 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficiency of Pre-training with Objective Masking in Pseudo Labeling for Semi-Supervised Text Classification
May 10, 2025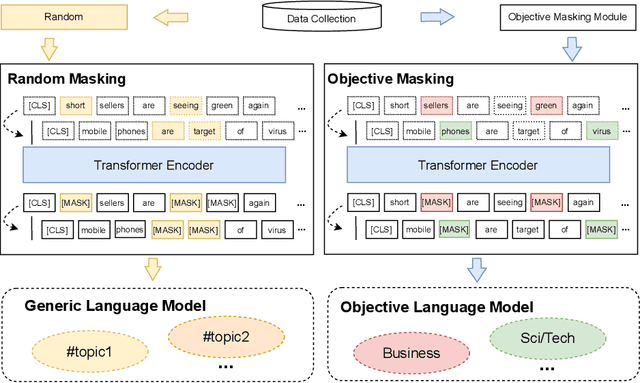

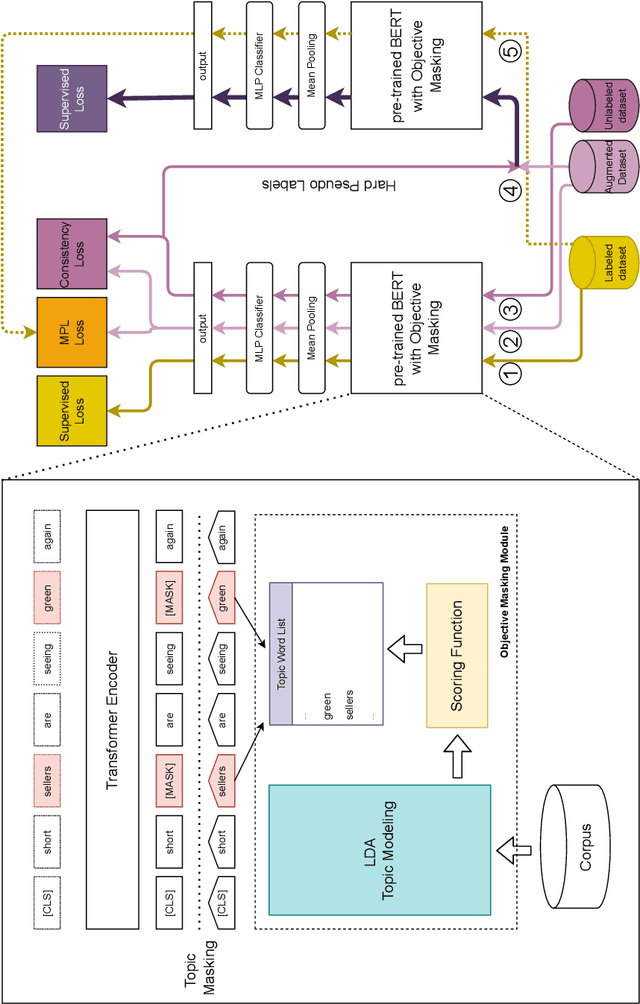

We extend and study a semi-supervised model for text classification proposed earlier by Hatefi et al. for classification tasks in which document classes are described by a small number of gold-labeled examples, while the majority of training examples is unlabeled. The model leverages the teacher-student architecture of Meta Pseudo Labels in which a ''teacher'' generates labels for originally unlabeled training data to train the ''student'' and updates its own model iteratively based on the performance of the student on the gold-labeled portion of the data. We extend the original model of Hatefi et al. by an unsupervised pre-training phase based on objective masking, and conduct in-depth performance evaluations of the original model, our extension, and various independent baselines. Experiments are performed using three different datasets in two different languages (English and Swedish).
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024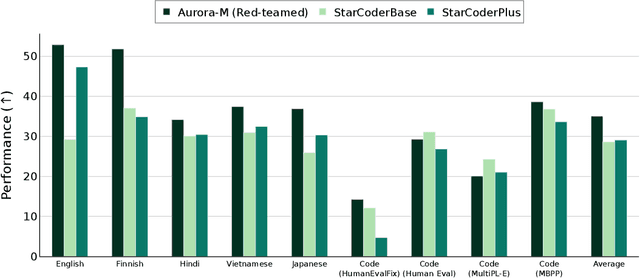

