 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking with MIMIC-IV, an irregular, spare clinical time series dataset
Jan 27, 2024Electronic health record (EHR) is more and more popular, and it comes with applying machine learning solutions to resolve various problems in the domain. This growing research area also raises the need for EHRs accessibility. Medical Information Mart for Intensive Care (MIMIC) dataset is a popular, public, and free EHR dataset in a raw format that has been used in numerous studies. However, despite of its popularity, it is lacking benchmarking work, especially with recent state of the art works in the field of deep learning with time-series tabular data. The aim of this work is to fill this lack by providing a benchmark for latest version of MIMIC dataset, MIMIC-IV. We also give a detailed literature survey about studies that has been already done for MIIMIC-III.
PhoGPT: Generative Pre-training for Vietnamese
Nov 06, 2023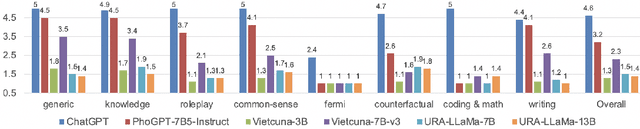
We open-source a state-of-the-art 7.5B-parameter generative model series named PhoGPT for Vietnamese, which includes the base pre-trained monolingual model PhoGPT-7B5 and its instruction-following variant, PhoGPT-7B5-Instruct. In addition, we also demonstrate its superior performance compared to previous open-source models through a human evaluation experiment. GitHub: https://github.com/VinAIResearch/PhoGPT
On Learning Domain-Invariant Representations for Transfer Learning with Multiple Sources
Nov 27, 2021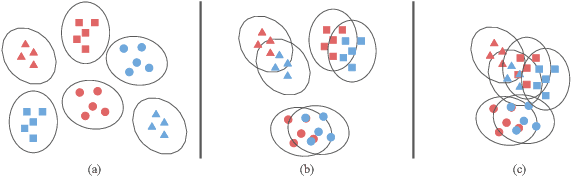
Domain adaptation (DA) benefits from the rigorous theoretical works that study its insightful characteristics and various aspects, e.g., learning domain-invariant representations and its trade-off. However, it seems not the case for the multiple source DA and domain generalization (DG) settings which are remarkably more complicated and sophisticated due to the involvement of multiple source domains and potential unavailability of target domain during training. In this paper, we develop novel upper-bounds for the target general loss which appeal to us to define two kinds of domain-invariant representations. We further study the pros and cons as well as the trade-offs of enforcing learning each domain-invariant representation. Finally, we conduct experiments to inspect the trade-off of these representations for offering practical hints regarding how to use them in practice and explore other interesting properties of our developed theory.
Model Fusion of Heterogeneous Neural Networks via Cross-Layer Alignment
Oct 29, 2021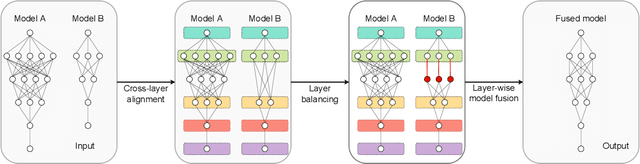

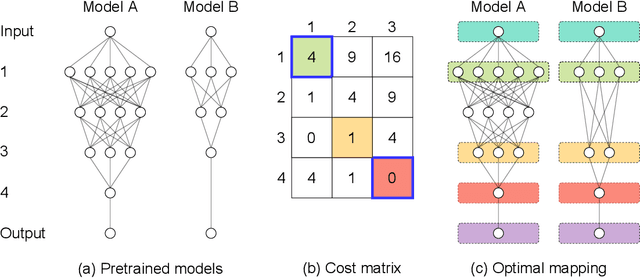

Layer-wise model fusion via optimal transport, named OTFusion, applies soft neuron association for unifying different pre-trained networks to save computational resources. While enjoying its success, OTFusion requires the input networks to have the same number of layers. To address this issue, we propose a novel model fusion framework, named CLAFusion, to fuse neural networks with a different number of layers, which we refer to as heterogeneous neural networks, via cross-layer alignment. The cross-layer alignment problem, which is an unbalanced assignment problem, can be solved efficiently using dynamic programming. Based on the cross-layer alignment, our framework balances the number of layers of neural networks before applying layer-wise model fusion. Our synthetic experiments indicate that the fused network from CLAFusion achieves a more favorable performance compared to the individual networks trained on heterogeneous data without the need for any retraining. With an extra fine-tuning process, it improves the accuracy of residual networks on the CIFAR10 dataset. Finally, we explore its application for model compression and knowledge distillation when applying to the teacher-student setting.
