 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Adaptive Mixture of Experts for Cold-start Recommendation
Aug 11, 2025



Recommendation systems have faced significant challenges in cold-start scenarios, where new items with a limited history of interaction need to be effectively recommended to users. Though multimodal data (e.g., images, text, audio, etc.) offer rich information to address this issue, existing approaches often employ simplistic integration methods such as concatenation, average pooling, or fixed weighting schemes, which fail to capture the complex relationships between modalities. Our study proposes a novel Mixture of Experts (MoE) framework for multimodal cold-start recommendation, named MAMEX, which dynamically leverages latent representation from different modalities. MAMEX utilizes modality-specific expert networks and introduces a learnable gating mechanism that adaptively weights the contribution of each modality based on its content characteristics. This approach enables MAMEX to emphasize the most informative modalities for each item while maintaining robustness when certain modalities are less relevant or missing. Extensive experiments on benchmark datasets show that MAMEX outperforms state-of-the-art methods in cold-start scenarios, with superior accuracy and adaptability. For reproducibility, the code has been made available on Github https://github.com/L2R-UET/MAMEX.
Personalized Diffusion Model Reshapes Cold-Start Bundle Recommendation
May 20, 2025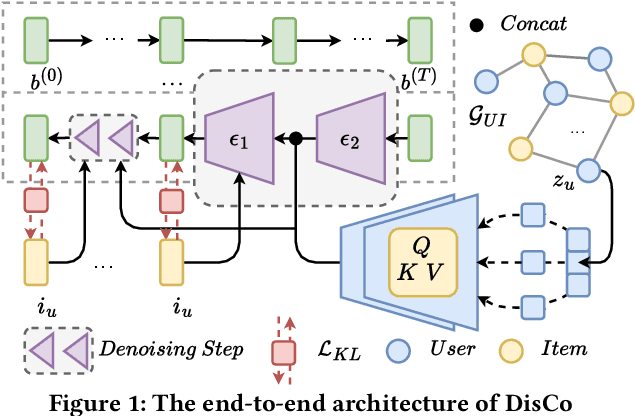
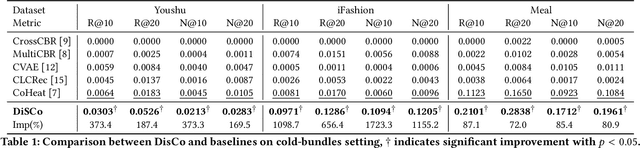
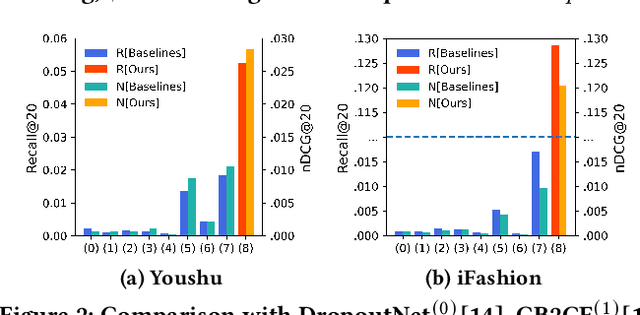
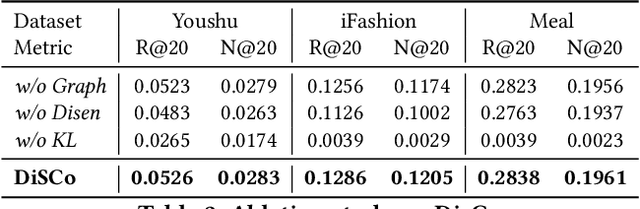
Bundle recommendation aims to recommend a set of items to each user. However, the sparser interactions between users and bundles raise a big challenge, especially in cold-start scenarios. Traditional collaborative filtering methods do not work well for this kind of problem because these models rely on interactions to update the latent embedding, which is hard to work in a cold-start setting. We propose a new approach (DisCo), which relies on a personalized Diffusion backbone, enhanced by disentangled aspects for the user's interest, to generate a bundle in distribution space for each user to tackle the cold-start challenge. During the training phase, DisCo adjusts an additional objective loss term to avoid bias, a prevalent issue while using the generative model for top-$K$ recommendation purposes. Our empirical experiments show that DisCo outperforms five comparative baselines by a large margin on three real-world datasets. Thereby, this study devises a promising framework and essential viewpoints in cold-start recommendation. Our materials for reproducibility are available at: https://github.com/bt-nghia/DisCo.
Comparative Opinion Mining in Product Reviews: Multi-perspective Prompt-based Learning
Dec 11, 2024
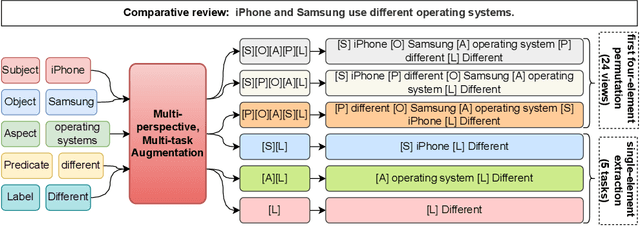