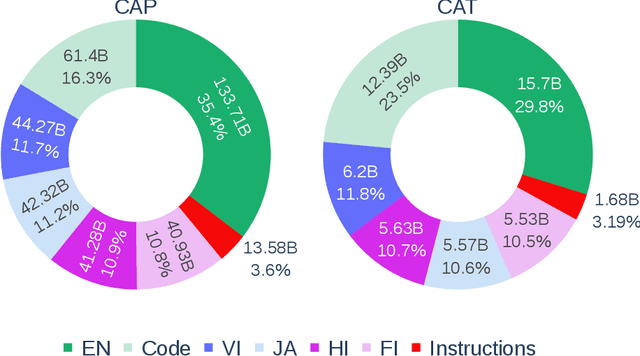
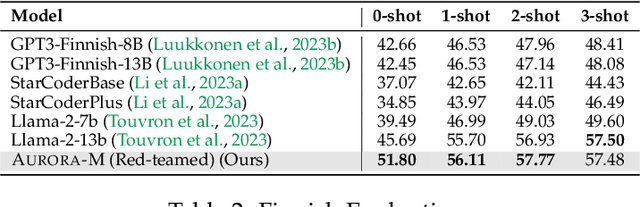
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Multimodal Graph Learning for Modeling Emerging Pandemics with Big Data
Oct 23, 2023Accurate forecasting and analysis of emerging pandemics play a crucial role in effective public health management and decision-making. Traditional approaches primarily rely on epidemiological data, overlooking other valuable sources of information that could act as sensors or indicators of pandemic patterns. In this paper, we propose a novel framework called MGL4MEP that integrates temporal graph neural networks and multi-modal data for learning and forecasting. We incorporate big data sources, including social media content, by utilizing specific pre-trained language models and discovering the underlying graph structure among users. This integration provides rich indicators of pandemic dynamics through learning with temporal graph neural networks. Extensive experiments demonstrate the effectiveness of our framework in pandemic forecasting and analysis, outperforming baseline methods across different areas, pandemic situations, and prediction horizons. The fusion of temporal graph learning and multi-modal data enables a comprehensive understanding of the pandemic landscape with less time lag, cheap cost, and more potential information indicators.
Grandma Karl is 27 years old -- research agenda for pseudonymization of research data
Aug 30, 2023

Accessibility of research data is critical for advances in many research fields, but textual data often cannot be shared due to the personal and sensitive information which it contains, e.g names or political opinions. General Data Protection Regulation (GDPR) suggests pseudonymization as a solution to secure open access to research data, but we need to learn more about pseudonymization as an approach before adopting it for manipulation of research data. This paper outlines a research agenda within pseudonymization, namely need of studies into the effects of pseudonymization on unstructured data in relation to e.g. readability and language assessment, as well as the effectiveness of pseudonymization as a way of protecting writer identity, while also exploring different ways of developing context-sensitive algorithms for detection, labelling and replacement of personal information in unstructured data. The recently granted project on pseudonymization Grandma Karl is 27 years old addresses exactly those challenges.
ReINTEL: A Multimodal Data Challenge for Responsible Information Identification on Social Network Sites
Dec 16, 2020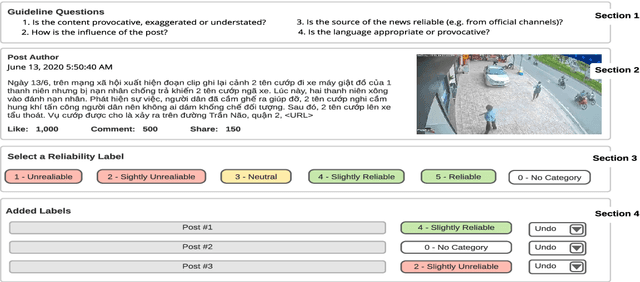
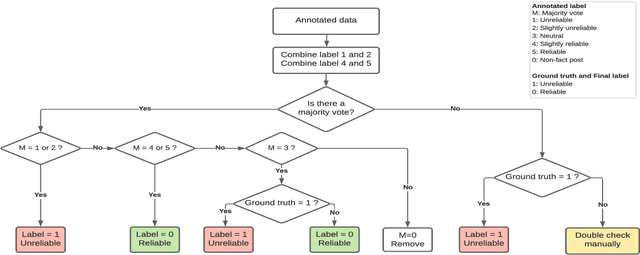