On Label Shift in Domain Adaptation via Wasserstein Distance
Oct 29, 2021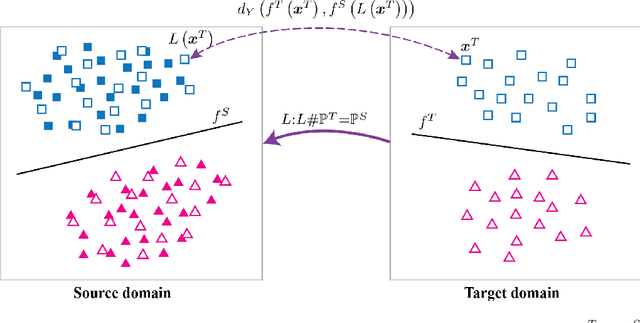
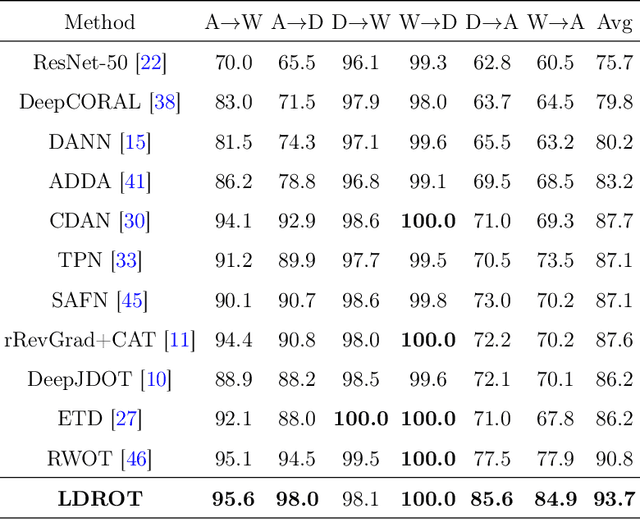
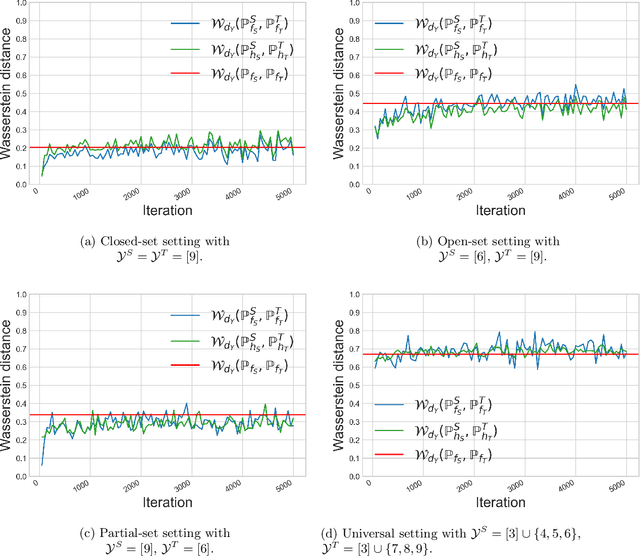
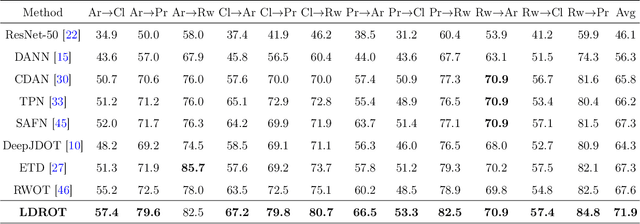
We study the label shift problem between the source and target domains in general domain adaptation (DA) settings. We consider transformations transporting the target to source domains, which enable us to align the source and target examples. Through those transformations, we define the label shift between two domains via optimal transport and develop theory to investigate the properties of DA under various DA settings (e.g., closed-set, partial-set, open-set, and universal settings). Inspired from the developed theory, we propose Label and Data Shift Reduction via Optimal Transport (LDROT) which can mitigate the data and label shifts simultaneously. Finally, we conduct comprehensive experiments to verify our theoretical findings and compare LDROT with state-of-the-art baselines.
