 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentEval: Generative Agents as Reliable Proxies for Human Evaluation of AI-Generated Content
Dec 09, 2025Modern businesses are increasingly challenged by the time and expense required to generate and assess high-quality content. Human writers face time constraints, and extrinsic evaluations can be costly. While Large Language Models (LLMs) offer potential in content creation, concerns about the quality of AI-generated content persist. Traditional evaluation methods, like human surveys, further add operational costs, highlighting the need for efficient, automated solutions. This research introduces Generative Agents as a means to tackle these challenges. These agents can rapidly and cost-effectively evaluate AI-generated content, simulating human judgment by rating aspects such as coherence, interestingness, clarity, fairness, and relevance. By incorporating these agents, businesses can streamline content generation and ensure consistent, high-quality output while minimizing reliance on costly human evaluations. The study provides critical insights into enhancing LLMs for producing business-aligned, high-quality content, offering significant advancements in automated content generation and evaluation.
MedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
LossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023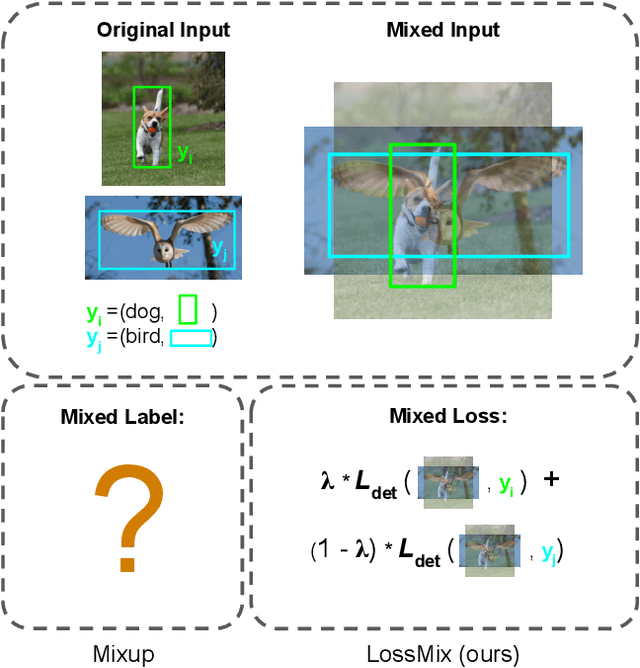
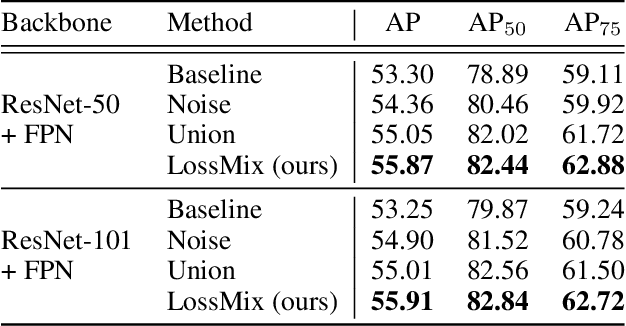
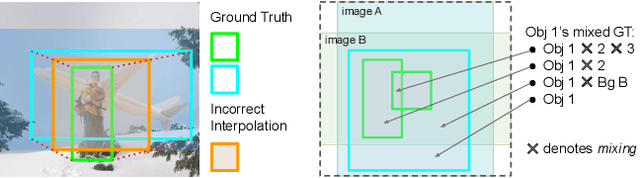
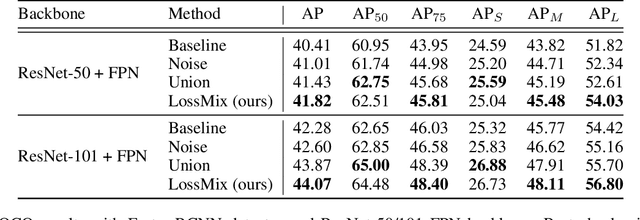
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
Toward Edge-Efficient Dense Predictions with Synergistic Multi-Task Neural Architecture Search
Oct 04, 2022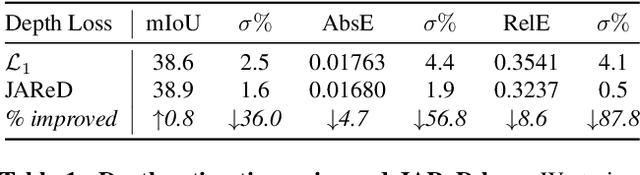

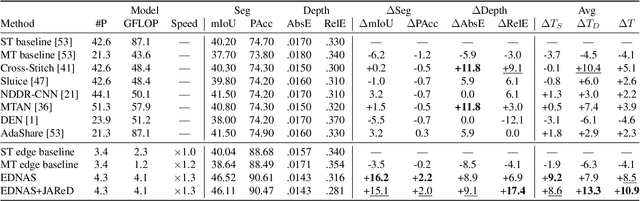
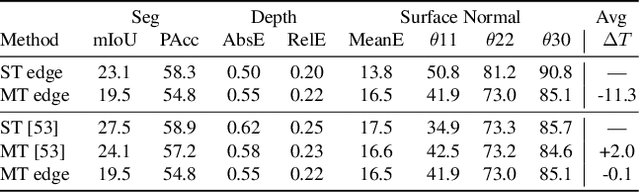
