 nm (nanometers) to 420 nm, which is believed to be of great help for selecting appropriate validation methods and sensors to extract wine data in future research. The knowledge of this research provides new ideas and early solutions for the wine industry or other beverage industries to integrate big data and IoT in the future, which significantly promotes the development of 'Smart Wineries'.
Deep Learning for Plant Identification and Disease Classification from Leaf Images: Multi-prediction Approaches
Oct 25, 2023
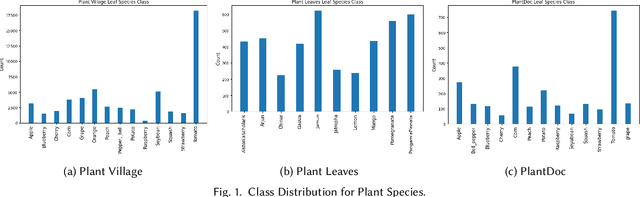
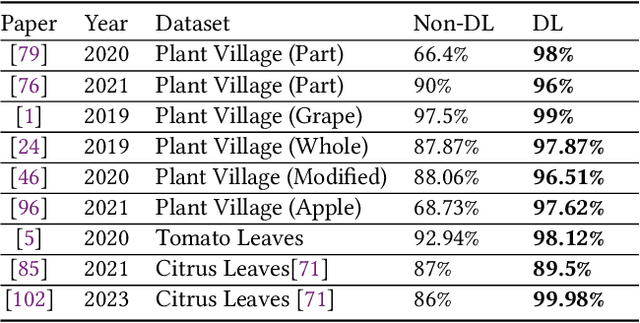
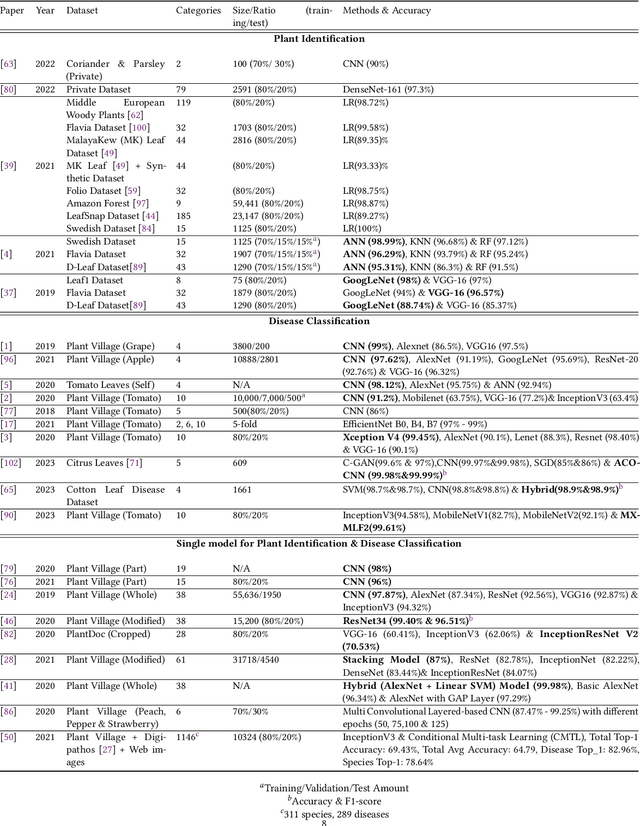
Deep learning plays an important role in modern agriculture, especially in plant pathology using leaf images where convolutional neural networks (CNN) are attracting a lot of attention. While numerous reviews have explored the applications of deep learning within this research domain, there remains a notable absence of an empirical study to offer insightful comparisons due to the employment of varied datasets in the evaluation. Furthermore, a majority of these approaches tend to address the problem as a singular prediction task, overlooking the multifaceted nature of predicting various aspects of plant species and disease types. Lastly, there is an evident need for a more profound consideration of the semantic relationships that underlie plant species and disease types. In this paper, we start our study by surveying current deep learning approaches for plant identification and disease classification. We categorise the approaches into multi-model, multi-label, multi-output, and multi-task, in which different backbone CNNs can be employed. Furthermore, based on the survey of existing approaches in plant pathology and the study of available approaches in machine learning, we propose a new model named Generalised Stacking Multi-output CNN (GSMo-CNN). To investigate the effectiveness of different backbone CNNs and learning approaches, we conduct an intensive experiment on three benchmark datasets Plant Village, Plant Leaves, and PlantDoc. The experimental results demonstrate that InceptionV3 can be a good choice for a backbone CNN as its performance is better than AlexNet, VGG16, ResNet101, EfficientNet, MobileNet, and a custom CNN developed by us. Interestingly, empirical results support the hypothesis that using a single model can be comparable or better than using two models. Finally, we show that the proposed GSMo-CNN achieves state-of-the-art performance on three benchmark datasets.