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021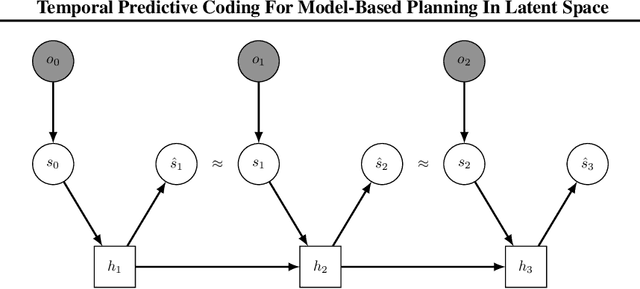
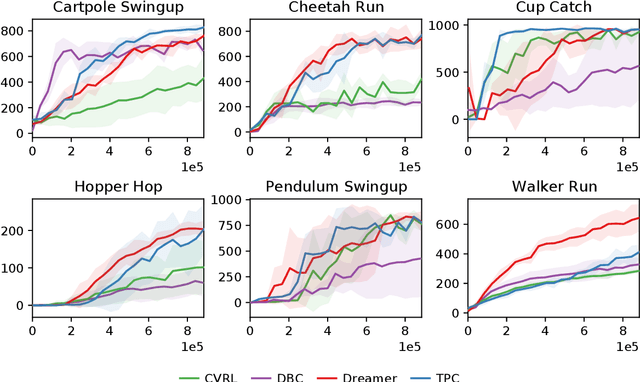
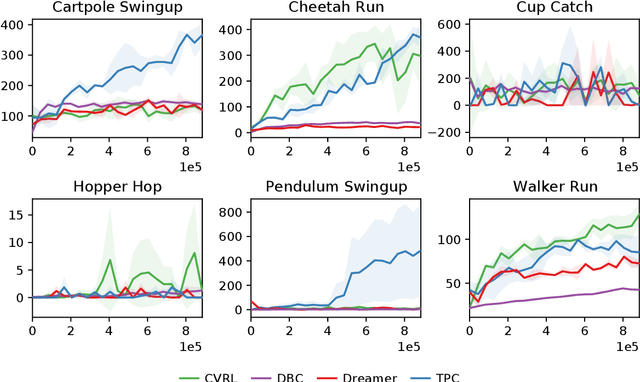
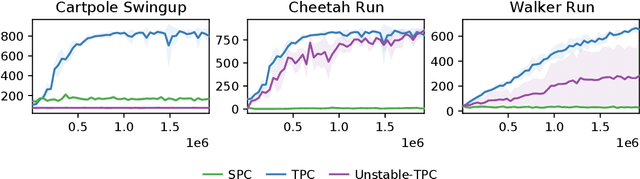
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
Improving Bayesian Inference in Deep Neural Networks with Variational Structured Dropout
Feb 16, 2021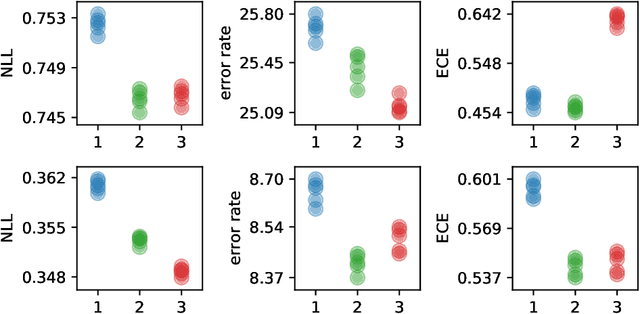
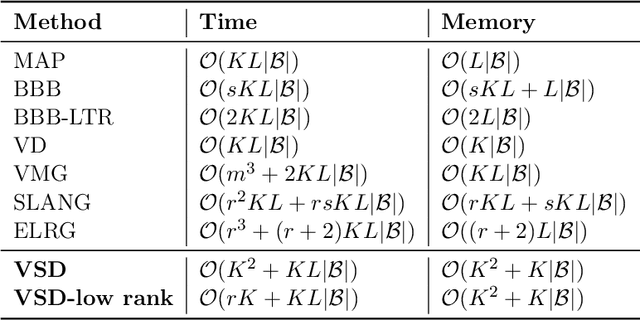
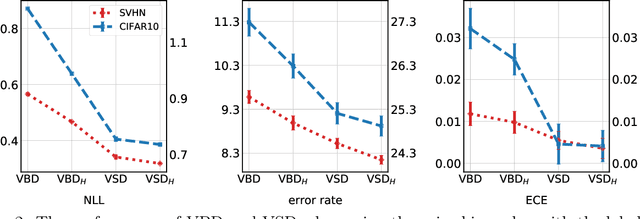
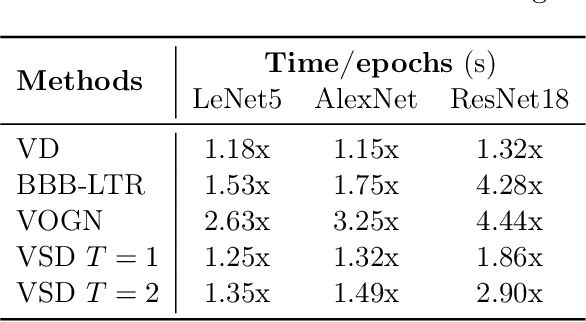
Approximate inference in deep Bayesian networks exhibits a dilemma of how to yield high fidelity posterior approximations while maintaining computational efficiency and scalability. We tackle this challenge by introducing a new variational structured approximation inspired by the interpretation of Dropout training as approximate inference in Bayesian probabilistic models. Concretely, we focus on restrictions of the factorized structure of Dropout posterior which is inflexible to capture rich correlations among weight parameters of the true posterior, and we then propose a novel method called Variational Structured Dropout (VSD) to overcome this limitation. VSD employs an orthogonal transformation to learn a structured representation on the variational Dropout noise and consequently induces statistical dependencies in the approximate posterior. We further gain expressive Bayesian modeling for VSD via proposing a hierarchical Dropout procedure that corresponds to the joint inference in a Bayesian network. Moreover, we can scale up VSD to modern deep convolutional networks in a direct way with a low computational cost. Finally, we conduct extensive experiments on standard benchmarks to demonstrate the effectiveness of VSD over state-of-the-art methods on both predictive accuracy and uncertainty estimation.