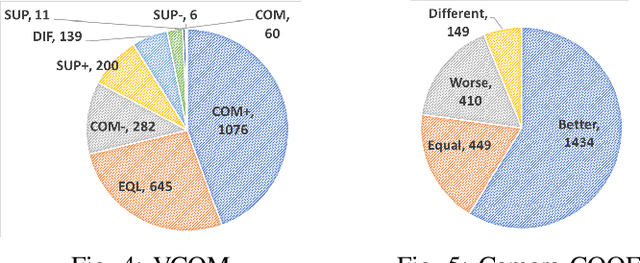
Comparative reviews are pivotal in understanding consumer preferences and influencing purchasing decisions. Comparative Quintuple Extraction (COQE) aims to identify five key components in text: the target entity, compared entities, compared aspects, opinions on these aspects, and polarity. Extracting precise comparative information from product reviews is challenging due to nuanced language and sequential task errors in traditional methods. To mitigate these problems, we propose MTP-COQE, an end-to-end model designed for COQE. Leveraging multi-perspective prompt-based learning, MTP-COQE effectively guides the generative model in comparative opinion mining tasks. Evaluation on the Camera-COQE (English) and VCOM (Vietnamese) datasets demonstrates MTP-COQE's efficacy in automating COQE, achieving superior performance with a 1.41% higher F1 score than the previous baseline models on the English dataset. Additionally, we designed a strategy to limit the generative model's creativity to ensure the output meets expectations. We also performed data augmentation to address data imbalance and to prevent the model from becoming biased towards dominant samples.
TECO: Improving Multimodal Intent Recognition with Text Enhancement through Commonsense Knowledge Extraction
Dec 11, 2024

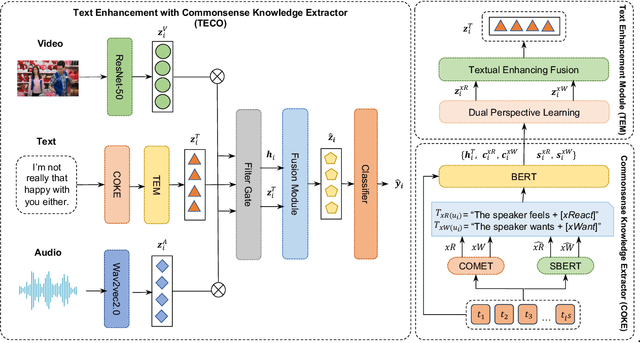
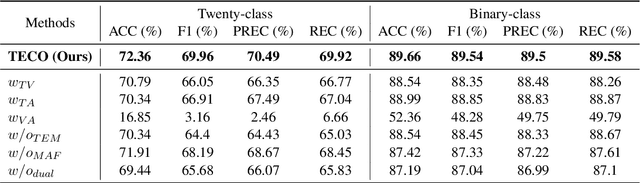
The objective of multimodal intent recognition (MIR) is to leverage various modalities-such as text, video, and audio-to detect user intentions, which is crucial for understanding human language and context in dialogue systems. Despite advances in this field, two main challenges persist: (1) effectively extracting and utilizing semantic information from robust textual features; (2) aligning and fusing non-verbal modalities with verbal ones effectively. This paper proposes a Text Enhancement with CommOnsense Knowledge Extractor (TECO) to address these challenges. We begin by extracting relations from both generated and retrieved knowledge to enrich the contextual information in the text modality. Subsequently, we align and integrate visual and acoustic representations with these enhanced text features to form a cohesive multimodal representation. Our experimental results show substantial improvements over existing baseline methods.
A Dual-Module Denoising Approach with Curriculum Learning for Enhancing Multimodal Aspect-Based Sentiment Analysis
Dec 11, 2024

