 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Effort-aware Fairness: Incorporating a Philosophy-informed, Human-centered Notion of Effort into Algorithmic Fairness Metrics
May 25, 2025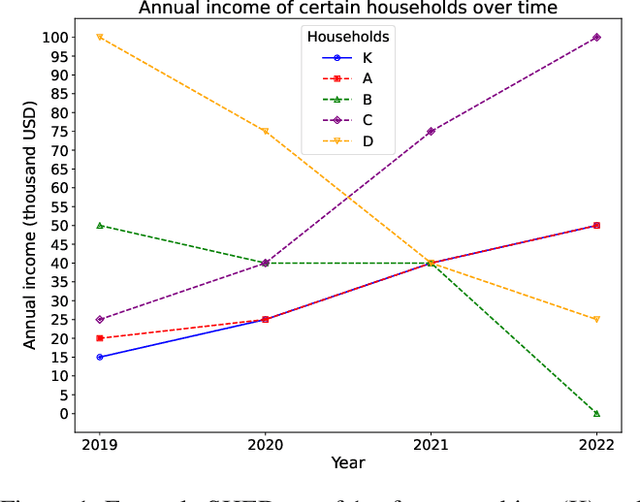



Although popularized AI fairness metrics, e.g., demographic parity, have uncovered bias in AI-assisted decision-making outcomes, they do not consider how much effort one has spent to get to where one is today in the input feature space. However, the notion of effort is important in how Philosophy and humans understand fairness. We propose a philosophy-informed way to conceptualize and evaluate Effort-aware Fairness (EaF) based on the concept of Force, or temporal trajectory of predictive features coupled with inertia. In addition to our theoretical formulation of EaF metrics, our empirical contributions include: 1/ a pre-registered human subjects experiment, which demonstrates that for both stages of the (individual) fairness evaluation process, people consider the temporal trajectory of a predictive feature more than its aggregate value; 2/ pipelines to compute Effort-aware Individual/Group Fairness in the criminal justice and personal finance contexts. Our work may enable AI model auditors to uncover and potentially correct unfair decisions against individuals who spent significant efforts to improve but are still stuck with systemic/early-life disadvantages outside their control.
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Mar 05, 2025An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
Towards Unsupervised Speaker Diarization System for Multilingual Telephone Calls Using Pre-trained Whisper Model and Mixture of Sparse Autoencoders
Jul 02, 2024



Existing speaker diarization systems heavily rely on large amounts of manually annotated data, which is labor-intensive and challenging to collect in real-world scenarios. Additionally, the language-specific constraint in speaker diarization systems significantly hinders their applicability and scalability in multilingual settings. In this paper, we therefore propose a cluster-based speaker diarization system for multilingual telephone call applications. The proposed system supports multiple languages and does not require large-scale annotated data for the training process as leveraging the multilingual Whisper model to extract speaker embeddings and proposing a novel Mixture of Sparse Autoencoders (Mix-SAE) network architecture for unsupervised speaker clustering. Experimental results on the evaluating dataset derived from two-speaker subsets of CALLHOME and CALLFRIEND telephonic speech corpora demonstrate superior efficiency of the proposed Mix-SAE network to other autoencoder-based clustering methods. The overall performance of our proposed system also indicates the promising potential of our approach in developing unsupervised multilingual speaker diarization applications within the context of limited annotated data and enhancing the integration ability into comprehensive multi-task speech analysis systems (i.e. multiple tasks of speech-to-text, language detection, speaker diarization integrated in a low-complexity system).
PEEB: Part-based Image Classifiers with an Explainable and Editable Language Bottleneck
Mar 08, 2024



CLIP-based classifiers rely on the prompt containing a {class name} that is known to the text encoder. That is, CLIP performs poorly on new classes or the classes whose names rarely appear on the Internet (e.g., scientific names of birds). For fine-grained classification, we propose PEEB - an explainable and editable classifier to (1) express the class name into a set of pre-defined text descriptors that describe the visual parts of that class; and (2) match the embeddings of the detected parts to their textual descriptors in each class to compute a logit score for classification. In a zero-shot setting where the class names are unknown, PEEB outperforms CLIP by a large margin (~10x in accuracy). Compared to part-based classifiers, PEEB is not only the state-of-the-art on the supervised-learning setting (88.80% accuracy) but also the first to enable users to edit the class definitions to form a new classifier without retraining. Compared to concept bottleneck models, PEEB is also the state-of-the-art in both zero-shot and supervised learning settings.
The Impact of Frequency Bands on Acoustic Anomaly Detection of Machines using Deep Learning Based Model
Mar 01, 2024



