 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Without Saying: A Dataset and Benchmark for Implicit Comparative Opinion Mining from Same-User Reviews
Jan 20, 2026Existing studies on comparative opinion mining have mainly focused on explicit comparative expressions, which are uncommon in real-world reviews. This leaves implicit comparisons - here users express preferences across separate reviews - largely underexplored. We introduce SUDO, a novel dataset for implicit comparative opinion mining from same-user reviews, allowing reliable inference of user preferences even without explicit comparative cues. SUDO comprises 4,150 annotated review pairs (15,191 sentences) with a bi-level structure capturing aspect-level mentions and review-level preferences. We benchmark this task using two baseline architectures: traditional machine learning- and language model-based baselines. Experimental results show that while the latter outperforms the former, overall performance remains moderate, revealing the inherent difficulty of the task and establishing SUDO as a challenging and valuable benchmark for future research.
UETQuintet at BioCreative IX -- MedHopQA: Enhancing Biomedical QA with Selective Multi-hop Reasoning and Contextual Retrieval
Jan 11, 2026Biomedical Question Answering systems play a critical role in processing complex medical queries, yet they often struggle with the intricate nature of medical data and the demand for multi-hop reasoning. In this paper, we propose a model designed to effectively address both direct and sequential questions. While sequential questions are decomposed into a chain of sub-questions to perform reasoning across a chain of steps, direct questions are processed directly to ensure efficiency and minimise processing overhead. Additionally, we leverage multi-source information retrieval and in-context learning to provide rich, relevant context for generating answers. We evaluated our model on the BioCreative IX - MedHopQA Shared Task datasets. Our approach achieves an Exact Match score of 0.84, ranking second on the current leaderboard. These results highlight the model's capability to meet the challenges of Biomedical Question Answering, offering a versatile solution for advancing medical research and practice.
Multi-modal Adaptive Mixture of Experts for Cold-start Recommendation
Aug 11, 2025



Recommendation systems have faced significant challenges in cold-start scenarios, where new items with a limited history of interaction need to be effectively recommended to users. Though multimodal data (e.g., images, text, audio, etc.) offer rich information to address this issue, existing approaches often employ simplistic integration methods such as concatenation, average pooling, or fixed weighting schemes, which fail to capture the complex relationships between modalities. Our study proposes a novel Mixture of Experts (MoE) framework for multimodal cold-start recommendation, named MAMEX, which dynamically leverages latent representation from different modalities. MAMEX utilizes modality-specific expert networks and introduces a learnable gating mechanism that adaptively weights the contribution of each modality based on its content characteristics. This approach enables MAMEX to emphasize the most informative modalities for each item while maintaining robustness when certain modalities are less relevant or missing. Extensive experiments on benchmark datasets show that MAMEX outperforms state-of-the-art methods in cold-start scenarios, with superior accuracy and adaptability. For reproducibility, the code has been made available on Github https://github.com/L2R-UET/MAMEX.
Personalized Diffusion Model Reshapes Cold-Start Bundle Recommendation
May 20, 2025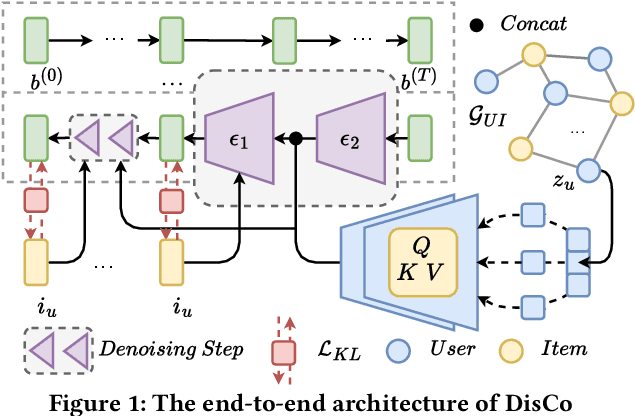
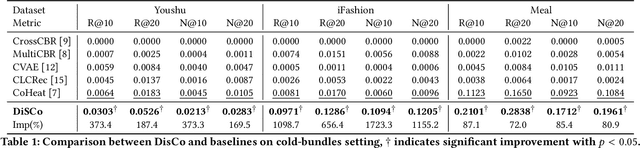
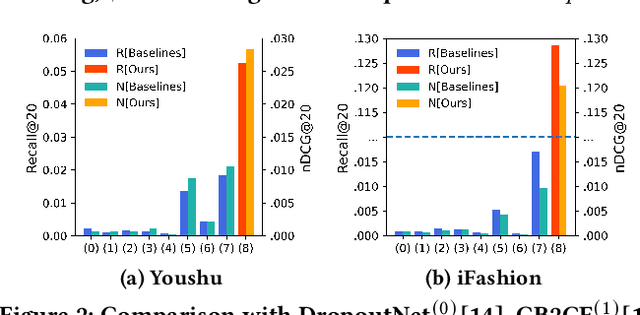
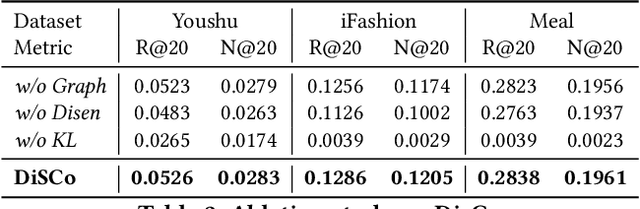
Bundle recommendation aims to recommend a set of items to each user. However, the sparser interactions between users and bundles raise a big challenge, especially in cold-start scenarios. Traditional collaborative filtering methods do not work well for this kind of problem because these models rely on interactions to update the latent embedding, which is hard to work in a cold-start setting. We propose a new approach (DisCo), which relies on a personalized Diffusion backbone, enhanced by disentangled aspects for the user's interest, to generate a bundle in distribution space for each user to tackle the cold-start challenge. During the training phase, DisCo adjusts an additional objective loss term to avoid bias, a prevalent issue while using the generative model for top-$K$ recommendation purposes. Our empirical experiments show that DisCo outperforms five comparative baselines by a large margin on three real-world datasets. Thereby, this study devises a promising framework and essential viewpoints in cold-start recommendation. Our materials for reproducibility are available at: https://github.com/bt-nghia/DisCo.
