 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unsupervised Speaker Diarization System for Multilingual Telephone Calls Using Pre-trained Whisper Model and Mixture of Sparse Autoencoders
Jul 02, 2024



Existing speaker diarization systems heavily rely on large amounts of manually annotated data, which is labor-intensive and challenging to collect in real-world scenarios. Additionally, the language-specific constraint in speaker diarization systems significantly hinders their applicability and scalability in multilingual settings. In this paper, we therefore propose a cluster-based speaker diarization system for multilingual telephone call applications. The proposed system supports multiple languages and does not require large-scale annotated data for the training process as leveraging the multilingual Whisper model to extract speaker embeddings and proposing a novel Mixture of Sparse Autoencoders (Mix-SAE) network architecture for unsupervised speaker clustering. Experimental results on the evaluating dataset derived from two-speaker subsets of CALLHOME and CALLFRIEND telephonic speech corpora demonstrate superior efficiency of the proposed Mix-SAE network to other autoencoder-based clustering methods. The overall performance of our proposed system also indicates the promising potential of our approach in developing unsupervised multilingual speaker diarization applications within the context of limited annotated data and enhancing the integration ability into comprehensive multi-task speech analysis systems (i.e. multiple tasks of speech-to-text, language detection, speaker diarization integrated in a low-complexity system).
JPIS: A Joint Model for Profile-based Intent Detection and Slot Filling with Slot-to-Intent Attention
Dec 16, 2023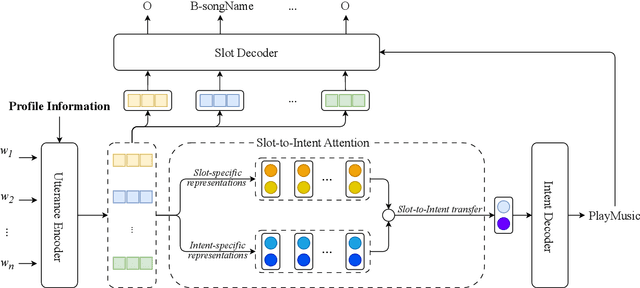



Profile-based intent detection and slot filling are important tasks aimed at reducing the ambiguity in user utterances by leveraging user-specific supporting profile information. However, research in these two tasks has not been extensively explored. To fill this gap, we propose a joint model, namely JPIS, designed to enhance profile-based intent detection and slot filling. JPIS incorporates the supporting profile information into its encoder and introduces a slot-to-intent attention mechanism to transfer slot information representations to intent detection. Experimental results show that our JPIS substantially outperforms previous profile-based models, establishing a new state-of-the-art performance in overall accuracy on the Chinese benchmark dataset ProSLU.
MISCA: A Joint Model for Multiple Intent Detection and Slot Filling with Intent-Slot Co-Attention
Dec 10, 2023
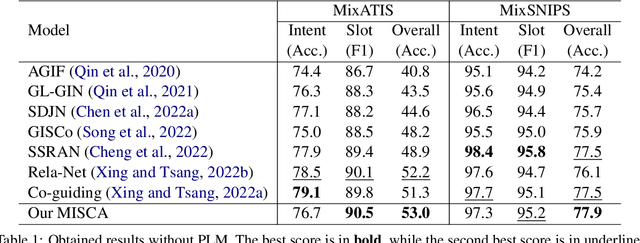
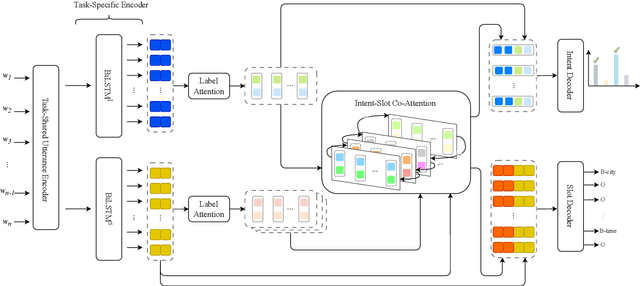
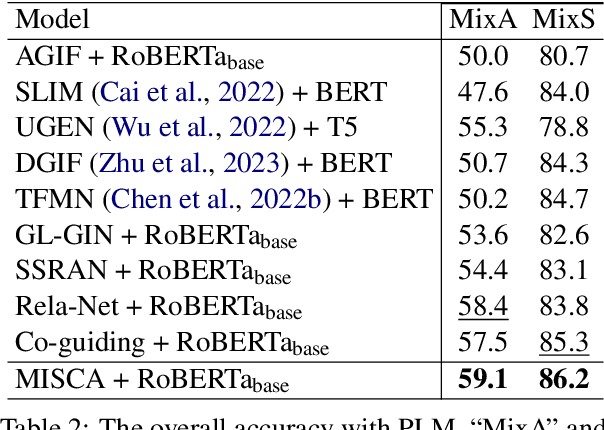
The research study of detecting multiple intents and filling slots is becoming more popular because of its relevance to complicated real-world situations. Recent advanced approaches, which are joint models based on graphs, might still face two potential issues: (i) the uncertainty introduced by constructing graphs based on preliminary intents and slots, which may transfer intent-slot correlation information to incorrect label node destinations, and (ii) direct incorporation of multiple intent labels for each token w.r.t. token-level intent voting might potentially lead to incorrect slot predictions, thereby hurting the overall performance. To address these two issues, we propose a joint model named MISCA. Our MISCA introduces an intent-slot co-attention mechanism and an underlying layer of label attention mechanism. These mechanisms enable MISCA to effectively capture correlations between intents and slot labels, eliminating the need for graph construction. They also facilitate the transfer of correlation information in both directions: from intents to slots and from slots to intents, through multiple levels of label-specific representations, without relying on token-level intent information. Experimental results show that MISCA outperforms previous models, achieving new state-of-the-art overall accuracy performances on two benchmark datasets MixATIS and MixSNIPS. This highlights the effectiveness of our attention mechanisms.
XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
May 31, 2023We present XPhoneBERT, the first multilingual model pre-trained to learn phoneme representations for the downstream text-to-speech (TTS) task. Our XPhoneBERT has the same model architecture as BERT-base, trained using the RoBERTa pre-training approach on 330M phoneme-level sentences from nearly 100 languages and locales. Experimental results show that employing XPhoneBERT as an input phoneme encoder significantly boosts the performance of a strong neural TTS model in terms of naturalness and prosody and also helps produce fairly high-quality speech with limited training data. We publicly release our pre-trained XPhoneBERT with the hope that it would facilitate future research and downstream TTS applications for multiple languages. Our XPhoneBERT model is available at https://github.com/VinAIResearch/XPhoneBERT