 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Mar 29, 2026In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Aud-Sur: An Audio Analyzer Assistant for Audio Surveillance Applications
Mar 31, 2025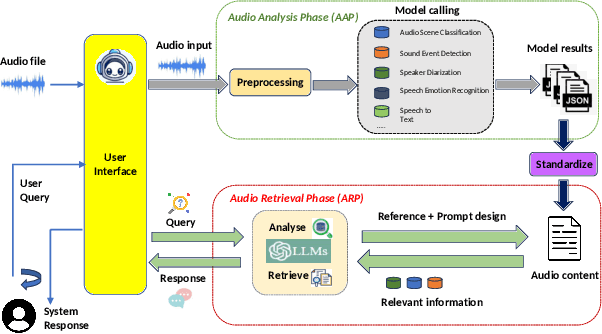
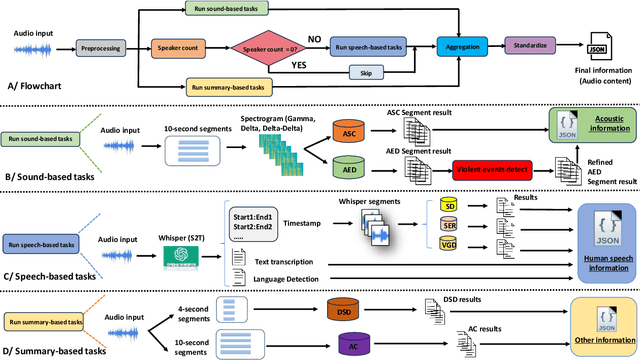
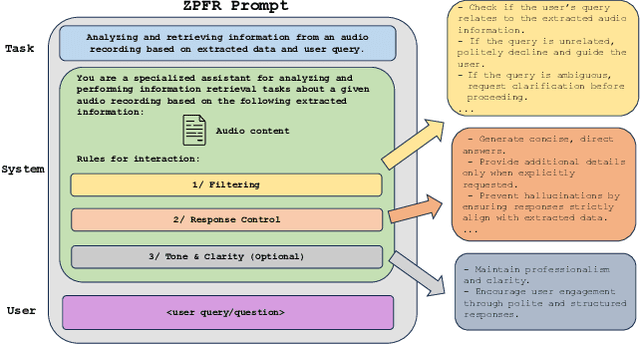

In this paper, we present an audio analyzer assistant tool designed for a wide range of audio-based surveillance applications (This work is a part of our DEFAME FAKES and EUCINF projects). The proposed tool, refered to as Aud-Sur, comprises two main phases Audio Analysis and Audio Retrieval, respectively. In the first phase, multiple open-source audio models are leveraged to extract information from input audio recording uploaded by a user. In the second phase, users interact with the Aud-Sur tool via a natural question-and-answer manner, powered by a large language model (LLM), to retrieve the information extracted from the processed audio file. The Aud-Sur tool was deployed using Docker on a microservices-based architecture design. By leveraging open-source audio models for information extraction, LLM for audio information retrieval, and a microservices-based deployment approach, the proposed Aud-Sur tool offers a highly extensible and adaptable framework that can integrate more audio tasks, and be widely shared within the audio community for further development.
DIN-CTS: Low-Complexity Depthwise-Inception Neural Network with Contrastive Training Strategy for Deepfake Speech Detection
Feb 27, 2025In this paper, we propose a deep neural network approach for deepfake speech detection (DSD) based on a lowcomplexity Depthwise-Inception Network (DIN) trained with a contrastive training strategy (CTS). In this framework, input audio recordings are first transformed into spectrograms using Short-Time Fourier Transform (STFT) and Linear Filter (LF), which are then used to train the DIN. Once trained, the DIN processes bonafide utterances to extract audio embeddings, which are used to construct a Gaussian distribution representing genuine speech. Deepfake detection is then performed by computing the distance between a test utterance and this distribution to determine whether the utterance is fake or bonafide. To evaluate our proposed systems, we conducted extensive experiments on the benchmark dataset of ASVspoof 2019 LA. The experimental results demonstrate the effectiveness of combining the Depthwise-Inception Network with the contrastive learning strategy in distinguishing between fake and bonafide utterances. We achieved Equal Error Rate (EER), Accuracy (Acc.), F1, AUC scores of 4.6%, 95.4%, 97.3%, and 98.9% respectively using a single, low-complexity DIN with just 1.77 M parameters and 985 M FLOPS on short audio segments (4 seconds). Furthermore, our proposed system outperforms the single-system submissions in the ASVspoof 2019 LA challenge, showcasing its potential for real-time applications.
Towards Unsupervised Speaker Diarization System for Multilingual Telephone Calls Using Pre-trained Whisper Model and Mixture of Sparse Autoencoders
Jul 02, 2024



