 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the VLSP 2023 -- ComOM Shared Task: A Data Challenge for Comparative Opinion Mining from Vietnamese Product Reviews
Feb 21, 2024



This paper presents a comprehensive overview of the Comparative Opinion Mining from Vietnamese Product Reviews shared task (ComOM), held as part of the 10$^{th}$ International Workshop on Vietnamese Language and Speech Processing (VLSP 2023). The primary objective of this shared task is to advance the field of natural language processing by developing techniques that proficiently extract comparative opinions from Vietnamese product reviews. Participants are challenged to propose models that adeptly extract a comparative "quintuple" from a comparative sentence, encompassing Subject, Object, Aspect, Predicate, and Comparison Type Label. We construct a human-annotated dataset comprising $120$ documents, encompassing $7427$ non-comparative sentences and $2468$ comparisons within $1798$ sentences. Participating models undergo evaluation and ranking based on the Exact match macro-averaged quintuple F1 score.
Overview of the VLSP 2022 -- Abmusu Shared Task: A Data Challenge for Vietnamese Abstractive Multi-document Summarization
Nov 27, 2023This paper reports the overview of the VLSP 2022 - Vietnamese abstractive multi-document summarization (Abmusu) shared task for Vietnamese News. This task is hosted at the 9$^{th}$ annual workshop on Vietnamese Language and Speech Processing (VLSP 2022). The goal of Abmusu shared task is to develop summarization systems that could create abstractive summaries automatically for a set of documents on a topic. The model input is multiple news documents on the same topic, and the corresponding output is a related abstractive summary. In the scope of Abmusu shared task, we only focus on Vietnamese news summarization and build a human-annotated dataset of 1,839 documents in 600 clusters, collected from Vietnamese news in 8 categories. Participated models are evaluated and ranked in terms of \texttt{ROUGE2-F1} score, the most typical evaluation metric for document summarization problem.
HSD Shared Task in VLSP Campaign 2019:Hate Speech Detection for Social Good
Jul 13, 2020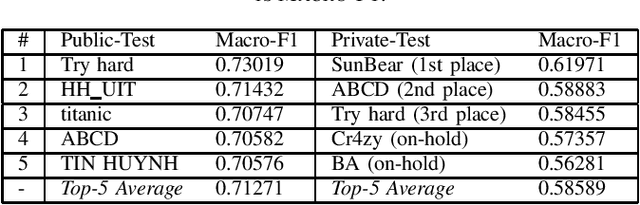

The paper describes the organisation of the "HateSpeech Detection" (HSD) task at the VLSP workshop 2019 on detecting the fine-grained presence of hate speech in Vietnamese textual items (i.e., messages) extracted from Facebook, which is the most popular social network site (SNS) in Vietnam. The task is organised as a multi-class classification task and based on a large-scale dataset containing 25,431 Vietnamese textual items from Facebook. The task participants were challenged to build a classification model that is capable of classifying an item to one of 3 classes, i.e., "HATE", "OFFENSIVE" and "CLEAN". HSD attracted a large number of participants and was a popular task at VLSP 2019. In particular, there were 71 teams signed up for the task, 14 of them submitted results with 380 valid submissions from 20th September 2019 to 4th October 2019.