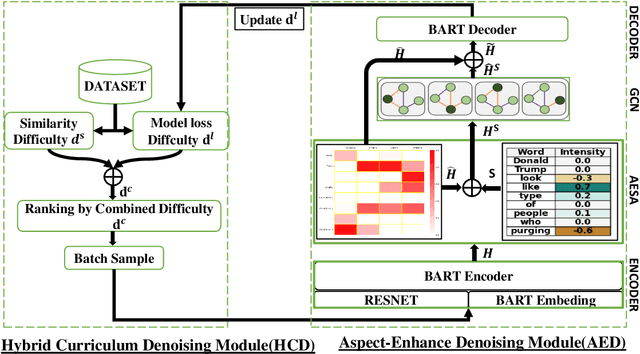
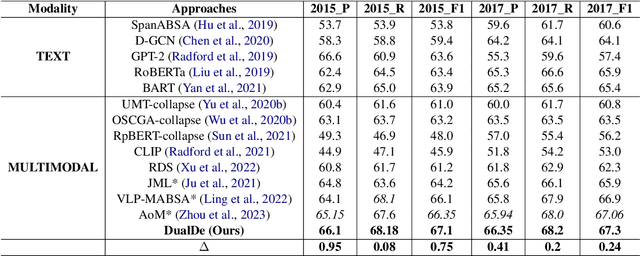
Multimodal Aspect-Based Sentiment Analysis (MABSA) combines text and images to perform sentiment analysis but often struggles with irrelevant or misleading visual information. Existing methodologies typically address either sentence-image denoising or aspect-image denoising but fail to comprehensively tackle both types of noise. To address these limitations, we propose DualDe, a novel approach comprising two distinct components: the Hybrid Curriculum Denoising Module (HCD) and the Aspect-Enhance Denoising Module (AED). The HCD module enhances sentence-image denoising by incorporating a flexible curriculum learning strategy that prioritizes training on clean data. Concurrently, the AED module mitigates aspect-image noise through an aspect-guided attention mechanism that filters out noisy visual regions which unrelated to the specific aspects of interest. Our approach demonstrates effectiveness in addressing both sentence-image and aspect-image noise, as evidenced by experimental evaluations on benchmark datasets.
Bundle Recommendation with Item-level Causation-enhanced Multi-view Learning
Aug 13, 2024Bundle recommendation aims to enhance business profitability and user convenience by suggesting a set of interconnected items. In real-world scenarios, leveraging the impact of asymmetric item affiliations is crucial for effective bundle modeling and understanding user preferences. To address this, we present BunCa, a novel bundle recommendation approach employing item-level causation-enhanced multi-view learning. BunCa provides comprehensive representations of users and bundles through two views: the Coherent View, leveraging the Multi-Prospect Causation Network for causation-sensitive relations among items, and the Cohesive View, employing LightGCN for information propagation among users and bundles. Modeling user preferences and bundle construction combined from both views ensures rigorous cohesion in direct user-bundle interactions through the Cohesive View and captures explicit intents through the Coherent View. Simultaneously, the integration of concrete and discrete contrastive learning optimizes the consistency and self-discrimination of multi-view representations. Extensive experiments with BunCa on three benchmark datasets demonstrate the effectiveness of this novel research and validate our hypothesis.
Curriculum Learning Meets Directed Acyclic Graph for Multimodal Emotion Recognition
Mar 08, 2024