In this paper, we propose a deep learning based model for Acoustic Anomaly Detection of Machines, the task for detecting abnormal machines by analysing the machine sound. By conducting extensive experiments, we indicate that multiple techniques of pseudo audios, audio segment, data augmentation, Mahalanobis distance, and narrow frequency bands, which mainly focus on feature engineering, are effective to enhance the system performance. Among the evaluating techniques, the narrow frequency bands presents a significant impact. Indeed, our proposed model, which focuses on the narrow frequency bands, outperforms the DCASE baseline on the benchmark dataset of DCASE 2022 Task 2 Development set. The important role of the narrow frequency bands indicated in this paper inspires the research community on the task of Acoustic Anomaly Detection of Machines to further investigate and propose novel network architectures focusing on the frequency bands.
LSTM-based Deep Neural Network With A Focus on Sentence Representation for Sequential Sentence Classification in Medical Scientific Abstracts
Jan 29, 2024



The Sequential Sentence Classification task within the domain of medical abstracts, termed as SSC, involves the categorization of sentences into pre-defined headings based on their roles in conveying critical information in the abstract. In the SSC task, sentences are often sequentially related to each other. For this reason, the role of sentence embedding is crucial for capturing both the semantic information between words in the sentence and the contextual relationship of sentences within the abstract to provide a comprehensive representation for better classification. In this paper, we present a hierarchical deep learning model for the SSC task. First, we propose a LSTM-based network with multiple feature branches to create well-presented sentence embeddings at the sentence level. To perform the sequence of sentences, a convolutional-recurrent neural network (C-RNN) at the abstract level and a multi-layer perception network (MLP) at the segment level are developed that further enhance the model performance. Additionally, an ablation study is also conducted to evaluate the contribution of individual component in the entire network to the model performance at different levels. Our proposed system is very competitive to the state-of-the-art systems and further improve F1 scores of the baseline by 1.0%, 2.8%, and 2.6% on the benchmark datasets PudMed 200K RCT, PudMed 20K RCT and NICTA-PIBOSO, respectively.
Leveraging Habitat Information for Fine-grained Bird Identification
Dec 22, 2023Traditional bird classifiers mostly rely on the visual characteristics of birds. Some prior works even train classifiers to be invariant to the background, completely discarding the living environment of birds. Instead, we are the first to explore integrating habitat information, one of the four major cues for identifying birds by ornithologists, into modern bird classifiers. We focus on two leading model types: (1) CNNs and ViTs trained on the downstream bird datasets; and (2) original, multi-modal CLIP. Training CNNs and ViTs with habitat-augmented data results in an improvement of up to +0.83 and +0.23 points on NABirds and CUB-200, respectively. Similarly, adding habitat descriptors to the prompts for CLIP yields a substantial accuracy boost of up to +0.99 and +1.1 points on NABirds and CUB-200, respectively. We find consistent accuracy improvement after integrating habitat features into the image augmentation process and into the textual descriptors of vision-language CLIP classifiers. Code is available at: https://anonymous.4open.science/r/reasoning-8B7E/.
Towards Conceptualization of "Fair Explanation": Disparate Impacts of anti-Asian Hate Speech Explanations on Content Moderators
Oct 23, 2023Recent research at the intersection of AI explainability and fairness has focused on how explanations can improve human-plus-AI task performance as assessed by fairness measures. We propose to characterize what constitutes an explanation that is itself "fair" -- an explanation that does not adversely impact specific populations. We formulate a novel evaluation method of "fair explanations" using not just accuracy and label time, but also psychological impact of explanations on different user groups across many metrics (mental discomfort, stereotype activation, and perceived workload). We apply this method in the context of content moderation of potential hate speech, and its differential impact on Asian vs. non-Asian proxy moderators, across explanation approaches (saliency map and counterfactual explanation). We find that saliency maps generally perform better and show less evidence of disparate impact (group) and individual unfairness than counterfactual explanations. Content warning: This paper contains examples of hate speech and racially discriminatory language. The authors do not support such content. Please consider your risk of discomfort carefully before continuing reading!
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Oct 12, 2023



AI systems have been known to amplify biases in real world data. Explanations may help human-AI teams address these biases for fairer decision-making. Typically, explanations focus on salient input features. If a model is biased against some protected group, explanations may include features that demonstrate this bias, but when biases are realized through proxy features, the relationship between this proxy feature and the protected one may be less clear to a human. In this work, we study the effect of the presence of protected and proxy features on participants' perception of model fairness and their ability to improve demographic parity over an AI alone. Further, we examine how different treatments -- explanations, model bias disclosure and proxy correlation disclosure -- affect fairness perception and parity. We find that explanations help people detect direct biases but not indirect biases. Additionally, regardless of bias type, explanations tend to increase agreement with model biases. Disclosures can help mitigate this effect for indirect biases, improving both unfairness recognition and the decision-making fairness. We hope that our findings can help guide further research into advancing explanations in support of fair human-AI decision-making.