In this work, we propose a novel and scalable solution to address the challenges of developing efficient dense predictions on edge platforms. Our first key insight is that MultiTask Learning (MTL) and hardware-aware Neural Architecture Search (NAS) can work in synergy to greatly benefit on-device Dense Predictions (DP). Empirical results reveal that the joint learning of the two paradigms is surprisingly effective at improving DP accuracy, achieving superior performance over both the transfer learning of single-task NAS and prior state-of-the-art approaches in MTL, all with just 1/10th of the computation. To the best of our knowledge, our framework, named EDNAS, is the first to successfully leverage the synergistic relationship of NAS and MTL for DP. Our second key insight is that the standard depth training for multi-task DP can cause significant instability and noise to MTL evaluation. Instead, we propose JAReD, an improved, easy-to-adopt Joint Absolute-Relative Depth loss, that reduces up to 88% of the undesired noise while simultaneously boosting accuracy. We conduct extensive evaluations on standard datasets, benchmark against strong baselines and state-of-the-art approaches, as well as provide an analysis of the discovered optimal architectures.
Automatic Post-Editing for Translating Chinese Novels to Vietnamese
Apr 25, 2021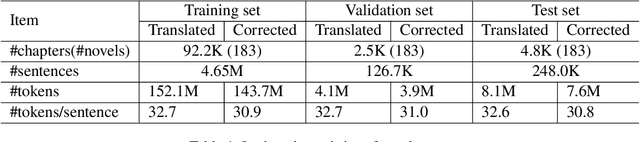
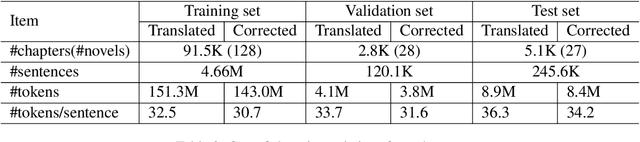
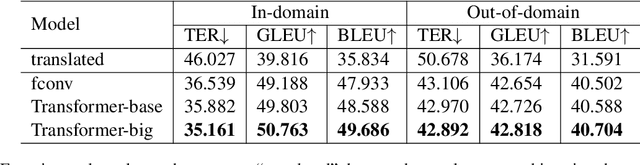
Automatic post-editing (APE) is an important remedy for reducing errors of raw translated texts that are produced by machine translation (MT) systems or software-aided translation. In this paper, we present the first attempt to tackle the APE task for Vietnamese. Specifically, we construct the first large-scale dataset of 5M Vietnamese translated and corrected sentence pairs. We then apply strong neural MT models to handle the APE task, using our constructed dataset. Experimental results from both automatic and human evaluations show the effectiveness of the neural MT models in handling the Vietnamese APE task.
