 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSD Shared Task in VLSP Campaign 2019:Hate Speech Detection for Social Good
Jul 13, 2020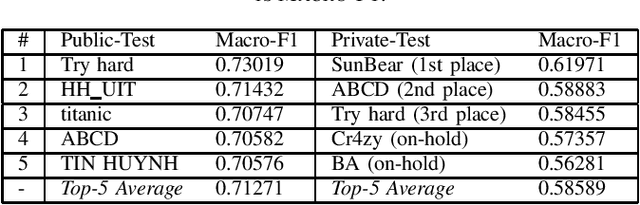

The paper describes the organisation of the "HateSpeech Detection" (HSD) task at the VLSP workshop 2019 on detecting the fine-grained presence of hate speech in Vietnamese textual items (i.e., messages) extracted from Facebook, which is the most popular social network site (SNS) in Vietnam. The task is organised as a multi-class classification task and based on a large-scale dataset containing 25,431 Vietnamese textual items from Facebook. The task participants were challenged to build a classification model that is capable of classifying an item to one of 3 classes, i.e., "HATE", "OFFENSIVE" and "CLEAN". HSD attracted a large number of participants and was a popular task at VLSP 2019. In particular, there were 71 teams signed up for the task, 14 of them submitted results with 380 valid submissions from 20th September 2019 to 4th October 2019.