 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-I2V: Safeguarding your photos from malicious image-to-video generation
Mar 25, 2026Advances in diffusion-based video generation models, while significantly improving human animation, poses threats of misuse through the creation of fake videos from a specific person's photo and text prompts. Recent efforts have focused on adversarial attacks that introduce crafted perturbations to protect images from diffusion-based models. However, most existing approaches target image generation, while relatively few explicitly address image-to-video diffusion models (VDMs), and most primarily focus on UNet-based architectures. Hence, their effectiveness against Diffusion Transformer (DiT) models remains largely under-explored, as these models demonstrate improved feature retention, and stronger temporal consistency due to larger capacity and advanced attention mechanisms. In this work, we introduce Anti-I2V, a novel defense against malicious human image-to-video generation, applicable across diverse diffusion backbones. Instead of restricting noise updates to the RGB space, Anti-I2V operates in both the $L$*$a$*$b$* and frequency domains, improving robustness and concentrating on salient pixels. We then identify the network layers that capture the most distinct semantic features during the denoising process to design appropriate training objectives that maximize degradation of temporal coherence and generation fidelity. Through extensive validation, Anti-I2V demonstrates state-of-the-art defense performance against diverse video diffusion models, offering an effective solution to the problem.
AccurateRAG: A Framework for Building Accurate Retrieval-Augmented Question-Answering Applications
Oct 02, 2025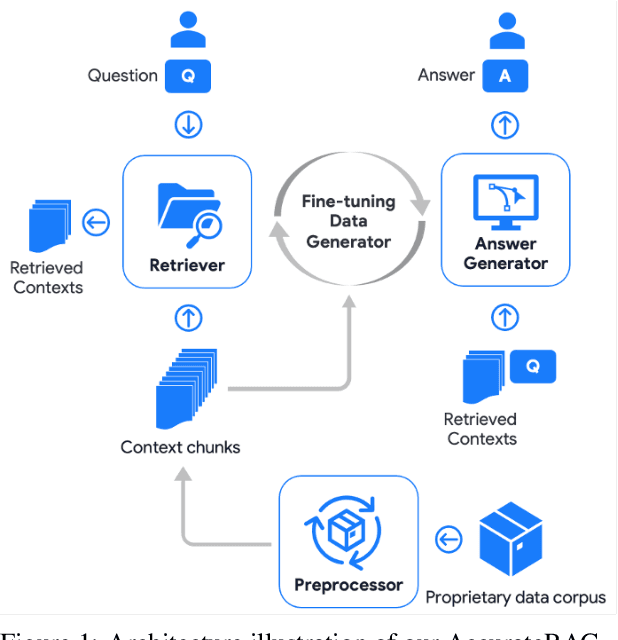

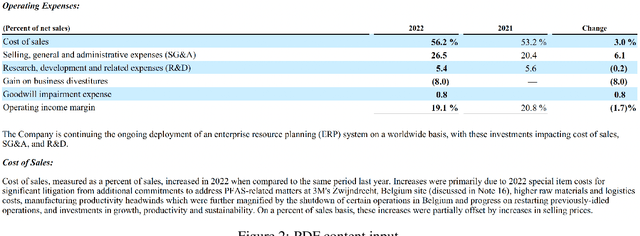
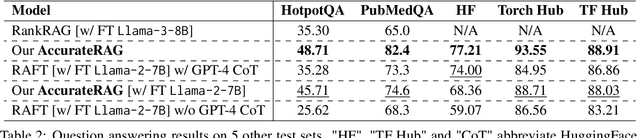
We introduce AccurateRAG -- a novel framework for constructing high-performance question-answering applications based on retrieval-augmented generation (RAG). Our framework offers a pipeline for development efficiency with tools for raw dataset processing, fine-tuning data generation, text embedding & LLM fine-tuning, output evaluation, and building RAG systems locally. Experimental results show that our framework outperforms previous strong baselines and obtains new state-of-the-art question-answering performance on benchmark datasets.
Learning Model Agnostic Explanations via Constraint Programming
Nov 13, 2024Interpretable Machine Learning faces a recurring challenge of explaining the predictions made by opaque classifiers such as ensemble models, kernel methods, or neural networks in terms that are understandable to humans. When the model is viewed as a black box, the objective is to identify a small set of features that jointly determine the black box response with minimal error. However, finding such model-agnostic explanations is computationally demanding, as the problem is intractable even for binary classifiers. In this paper, the task is framed as a Constraint Optimization Problem, where the constraint solver seeks an explanation of minimum error and bounded size for an input data instance and a set of samples generated by the black box. From a theoretical perspective, this constraint programming approach offers PAC-style guarantees for the output explanation. We evaluate the approach empirically on various datasets and show that it statistically outperforms the state-of-the-art heuristic Anchors method.