This paper reports on the ReINTEL Shared Task for Responsible Information Identification on social network sites, which is hosted at the seventh annual workshop on Vietnamese Language and Speech Processing (VLSP 2020). Given a piece of news with respective textual, visual content and metadata, participants are required to classify whether the news is `reliable' or `unreliable'. In order to generate a fair benchmark, we introduce a novel human-annotated dataset of over 10,000 news collected from a social network in Vietnam. All models will be evaluated in terms of AUC-ROC score, a typical evaluation metric for classification. The competition was run on the Codalab platform. Within two months, the challenge has attracted over 60 participants and recorded nearly 1,000 submission entries.
HSD Shared Task in VLSP Campaign 2019:Hate Speech Detection for Social Good
Jul 13, 2020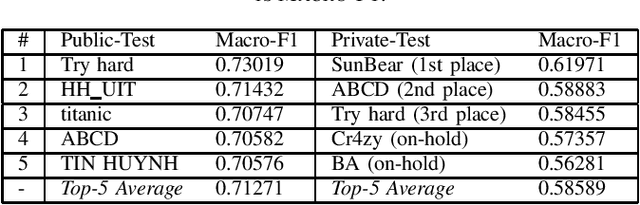

The paper describes the organisation of the "HateSpeech Detection" (HSD) task at the VLSP workshop 2019 on detecting the fine-grained presence of hate speech in Vietnamese textual items (i.e., messages) extracted from Facebook, which is the most popular social network site (SNS) in Vietnam. The task is organised as a multi-class classification task and based on a large-scale dataset containing 25,431 Vietnamese textual items from Facebook. The task participants were challenged to build a classification model that is capable of classifying an item to one of 3 classes, i.e., "HATE", "OFFENSIVE" and "CLEAN". HSD attracted a large number of participants and was a popular task at VLSP 2019. In particular, there were 71 teams signed up for the task, 14 of them submitted results with 380 valid submissions from 20th September 2019 to 4th October 2019.
Reinforced Data Sampling for Model Diversification
Jun 12, 2020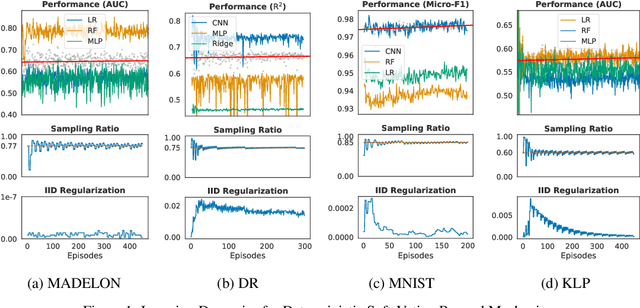
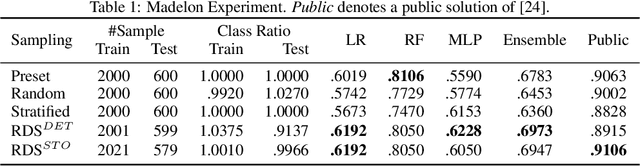
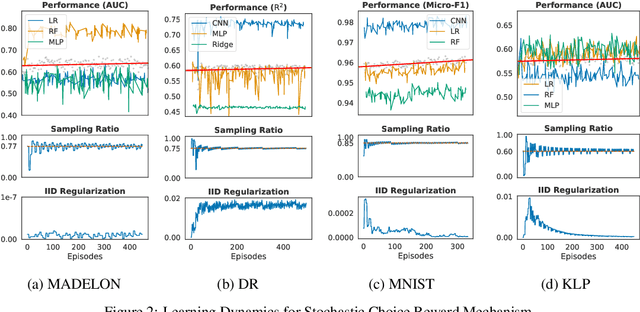
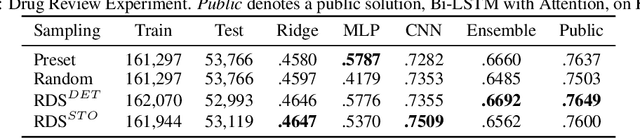
With the rising number of machine learning competitions, the world has witnessed an exciting race for the best algorithms. However, the involved data selection process may fundamentally suffer from evidence ambiguity and concept drift issues, thereby possibly leading to deleterious effects on the performance of various models. This paper proposes a new Reinforced Data Sampling (RDS) method to learn how to sample data adequately on the search for useful models and insights. We formulate the optimisation problem of model diversification $\delta{-div}$ in data sampling to maximise learning potentials and optimum allocation by injecting model diversity. This work advocates the employment of diverse base learners as value functions such as neural networks, decision trees, or logistic regressions to reinforce the selection process of data subsets with multi-modal belief. We introduce different ensemble reward mechanisms, including soft voting and stochastic choice to approximate optimal sampling policy. The evaluation conducted on four datasets evidently highlights the benefits of using RDS method over traditional sampling approaches. Our experimental results suggest that the trainable sampling for model diversification is useful for competition organisers, researchers, or even starters to pursue full potentials of various machine learning tasks such as classification and regression. The source code is available at https://github.com/probeu/RDS.
Generic Multilayer Network Data Analysis with the Fusion of Content and Structure
May 21, 2019