Machine Learning for Leaf Disease Classification: Data, Techniques and Applications
Oct 19, 2023The growing demand for sustainable development brings a series of information technologies to help agriculture production. Especially, the emergence of machine learning applications, a branch of artificial intelligence, has shown multiple breakthroughs which can enhance and revolutionize plant pathology approaches. In recent years, machine learning has been adopted for leaf disease classification in both academic research and industrial applications. Therefore, it is enormously beneficial for researchers, engineers, managers, and entrepreneurs to have a comprehensive view about the recent development of machine learning technologies and applications for leaf disease detection. This study will provide a survey in different aspects of the topic including data, techniques, and applications. The paper will start with publicly available datasets. After that, we summarize common machine learning techniques, including traditional (shallow) learning, deep learning, and augmented learning. Finally, we discuss related applications. This paper would provide useful resources for future study and application of machine learning for smart agriculture in general and leaf disease classification in particular.
A Comprehensive Review on Deep Supervision: Theories and Applications
Jul 06, 2022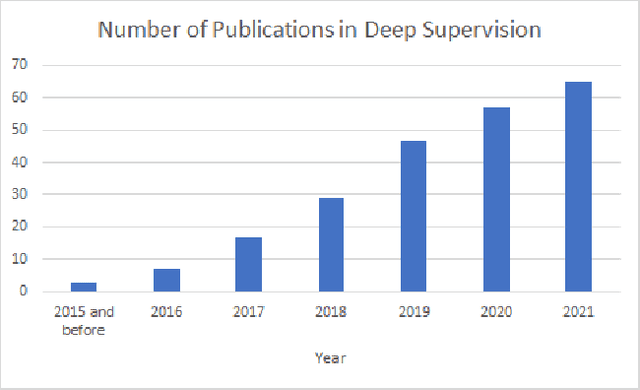
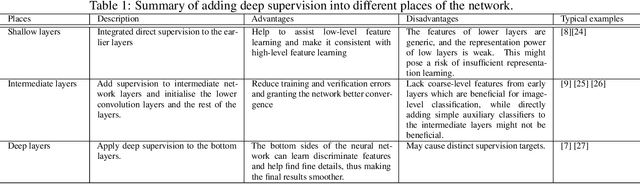
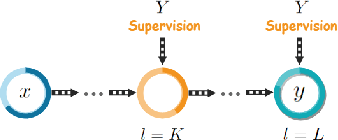

Deep supervision, or known as 'intermediate supervision' or 'auxiliary supervision', is to add supervision at hidden layers of a neural network. This technique has been increasingly applied in deep neural network learning systems for various computer vision applications recently. There is a consensus that deep supervision helps improve neural network performance by alleviating the gradient vanishing problem, as one of the many strengths of deep supervision. Besides, in different computer vision applications, deep supervision can be applied in different ways. How to make the most use of deep supervision to improve network performance in different applications has not been thoroughly investigated. In this paper, we provide a comprehensive in-depth review of deep supervision in both theories and applications. We propose a new classification of different deep supervision networks, and discuss advantages and limitations of current deep supervision networks in computer vision applications.