LaVy: Vietnamese Multimodal Large Language Model
Apr 13, 2024


Large Language Models (LLMs) and Multimodal Large language models (MLLMs) have taken the world by storm with impressive abilities in complex reasoning and linguistic comprehension. Meanwhile there are plethora of works related to Vietnamese Large Language Models, the lack of high-quality resources in multimodality limits the progress of Vietnamese MLLMs. In this paper, we pioneer in address this by introducing LaVy, a state-of-the-art Vietnamese MLLM, and we also introduce LaVy-Bench benchmark designated for evaluating MLLMs's understanding on Vietnamese visual language tasks. All code and model weights are public at https://github.com/baochi0212/LaVy
MISCA: A Joint Model for Multiple Intent Detection and Slot Filling with Intent-Slot Co-Attention
Dec 10, 2023
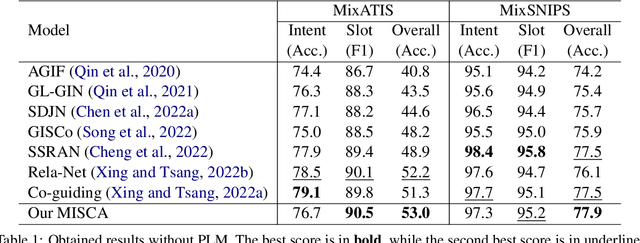
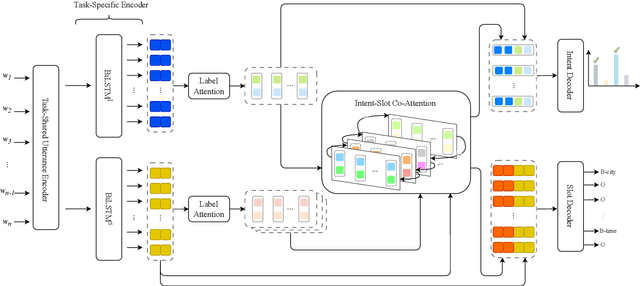
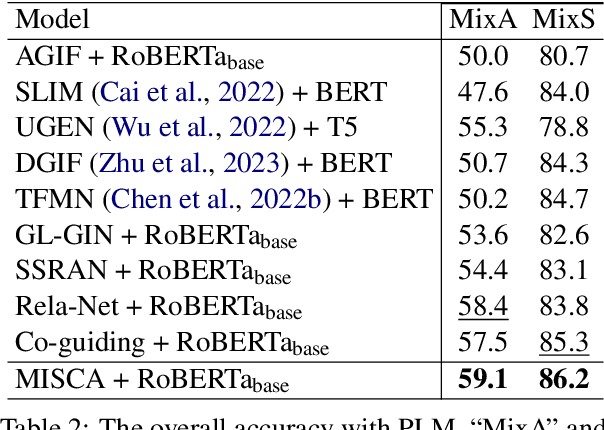
The research study of detecting multiple intents and filling slots is becoming more popular because of its relevance to complicated real-world situations. Recent advanced approaches, which are joint models based on graphs, might still face two potential issues: (i) the uncertainty introduced by constructing graphs based on preliminary intents and slots, which may transfer intent-slot correlation information to incorrect label node destinations, and (ii) direct incorporation of multiple intent labels for each token w.r.t. token-level intent voting might potentially lead to incorrect slot predictions, thereby hurting the overall performance. To address these two issues, we propose a joint model named MISCA. Our MISCA introduces an intent-slot co-attention mechanism and an underlying layer of label attention mechanism. These mechanisms enable MISCA to effectively capture correlations between intents and slot labels, eliminating the need for graph construction. They also facilitate the transfer of correlation information in both directions: from intents to slots and from slots to intents, through multiple levels of label-specific representations, without relying on token-level intent information. Experimental results show that MISCA outperforms previous models, achieving new state-of-the-art overall accuracy performances on two benchmark datasets MixATIS and MixSNIPS. This highlights the effectiveness of our attention mechanisms.
PhoGPT: Generative Pre-training for Vietnamese
Nov 06, 2023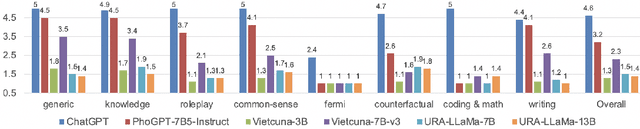
We open-source a state-of-the-art 7.5B-parameter generative model series named PhoGPT for Vietnamese, which includes the base pre-trained monolingual model PhoGPT-7B5 and its instruction-following variant, PhoGPT-7B5-Instruct. In addition, we also demonstrate its superior performance compared to previous open-source models through a human evaluation experiment. GitHub: https://github.com/VinAIResearch/PhoGPT