On Robust Optimal Transport: Computational Complexity, Low-rank Approximation, and Barycenter Computation
Feb 13, 2021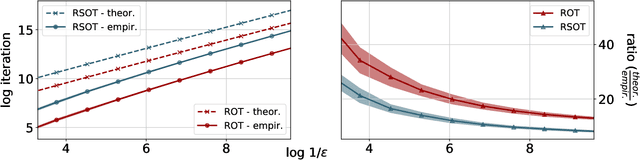

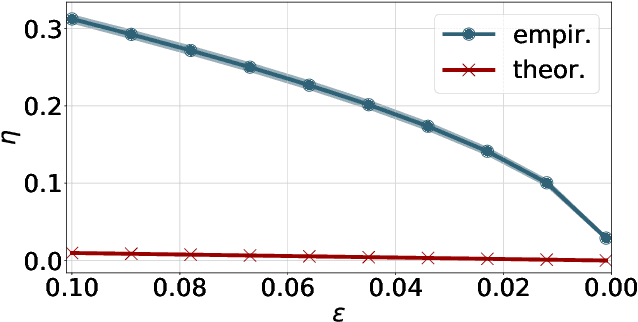
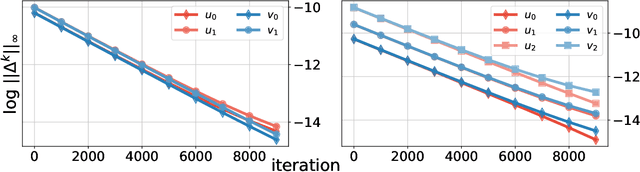
We consider two robust versions of optimal transport, named $\textit{Robust Semi-constrained Optimal Transport}$ (RSOT) and $\textit{Robust Unconstrained Optimal Transport}$ (ROT), formulated by relaxing the marginal constraints with Kullback-Leibler divergence. For both problems in the discrete settings, we propose Sinkhorn-based algorithms that produce $\varepsilon$-approximations of RSOT and ROT in $\widetilde{\mathcal{O}}(\frac{n^2}{\varepsilon})$ time, where $n$ is the number of supports of the probability distributions. Furthermore, to reduce the dependency of the complexity of the Sinkhorn-based algorithms on $n$, we apply Nystr\"{o}m method to approximate the kernel matrix in both RSOT and ROT by a matrix of rank $r$ before passing it to these Sinkhorn-based algorithms. We demonstrate that these new algorithms have $\widetilde{\mathcal{O}}(n r^2 + \frac{nr}{\varepsilon})$ runtime to obtain the RSOT and ROT $\varepsilon$-approximations. Finally, we consider a barycenter problem based on RSOT, named $\textit{Robust Semi-Constrained Barycenter}$ problem (RSBP), and develop a robust iterative Bregman projection algorithm, called $\textbf{Normalized-RobustIBP}$ algorithm, to solve the RSBP in the discrete settings of probability distributions. We show that an $\varepsilon$-approximated solution of the RSBP can be achieved in $\widetilde{\mathcal{O}}(\frac{mn^2}{\varepsilon})$ time using $\textbf{Normalized-RobustIBP}$ algorithm when $m = 2$, which is better than the previous complexity $\widetilde{\mathcal{O}}(\frac{mn^2}{\varepsilon^2})$ of IBP algorithm for approximating the Wasserstein barycenter. Extensive experiments confirm our theoretical results.