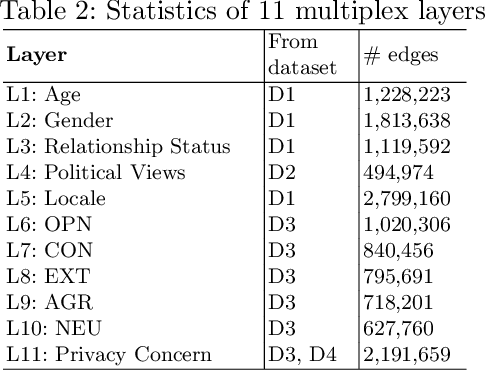
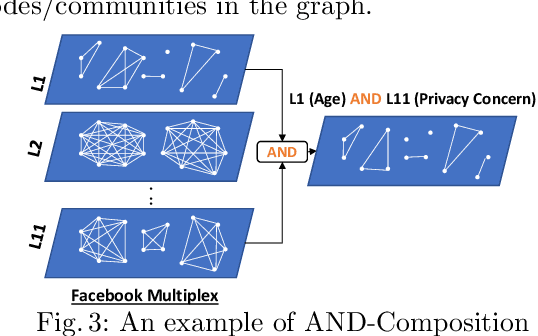
Multi-feature data analysis (e.g., on Facebook, LinkedIn) is challenging especially if one wants to do it efficiently and retain the flexibility by choosing features of interest for analysis. Features (e.g., age, gender, relationship, political view etc.) can be explicitly given from datasets, but also can be derived from content (e.g., political view based on Facebook posts). Analysis from multiple perspectives is needed to understand the datasets (or subsets of it) and to infer meaningful knowledge. For example, the influence of age, location, and marital status on political views may need to be inferred separately (or in combination). In this paper, we adapt multilayer network (MLN) analysis, a nontraditional approach, to model the Facebook datasets, integrate content analysis, and conduct analysis, which is driven by a list of desired application based queries. Our experimental analysis shows the flexibility and efficiency of the proposed approach when modeling and analyzing datasets with multiple features.
* 18 pages
dpUGC: Learn Differentially Private Representation for User Generated Contents
Mar 25, 2019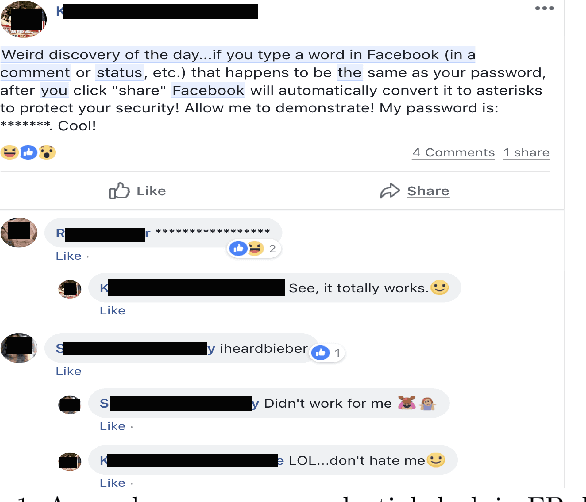
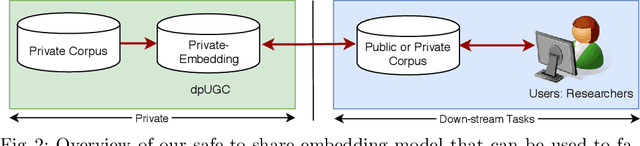

