 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurateRAG: A Framework for Building Accurate Retrieval-Augmented Question-Answering Applications
Oct 02, 2025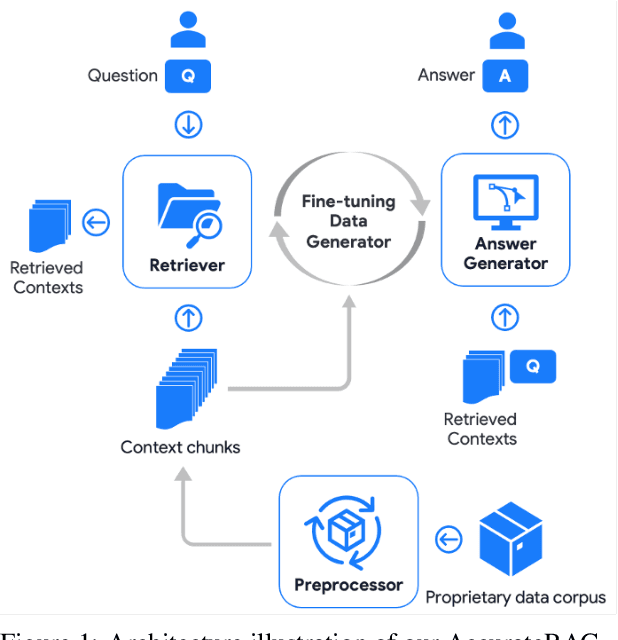

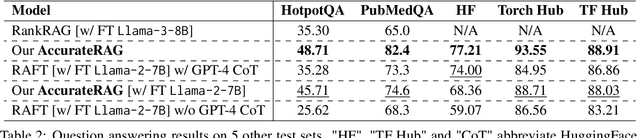
We introduce AccurateRAG -- a novel framework for constructing high-performance question-answering applications based on retrieval-augmented generation (RAG). Our framework offers a pipeline for development efficiency with tools for raw dataset processing, fine-tuning data generation, text embedding & LLM fine-tuning, output evaluation, and building RAG systems locally. Experimental results show that our framework outperforms previous strong baselines and obtains new state-of-the-art question-answering performance on benchmark datasets.
PhoGPT: Generative Pre-training for Vietnamese
Nov 06, 2023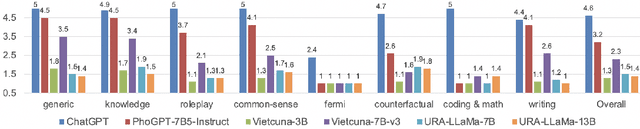
We open-source a state-of-the-art 7.5B-parameter generative model series named PhoGPT for Vietnamese, which includes the base pre-trained monolingual model PhoGPT-7B5 and its instruction-following variant, PhoGPT-7B5-Instruct. In addition, we also demonstrate its superior performance compared to previous open-source models through a human evaluation experiment. GitHub: https://github.com/VinAIResearch/PhoGPT
XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
May 31, 2023We present XPhoneBERT, the first multilingual model pre-trained to learn phoneme representations for the downstream text-to-speech (TTS) task. Our XPhoneBERT has the same model architecture as BERT-base, trained using the RoBERTa pre-training approach on 330M phoneme-level sentences from nearly 100 languages and locales. Experimental results show that employing XPhoneBERT as an input phoneme encoder significantly boosts the performance of a strong neural TTS model in terms of naturalness and prosody and also helps produce fairly high-quality speech with limited training data. We publicly release our pre-trained XPhoneBERT with the hope that it would facilitate future research and downstream TTS applications for multiple languages. Our XPhoneBERT model is available at https://github.com/VinAIResearch/XPhoneBERT
A High-Quality and Large-Scale Dataset for English-Vietnamese Speech Translation
Aug 08, 2022


In this paper, we introduce a high-quality and large-scale benchmark dataset for English-Vietnamese speech translation with 508 audio hours, consisting of 331K triplets of (sentence-lengthed audio, English source transcript sentence, Vietnamese target subtitle sentence). We also conduct empirical experiments using strong baselines and find that the traditional "Cascaded" approach still outperforms the modern "End-to-End" approach. To the best of our knowledge, this is the first large-scale English-Vietnamese speech translation study. We hope both our publicly available dataset and study can serve as a starting point for future research and applications on English-Vietnamese speech translation. Our dataset is available at https://github.com/VinAIResearch/PhoST
PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
Oct 23, 2021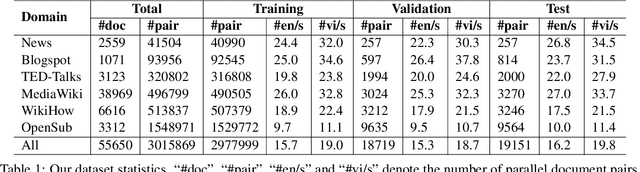
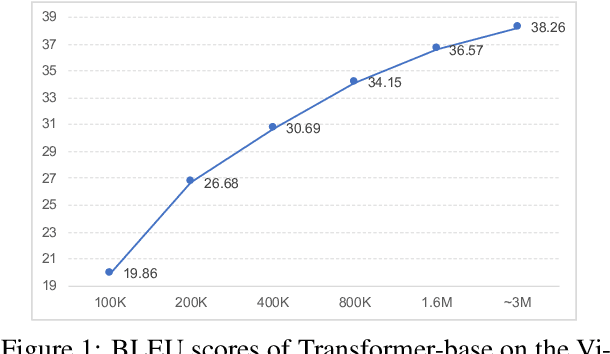
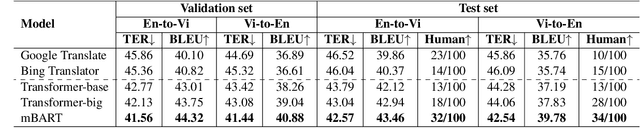