Existing speaker diarization systems heavily rely on large amounts of manually annotated data, which is labor-intensive and challenging to collect in real-world scenarios. Additionally, the language-specific constraint in speaker diarization systems significantly hinders their applicability and scalability in multilingual settings. In this paper, we therefore propose a cluster-based speaker diarization system for multilingual telephone call applications. The proposed system supports multiple languages and does not require large-scale annotated data for the training process as leveraging the multilingual Whisper model to extract speaker embeddings and proposing a novel Mixture of Sparse Autoencoders (Mix-SAE) network architecture for unsupervised speaker clustering. Experimental results on the evaluating dataset derived from two-speaker subsets of CALLHOME and CALLFRIEND telephonic speech corpora demonstrate superior efficiency of the proposed Mix-SAE network to other autoencoder-based clustering methods. The overall performance of our proposed system also indicates the promising potential of our approach in developing unsupervised multilingual speaker diarization applications within the context of limited annotated data and enhancing the integration ability into comprehensive multi-task speech analysis systems (i.e. multiple tasks of speech-to-text, language detection, speaker diarization integrated in a low-complexity system).
Deepfake Audio Detection Using Spectrogram-based Feature and Ensemble of Deep Learning Models
Jul 01, 2024



In this paper, we propose a deep learning based system for the task of deepfake audio detection. In particular, the draw input audio is first transformed into various spectrograms using three transformation methods of Short-time Fourier Transform (STFT), Constant-Q Transform (CQT), Wavelet Transform (WT) combined with different auditory-based filters of Mel, Gammatone, linear filters (LF), and discrete cosine transform (DCT). Given the spectrograms, we evaluate a wide range of classification models based on three deep learning approaches. The first approach is to train directly the spectrograms using our proposed baseline models of CNN-based model (CNN-baseline), RNN-based model (RNN-baseline), C-RNN model (C-RNN baseline). Meanwhile, the second approach is transfer learning from computer vision models such as ResNet-18, MobileNet-V3, EfficientNet-B0, DenseNet-121, SuffleNet-V2, Swint, Convnext-Tiny, GoogLeNet, MNASsnet, RegNet. In the third approach, we leverage the state-of-the-art audio pre-trained models of Whisper, Seamless, Speechbrain, and Pyannote to extract audio embeddings from the input spectrograms. Then, the audio embeddings are explored by a Multilayer perceptron (MLP) model to detect the fake or real audio samples. Finally, high-performance deep learning models from these approaches are fused to achieve the best performance. We evaluated our proposed models on ASVspoof 2019 benchmark dataset. Our best ensemble model achieved an Equal Error Rate (EER) of 0.03, which is highly competitive to top-performing systems in the ASVspoofing 2019 challenge. Experimental results also highlight the potential of selective spectrograms and deep learning approaches to enhance the task of audio deepfake detection.
The Impact of Frequency Bands on Acoustic Anomaly Detection of Machines using Deep Learning Based Model
Mar 01, 2024



In this paper, we propose a deep learning based model for Acoustic Anomaly Detection of Machines, the task for detecting abnormal machines by analysing the machine sound. By conducting extensive experiments, we indicate that multiple techniques of pseudo audios, audio segment, data augmentation, Mahalanobis distance, and narrow frequency bands, which mainly focus on feature engineering, are effective to enhance the system performance. Among the evaluating techniques, the narrow frequency bands presents a significant impact. Indeed, our proposed model, which focuses on the narrow frequency bands, outperforms the DCASE baseline on the benchmark dataset of DCASE 2022 Task 2 Development set. The important role of the narrow frequency bands indicated in this paper inspires the research community on the task of Acoustic Anomaly Detection of Machines to further investigate and propose novel network architectures focusing on the frequency bands.
LSTM-based Deep Neural Network With A Focus on Sentence Representation for Sequential Sentence Classification in Medical Scientific Abstracts
Jan 29, 2024