Any-Width Networks
Dec 06, 2020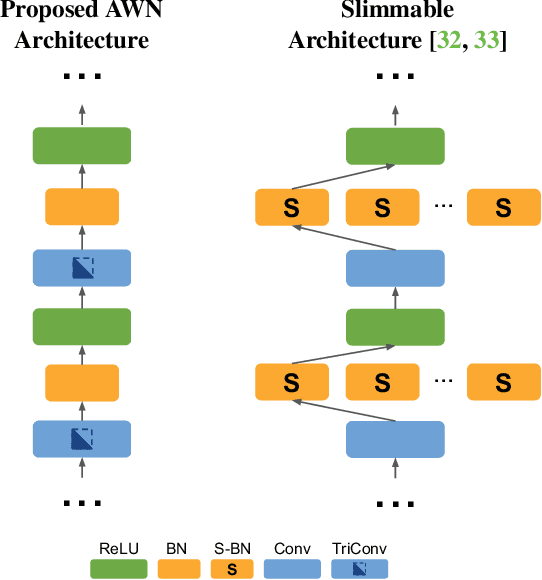

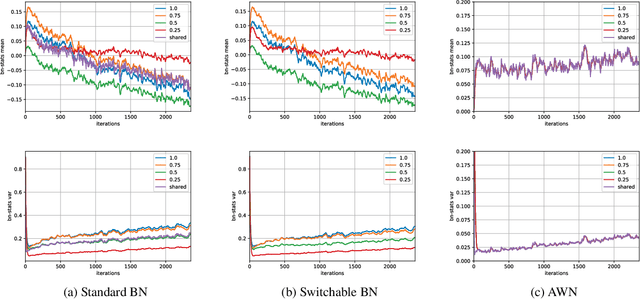

Despite remarkable improvements in speed and accuracy, convolutional neural networks (CNNs) still typically operate as monolithic entities at inference time. This poses a challenge for resource-constrained practical applications, where both computational budgets and performance needs can vary with the situation. To address these constraints, we propose the Any-Width Network (AWN), an adjustable-width CNN architecture and associated training routine that allow for fine-grained control over speed and accuracy during inference. Our key innovation is the use of lower-triangular weight matrices which explicitly address width-varying batch statistics while being naturally suited for multi-width operations. We also show that this design facilitates an efficient training routine based on random width sampling. We empirically demonstrate that our proposed AWNs compare favorably to existing methods while providing maximally granular control during inference.
Active and Interactive Mapping with Dynamic Gaussian ProcessImplicit Surfaces for Mobile Manipulators
Oct 25, 2020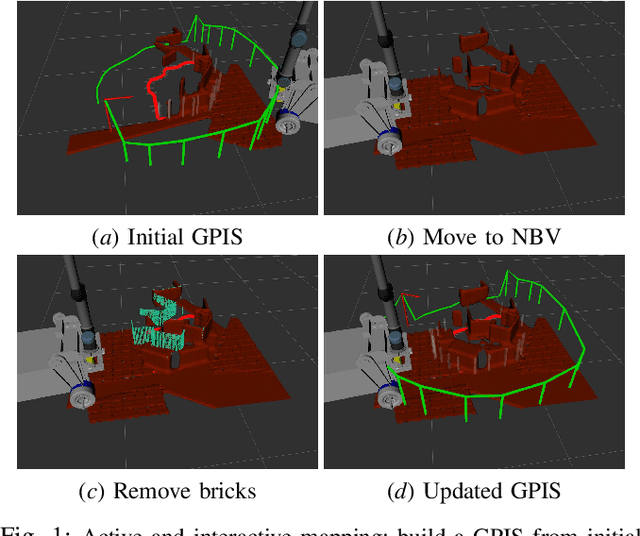

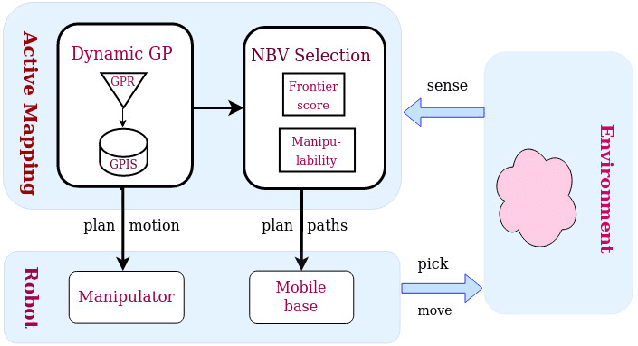