We introduce a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs, which is 2.9M pairs larger than the benchmark Vietnamese-English machine translation corpus IWSLT15. We conduct experiments comparing strong neural baselines and well-known automatic translation engines on our dataset and find that in both automatic and human evaluations: the best performance is obtained by fine-tuning the pre-trained sequence-to-sequence denoising auto-encoder mBART. To our best knowledge, this is the first large-scale Vietnamese-English machine translation study. We hope our publicly available dataset and study can serve as a starting point for future research and applications on Vietnamese-English machine translation.
PhoNLP: A joint multi-task learning model for Vietnamese part-of-speech tagging, named entity recognition and dependency parsing
Jan 05, 2021
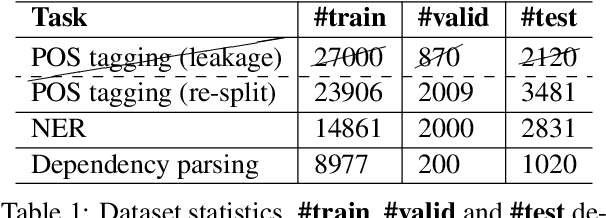


We present the first multi-task learning model -- named PhoNLP -- for joint Vietnamese part-of-speech tagging, named entity recognition and dependency parsing. Experiments on Vietnamese benchmark datasets show that PhoNLP produces state-of-the-art results, outperforming a single-task learning approach that fine-tunes the pre-trained Vietnamese language model PhoBERT (Nguyen and Nguyen, 2020) for each task independently. We publicly release PhoNLP as an open-source toolkit under the MIT License. We hope that PhoNLP can serve as a strong baseline and useful toolkit for future research and applications in Vietnamese NLP. Our PhoNLP is available at https://github.com/VinAIResearch/PhoNLP
WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets
Oct 16, 2020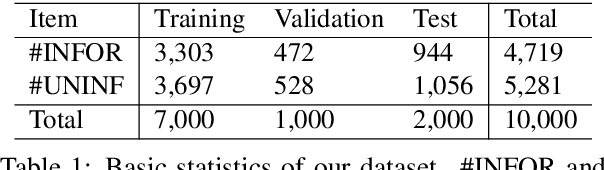
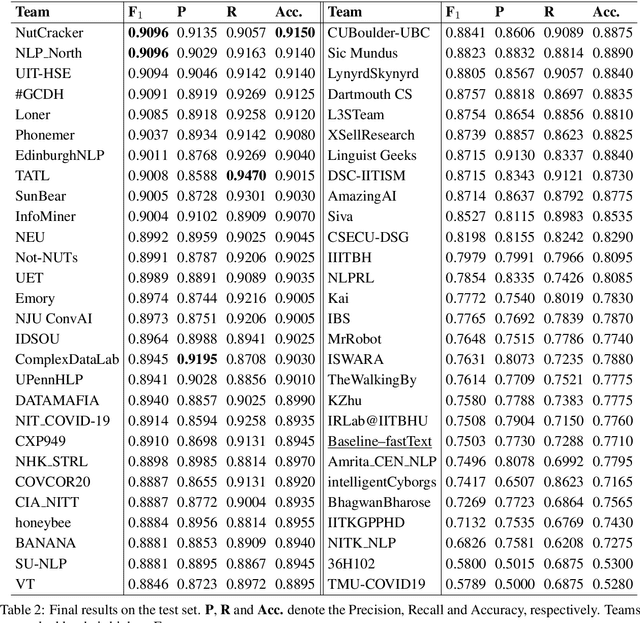
In this paper, we provide an overview of the WNUT-2020 shared task on the identification of informative COVID-19 English Tweets. We describe how we construct a corpus of 10K Tweets and organize the development and evaluation phases for this task. In addition, we also present a brief summary of results obtained from the final system evaluation submissions of 55 teams, finding that (i) many systems obtain very high performance, up to 0.91 F1 score, (ii) the majority of the submissions achieve substantially higher results than the baseline fastText (Joulin et al., 2017), and (iii) fine-tuning pre-trained language models on relevant language data followed by supervised training performs well in this task.