BoMb-OT: On Batch of Mini-batches Optimal Transport
Feb 11, 2021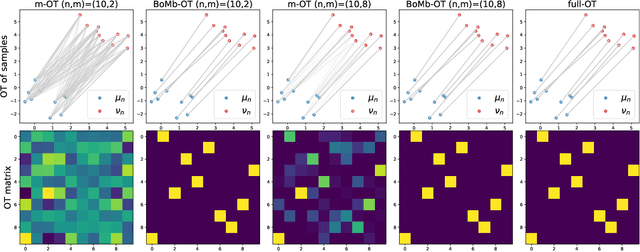
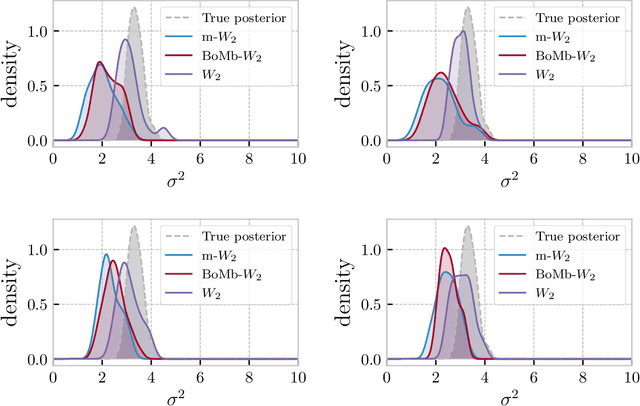

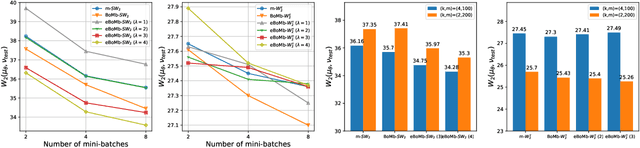
Mini-batch optimal transport (m-OT) has been successfully used in practical applications that involve probability measures with intractable density, or probability measures with a very high number of supports. The m-OT solves several sparser optimal transport problems and then returns the average of their costs and transportation plans. Despite its scalability advantage, m-OT is not a proper metric between probability measures since it does not satisfy the identity property. To address this problem, we propose a novel mini-batching scheme for optimal transport, named Batch of Mini-batches Optimal Transport (BoMb-OT), that can be formulated as a well-defined distance on the space of probability measures. Furthermore, we show that the m-OT is a limit of the entropic regularized version of the proposed BoMb-OT when the regularized parameter goes to infinity. We carry out extensive experiments to show that the new mini-batching scheme can estimate a better transportation plan between two original measures than m-OT. It leads to a favorable performance of BoMb-OT in the matching and color transfer tasks. Furthermore, we observe that BoMb-OT also provides a better objective loss than m-OT for doing approximate Bayesian computation, estimating parameters of interest in parametric generative models, and learning non-parametric generative models with gradient flow.
Learning Compositional Sparse Gaussian Processes with a Shrinkage Prior
Dec 21, 2020



Choosing a proper set of kernel functions is an important problem in learning Gaussian Process (GP) models since each kernel structure has different model complexity and data fitness. Recently, automatic kernel composition methods provide not only accurate prediction but also attractive interpretability through search-based methods. However, existing methods suffer from slow kernel composition learning. To tackle large-scaled data, we propose a new sparse approximate posterior for GPs, MultiSVGP, constructed from groups of inducing points associated with individual additive kernels in compositional kernels. We demonstrate that this approximation provides a better fit to learn compositional kernels given empirical observations. We also theoretically justification on error bound when compared to the traditional sparse GP. In contrast to the search-based approach, we present a novel probabilistic algorithm to learn a kernel composition by handling the sparsity in the kernel selection with Horseshoe prior. We demonstrate that our model can capture characteristics of time series with significant reductions in computational time and have competitive regression performance on real-world data sets.