This paper firstly proposes a simple yet efficient generalized approach to apply differential privacy to text representation (i.e., word embedding). Based on it, we propose a user-level approach to learn personalized differentially private word embedding model on user generated contents (UGC). To our best knowledge, this is the first work of learning user-level differentially private word embedding model from text for sharing. The proposed approaches protect the privacy of the individual from re-identification, especially provide better trade-off of privacy and data utility on UGC data for sharing. The experimental results show that the trained embedding models are applicable for the classic text analysis tasks (e.g., regression). Moreover, the proposed approaches of learning differentially private embedding models are both framework- and data- independent, which facilitates the deployment and sharing. The source code is available at https://github.com/sonvx/dpText.
ETNLP: A Toolkit for Extraction, Evaluation and Visualization of Pre-trained Word Embeddings
Mar 11, 2019


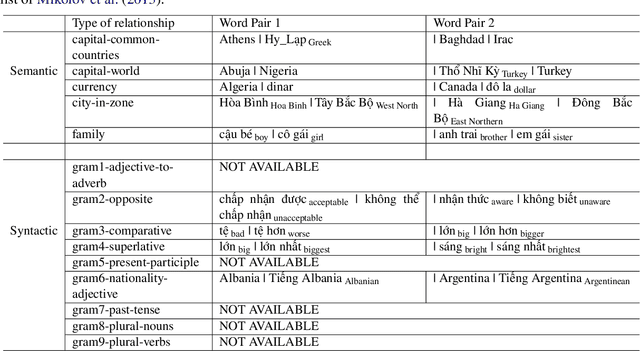
In this paper, we introduce a comprehensive toolkit, ETNLP, which can evaluate, extract, and visualize multiple sets of pre-trained word embeddings. First, for evaluation, ETNLP analyses the quality of pre-trained embeddings based on an input word analogy list. Second, for extraction ETNLP provides a subset of the embeddings to be used in the downstream NLP tasks. Finally, ETNLP has a visualization module which is for exploring the embedded words interactively. We demonstrate the effectiveness of ETNLP on our pre-trained word embeddings in Vietnamese. Specifically, we create a large Vietnamese word analogy list to evaluate the embeddings. We then utilize the pre-trained embeddings for the name entity recognition (NER) task in Vietnamese and achieve the new state-of-the-art results on a benchmark dataset for the NER task. A video demonstration of ETNLP is available at https://vimeo.com/317599106. The source code and data are available at https: //github.com/vietnlp/etnlp.