BRIDGE: Bundle Recommendation via Instruction-Driven Generation
Dec 24, 2024Bundle recommendation aims to suggest a set of interconnected items to users. However, diverse interaction types and sparse interaction matrices often pose challenges for previous approaches in accurately predicting user-bundle adoptions. Inspired by the distant supervision strategy and generative paradigm, we propose BRIDGE, a novel framework for bundle recommendation. It consists of two main components namely the correlation-based item clustering and the pseudo bundle generation modules. Inspired by the distant supervision approach, the former is to generate more auxiliary information, e.g., instructive item clusters, for training without using external data. This information is subsequently aggregated with collaborative signals from user historical interactions to create pseudo `ideal' bundles. This capability allows BRIDGE to explore all aspects of bundles, rather than being limited to existing real-world bundles. It effectively bridging the gap between user imagination and predefined bundles, hence improving the bundle recommendation performance. Experimental results validate the superiority of our models over state-of-the-art ranking-based methods across five benchmark datasets.
Bundle Recommendation with Item-level Causation-enhanced Multi-view Learning
Aug 13, 2024Bundle recommendation aims to enhance business profitability and user convenience by suggesting a set of interconnected items. In real-world scenarios, leveraging the impact of asymmetric item affiliations is crucial for effective bundle modeling and understanding user preferences. To address this, we present BunCa, a novel bundle recommendation approach employing item-level causation-enhanced multi-view learning. BunCa provides comprehensive representations of users and bundles through two views: the Coherent View, leveraging the Multi-Prospect Causation Network for causation-sensitive relations among items, and the Cohesive View, employing LightGCN for information propagation among users and bundles. Modeling user preferences and bundle construction combined from both views ensures rigorous cohesion in direct user-bundle interactions through the Cohesive View and captures explicit intents through the Coherent View. Simultaneously, the integration of concrete and discrete contrastive learning optimizes the consistency and self-discrimination of multi-view representations. Extensive experiments with BunCa on three benchmark datasets demonstrate the effectiveness of this novel research and validate our hypothesis.
Overview of the VLSP 2023 -- ComOM Shared Task: A Data Challenge for Comparative Opinion Mining from Vietnamese Product Reviews
Feb 21, 2024



This paper presents a comprehensive overview of the Comparative Opinion Mining from Vietnamese Product Reviews shared task (ComOM), held as part of the 10$^{th}$ International Workshop on Vietnamese Language and Speech Processing (VLSP 2023). The primary objective of this shared task is to advance the field of natural language processing by developing techniques that proficiently extract comparative opinions from Vietnamese product reviews. Participants are challenged to propose models that adeptly extract a comparative "quintuple" from a comparative sentence, encompassing Subject, Object, Aspect, Predicate, and Comparison Type Label. We construct a human-annotated dataset comprising $120$ documents, encompassing $7427$ non-comparative sentences and $2468$ comparisons within $1798$ sentences. Participating models undergo evaluation and ranking based on the Exact match macro-averaged quintuple F1 score.
Overview of the VLSP 2022 -- Abmusu Shared Task: A Data Challenge for Vietnamese Abstractive Multi-document Summarization
Nov 27, 2023This paper reports the overview of the VLSP 2022 - Vietnamese abstractive multi-document summarization (Abmusu) shared task for Vietnamese News. This task is hosted at the 9$^{th}$ annual workshop on Vietnamese Language and Speech Processing (VLSP 2022). The goal of Abmusu shared task is to develop summarization systems that could create abstractive summaries automatically for a set of documents on a topic. The model input is multiple news documents on the same topic, and the corresponding output is a related abstractive summary. In the scope of Abmusu shared task, we only focus on Vietnamese news summarization and build a human-annotated dataset of 1,839 documents in 600 clusters, collected from Vietnamese news in 8 categories. Participated models are evaluated and ranked in terms of \texttt{ROUGE2-F1} score, the most typical evaluation metric for document summarization problem.