The Sequential Sentence Classification task within the domain of medical abstracts, termed as SSC, involves the categorization of sentences into pre-defined headings based on their roles in conveying critical information in the abstract. In the SSC task, sentences are often sequentially related to each other. For this reason, the role of sentence embedding is crucial for capturing both the semantic information between words in the sentence and the contextual relationship of sentences within the abstract to provide a comprehensive representation for better classification. In this paper, we present a hierarchical deep learning model for the SSC task. First, we propose a LSTM-based network with multiple feature branches to create well-presented sentence embeddings at the sentence level. To perform the sequence of sentences, a convolutional-recurrent neural network (C-RNN) at the abstract level and a multi-layer perception network (MLP) at the segment level are developed that further enhance the model performance. Additionally, an ablation study is also conducted to evaluate the contribution of individual component in the entire network to the model performance at different levels. Our proposed system is very competitive to the state-of-the-art systems and further improve F1 scores of the baseline by 1.0%, 2.8%, and 2.6% on the benchmark datasets PudMed 200K RCT, PudMed 20K RCT and NICTA-PIBOSO, respectively.
Landslide Detection and Segmentation Using Remote Sensing Images and Deep Neural Network
Dec 27, 2023

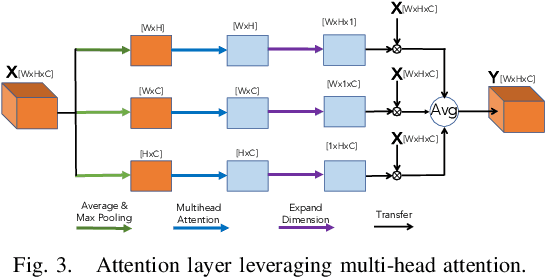
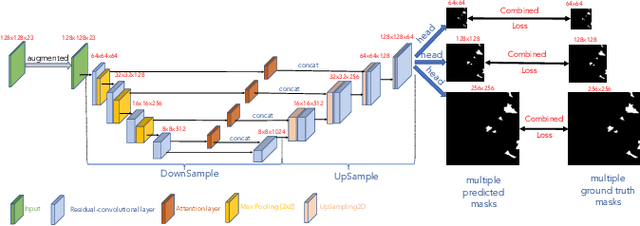
Knowledge about historic landslide event occurrence is important for supporting disaster risk reduction strategies. Building upon findings from 2022 Landslide4Sense Competition, we propose a deep neural network based system for landslide detection and segmentation from multisource remote sensing image input. We use a U-Net trained with Cross Entropy loss as baseline model. We then improve the U-Net baseline model by leveraging a wide range of deep learning techniques. In particular, we conduct feature engineering by generating new band data from the original bands, which helps to enhance the quality of remote sensing image input. Regarding the network architecture, we replace traditional convolutional layers in the U-Net baseline by a residual-convolutional layer. We also propose an attention layer which leverages the multi-head attention scheme. Additionally, we generate multiple output masks with three different resolutions, which creates an ensemble of three outputs in the inference process to enhance the performance. Finally, we propose a combined loss function which leverages Focal loss and IoU loss to train the network. Our experiments on the development set of the Landslide4Sense challenge achieve an F1 score and an mIoU score of 84.07 and 76.07, respectively. Our best model setup outperforms the challenge baseline and the proposed U-Net baseline, improving the F1 score/mIoU score by 6.8/7.4 and 10.5/8.8, respectively.
Low-complexity deep learning frameworks for acoustic scene classification using teacher-student scheme and multiple spectrograms
May 16, 2023In this technical report, a low-complexity deep learning system for acoustic scene classification (ASC) is presented. The proposed system comprises two main phases: (Phase I) Training a teacher network; and (Phase II) training a student network using distilled knowledge from the teacher. In the first phase, the teacher, which presents a large footprint model, is trained. After training the teacher, the embeddings, which are the feature map of the second last layer of the teacher, are extracted. In the second phase, the student network, which presents a low complexity model, is trained with the embeddings extracted from the teacher. Our experiments conducted on DCASE 2023 Task 1 Development dataset have fulfilled the requirement of low-complexity and achieved the best classification accuracy of 57.4%, improving DCASE baseline by 14.5%.
Deep Learning Based Multimodal with Two-phase Training Strategy for Daily Life Video Classification
Apr 30, 2023In this paper, we present a deep learning based multimodal system for classifying daily life videos. To train the system, we propose a two-phase training strategy. In the first training phase (Phase I), we extract the audio and visual (image) data from the original video. We then train the audio data and the visual data with independent deep learning based models. After the training processes, we obtain audio embeddings and visual embeddings by extracting feature maps from the pre-trained deep learning models. In the second training phase (Phase II), we train a fusion layer to combine the audio/visual embeddings and a dense layer to classify the combined embedding into target daily scenes. Our extensive experiments, which were conducted on the benchmark dataset of DCASE (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) 2021 Task 1B Development, achieved the best classification accuracy of 80.5%, 91.8%, and 95.3% with only audio data, with only visual data, both audio and visual data, respectively. The highest classification accuracy of 95.3% presents an improvement of 17.9% compared with DCASE baseline and shows very competitive to the state-of-the-art systems.