In this paper, we present an interactive probabilistic framework for a mobile manipulator which moves in the environment, makes changes and maps the changing scene alongside. The framework is motivated by interactive robotic applications found in warehouses, construction sites and additive manufacturing, where a mobile robot manipulates objects in the scene. The proposed framework uses a novel dynamic Gaussian Process (GP) Implicit Surface method to incrementally build and update the scene map that reflects environment changes. Actively the framework provides the next-best-view (NBV), balancing the need of pick object reach-ability and map's information gain (IG). To enforce a priority of visiting boundary segments over unknown regions, the IG formulation includes an uncertainty gradient based frontier score by exploiting the GP kernel derivative. This leads to an efficient strategy that addresses the often conflicting requirement of unknown environment exploration and object picking exploitation given a limited execution horizon. We demonstrate the effectiveness of our framework with software simulation and real-life experiments.
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020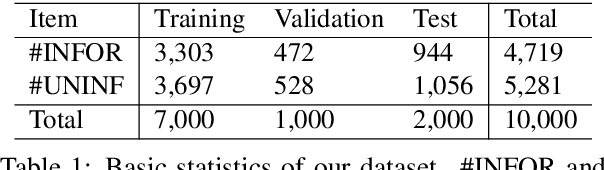
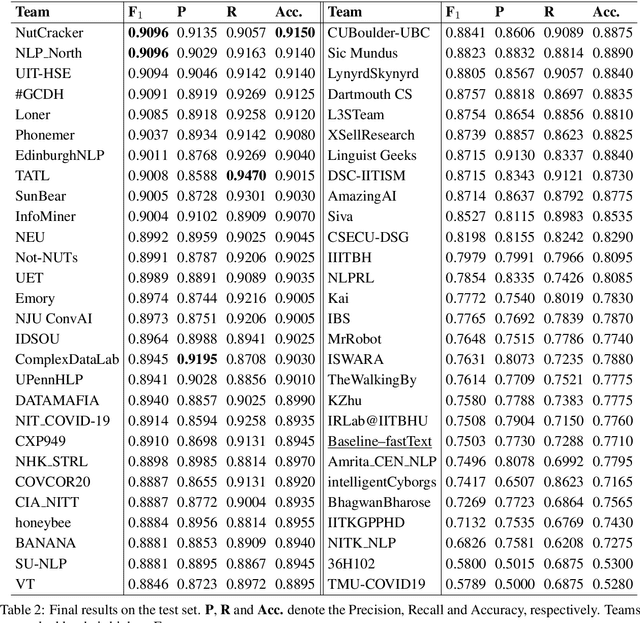
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.