Emotion recognition in conversation (ERC) is a crucial task in natural language processing and affective computing. This paper proposes MultiDAG+CL, a novel approach for Multimodal Emotion Recognition in Conversation (ERC) that employs Directed Acyclic Graph (DAG) to integrate textual, acoustic, and visual features within a unified framework. The model is enhanced by Curriculum Learning (CL) to address challenges related to emotional shifts and data imbalance. Curriculum learning facilitates the learning process by gradually presenting training samples in a meaningful order, thereby improving the model's performance in handling emotional variations and data imbalance. Experimental results on the IEMOCAP and MELD datasets demonstrate that the MultiDAG+CL models outperform baseline models. We release the code for MultiDAG+CL and experiments: https://github.com/vanntc711/MultiDAG-CL
Conversation Understanding using Relational Temporal Graph Neural Networks with Auxiliary Cross-Modality Interaction
Nov 08, 2023



Emotion recognition is a crucial task for human conversation understanding. It becomes more challenging with the notion of multimodal data, e.g., language, voice, and facial expressions. As a typical solution, the global- and the local context information are exploited to predict the emotional label for every single sentence, i.e., utterance, in the dialogue. Specifically, the global representation could be captured via modeling of cross-modal interactions at the conversation level. The local one is often inferred using the temporal information of speakers or emotional shifts, which neglects vital factors at the utterance level. Additionally, most existing approaches take fused features of multiple modalities in an unified input without leveraging modality-specific representations. Motivating from these problems, we propose the Relational Temporal Graph Neural Network with Auxiliary Cross-Modality Interaction (CORECT), an novel neural network framework that effectively captures conversation-level cross-modality interactions and utterance-level temporal dependencies with the modality-specific manner for conversation understanding. Extensive experiments demonstrate the effectiveness of CORECT via its state-of-the-art results on the IEMOCAP and CMU-MOSEI datasets for the multimodal ERC task.
Self-MI: Efficient Multimodal Fusion via Self-Supervised Multi-Task Learning with Auxiliary Mutual Information Maximization
Nov 07, 2023



Multimodal representation learning poses significant challenges in capturing informative and distinct features from multiple modalities. Existing methods often struggle to exploit the unique characteristics of each modality due to unified multimodal annotations. In this study, we propose Self-MI in the self-supervised learning fashion, which also leverage Contrastive Predictive Coding (CPC) as an auxiliary technique to maximize the Mutual Information (MI) between unimodal input pairs and the multimodal fusion result with unimodal inputs. Moreover, we design a label generation module, $ULG_{MI}$ for short, that enables us to create meaningful and informative labels for each modality in a self-supervised manner. By maximizing the Mutual Information, we encourage better alignment between the multimodal fusion and the individual modalities, facilitating improved multimodal fusion. Extensive experiments on three benchmark datasets including CMU-MOSI, CMU-MOSEI, and SIMS, demonstrate the effectiveness of Self-MI in enhancing the multimodal fusion task.
Vietnamese multi-document summary using subgraph selection approach -- VLSP 2022 AbMuSu Shared Task
Jun 26, 2023Document summarization is a task to generate afluent, condensed summary for a document, andkeep important information. A cluster of documents serves as the input for multi-document summarizing (MDS), while the cluster summary serves as the output. In this paper, we focus on transforming the extractive MDS problem into subgraph selection. Approaching the problem in the form of graphs helps to capture simultaneously the relationship between sentences in the same document and between sentences in the same cluster based on exploiting the overall graph structure and selected subgraphs. Experiments have been implemented on the Vietnamese dataset published in VLSP Evaluation Campaign 2022. This model currently results in the top 10 participating teams reported on the ROUGH-2 $F\_1$ measure on the public test set.