 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTECO: Improving Multimodal Intent Recognition with Text Enhancement through Commonsense Knowledge Extraction
Dec 11, 2024

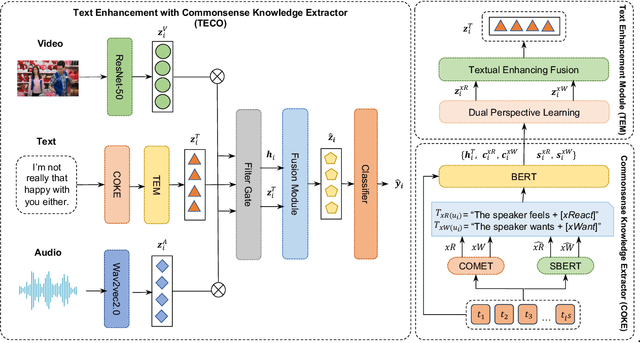
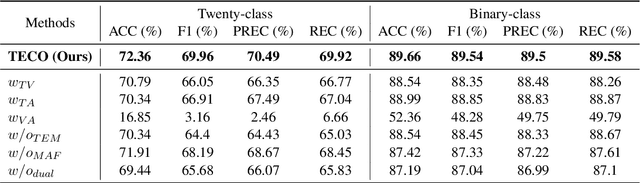
The objective of multimodal intent recognition (MIR) is to leverage various modalities-such as text, video, and audio-to detect user intentions, which is crucial for understanding human language and context in dialogue systems. Despite advances in this field, two main challenges persist: (1) effectively extracting and utilizing semantic information from robust textual features; (2) aligning and fusing non-verbal modalities with verbal ones effectively. This paper proposes a Text Enhancement with CommOnsense Knowledge Extractor (TECO) to address these challenges. We begin by extracting relations from both generated and retrieved knowledge to enrich the contextual information in the text modality. Subsequently, we align and integrate visual and acoustic representations with these enhanced text features to form a cohesive multimodal representation. Our experimental results show substantial improvements over existing baseline methods.