QuatRE: Relation-Aware Quaternions for Knowledge Graph Embeddings
Sep 26, 2020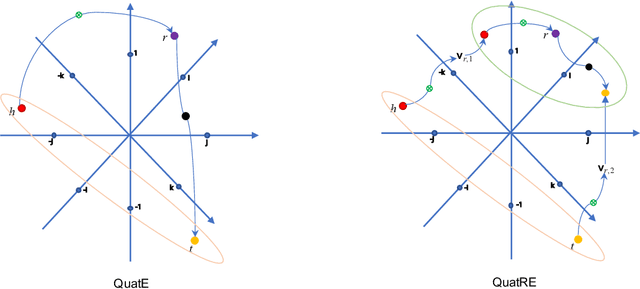
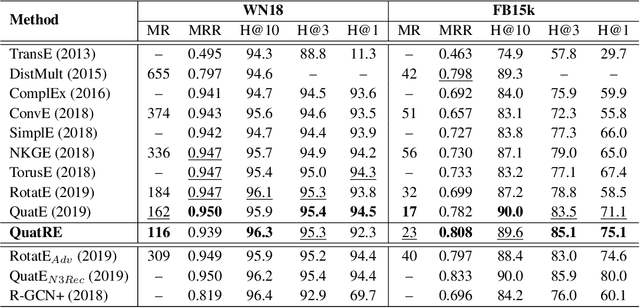
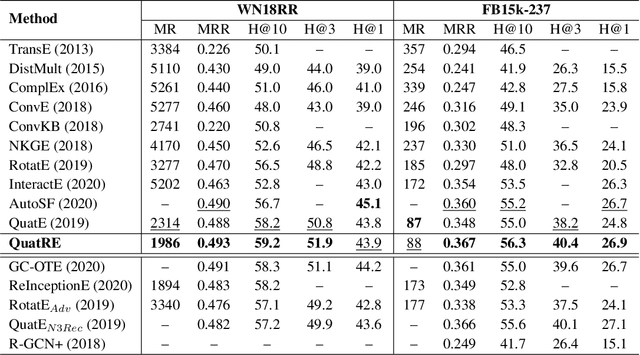
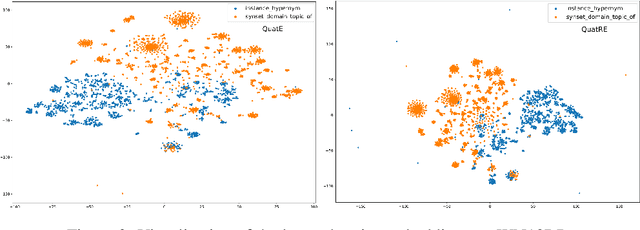
We propose a simple and effective embedding model, named QuatRE, to learn quaternion embeddings for entities and relations in knowledge graphs. QuatRE aims to enhance correlations between head and tail entities given a relation within the Quaternion space with Hamilton product. QuatRE achieves this by associating each relation with two quaternion vectors which are used to rotate the quaternion embeddings of the head and tail entities, respectively. To obtain the triple score, QuatRE rotates the rotated embedding of the head entity using the normalized quaternion embedding of the relation, followed by a quaternion-inner product with the rotated embedding of the tail entity. Experimental results show that our QuatRE outperforms up-to-date embedding models on well-known benchmark datasets for knowledge graph completion.
HSD Shared Task in VLSP Campaign 2019:Hate Speech Detection for Social Good
Jul 13, 2020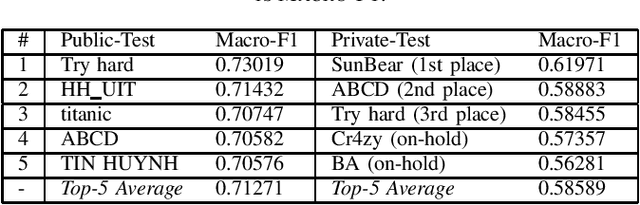

The paper describes the organisation of the "HateSpeech Detection" (HSD) task at the VLSP workshop 2019 on detecting the fine-grained presence of hate speech in Vietnamese textual items (i.e., messages) extracted from Facebook, which is the most popular social network site (SNS) in Vietnam. The task is organised as a multi-class classification task and based on a large-scale dataset containing 25,431 Vietnamese textual items from Facebook. The task participants were challenged to build a classification model that is capable of classifying an item to one of 3 classes, i.e., "HATE", "OFFENSIVE" and "CLEAN". HSD attracted a large number of participants and was a popular task at VLSP 2019. In particular, there were 71 teams signed up for the task, 14 of them submitted results with 380 valid submissions from 20th September 2019 to 4th October 2019.