Logical Boltzmann Machines
Dec 10, 2021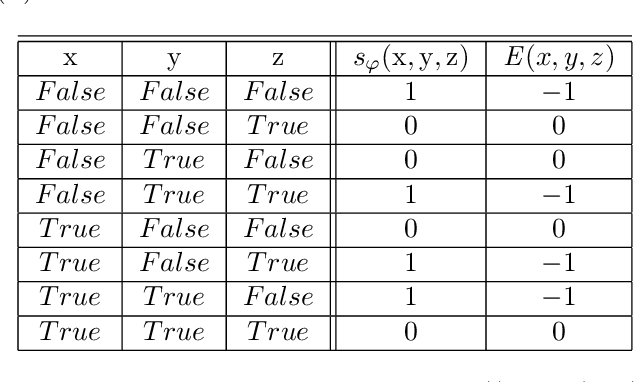


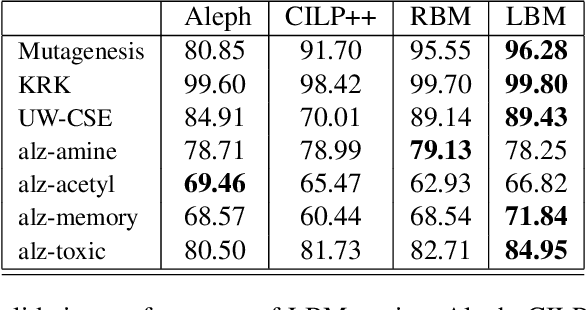
The idea of representing symbolic knowledge in connectionist systems has been a long-standing endeavour which has attracted much attention recently with the objective of combining machine learning and scalable sound reasoning. Early work has shown a correspondence between propositional logic and symmetrical neural networks which nevertheless did not scale well with the number of variables and whose training regime was inefficient. In this paper, we introduce Logical Boltzmann Machines (LBM), a neurosymbolic system that can represent any propositional logic formula in strict disjunctive normal form. We prove equivalence between energy minimization in LBM and logical satisfiability thus showing that LBM is capable of sound reasoning. We evaluate reasoning empirically to show that LBM is capable of finding all satisfying assignments of a class of logical formulae by searching fewer than 0.75% of the possible (approximately 1 billion) assignments. We compare learning in LBM with a symbolic inductive logic programming system, a state-of-the-art neurosymbolic system and a purely neural network-based system, achieving better learning performance in five out of seven data sets.
Hand gesture detection in tests performed by older adults
Oct 29, 2021

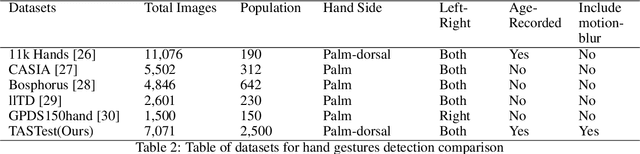
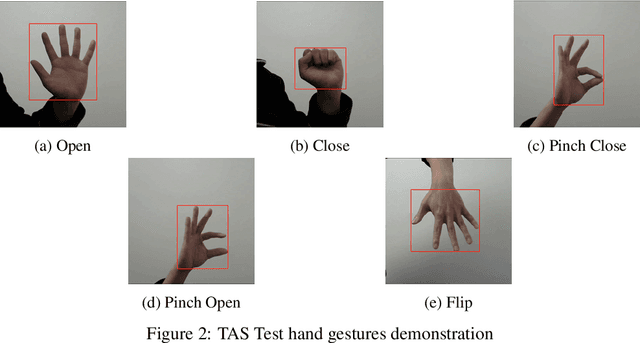
Our team are developing a new online test that analyses hand movement features associated with ageing that can be completed remotely from the research centre. To obtain hand movement features, participants will be asked to perform a variety of hand gestures using their own computer cameras. However, it is challenging to collect high quality hand movement video data, especially for older participants, many of whom have no IT background. During the data collection process, one of the key steps is to detect whether the participants are following the test instructions correctly and also to detect similar gestures from different devices. Furthermore, we need this process to be automated and accurate as we expect many thousands of participants to complete the test. We have implemented a hand gesture detector to detect the gestures in the hand movement tests and our detection mAP is 0.782 which is better than the state-of-the-art. In this research, we have processed 20,000 images collected from hand movement tests and labelled 6,450 images to detect different hand gestures in the hand movement tests. This paper has the following three contributions. Firstly, we compared and analysed the performance of different network structures for hand gesture detection. Secondly, we have made many attempts to improve the accuracy of the model and have succeeded in improving the classification accuracy for similar gestures by implementing attention layers. Thirdly, we have created two datasets and included 20 percent of blurred images in the dataset to investigate how different network structures were impacted by noisy data, our experiments have also shown our network has better performance on the noisy dataset.
Coconut trees detection and segmentation in aerial imagery using mask region-based convolution neural network
May 10, 2021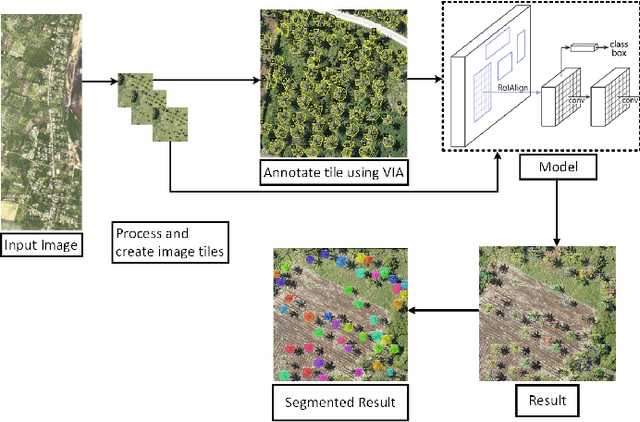
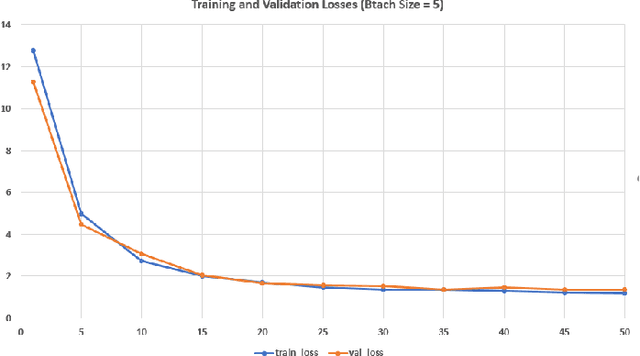
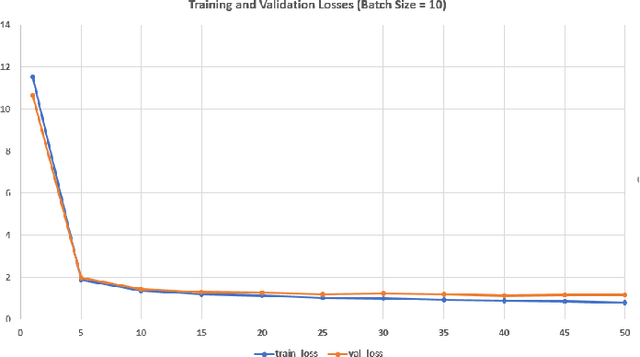
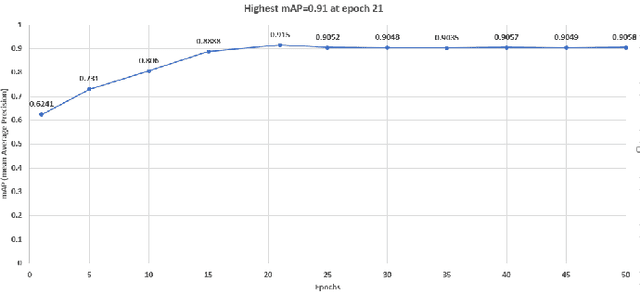
Food resources face severe damages under extraordinary situations of catastrophes such as earthquakes, cyclones, and tsunamis. Under such scenarios, speedy assessment of food resources from agricultural land is critical as it supports aid activity in the disaster hit areas. In this article, a deep learning approach is presented for the detection and segmentation of coconut tress in aerial imagery provided through the AI competition organized by the World Bank in collaboration with OpenAerialMap and WeRobotics. Maked Region-based Convolutional Neural Network approach was used identification and segmentation of coconut trees. For the segmentation task, Mask R-CNN model with ResNet50 and ResNet1010 based architectures was used. Several experiments with different configuration parameters were performed and the best configuration for the detection of coconut trees with more than 90% confidence factor was reported. For the purpose of evaluation, Microsoft COCO dataset evaluation metric namely mean average precision (mAP) was used. An overall 91% mean average precision for coconut trees detection was achieved.
Deep Auto-Encoders with Sequential Learning for Multimodal Dimensional Emotion Recognition
Apr 28, 2020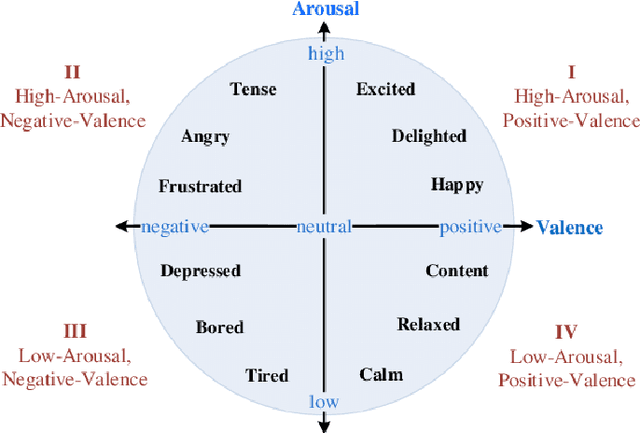
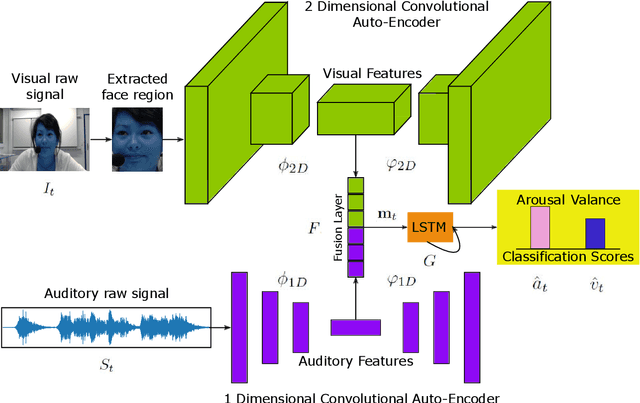
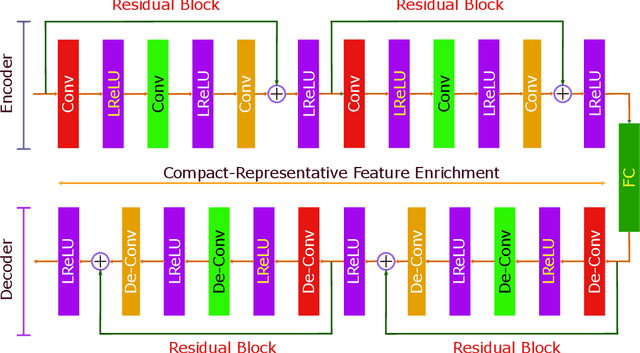
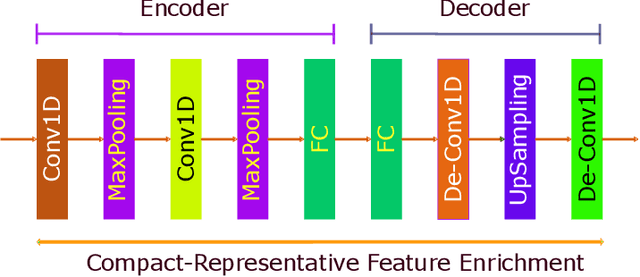
Multimodal dimensional emotion recognition has drawn a great attention from the affective computing community and numerous schemes have been extensively investigated, making a significant progress in this area. However, several questions still remain unanswered for most of existing approaches including: (i) how to simultaneously learn compact yet representative features from multimodal data, (ii) how to effectively capture complementary features from multimodal streams, and (iii) how to perform all the tasks in an end-to-end manner. To address these challenges, in this paper, we propose a novel deep neural network architecture consisting of a two-stream auto-encoder and a long short term memory for effectively integrating visual and audio signal streams for emotion recognition. To validate the robustness of our proposed architecture, we carry out extensive experiments on the multimodal emotion in the wild dataset: RECOLA. Experimental results show that the proposed method achieves state-of-the-art recognition performance and surpasses existing schemes by a significant margin.
Joint Deep Cross-Domain Transfer Learning for Emotion Recognition
Mar 24, 2020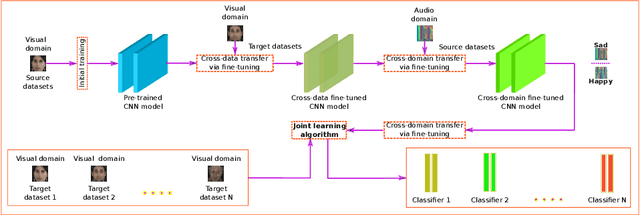
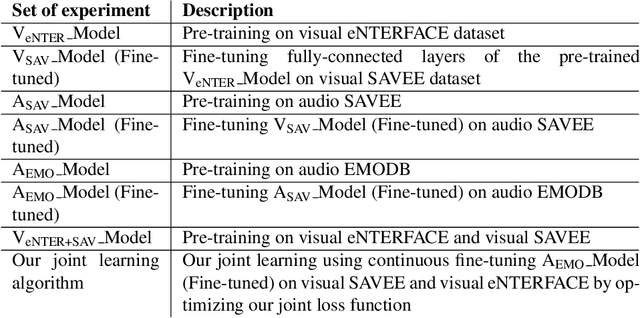
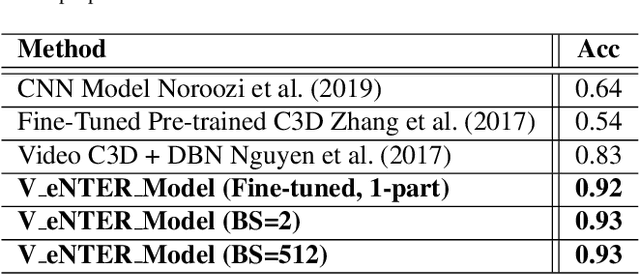
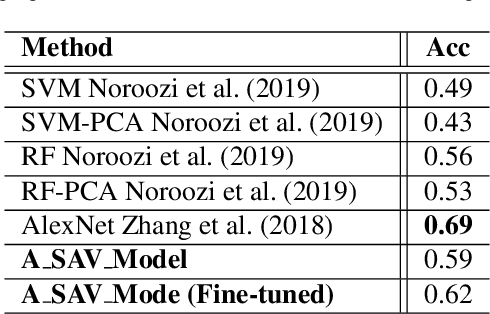
Deep learning has been applied to achieve significant progress in emotion recognition. Despite such substantial progress, existing approaches are still hindered by insufficient training data, and the resulting models do not generalize well under mismatched conditions. To address this challenge, we propose a learning strategy which jointly transfers the knowledge learned from rich datasets to source-poor datasets. Our method is also able to learn cross-domain features which lead to improved recognition performance. To demonstrate the robustness of our proposed framework, we conducted experiments on three benchmark emotion datasets including eNTERFACE, SAVEE, and EMODB. Experimental results show that the proposed method surpassed state-of-the-art transfer learning schemes by a significant margin.