 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobilityDL: A Review of Deep Learning From Trajectory Data
Feb 01, 2024Trajectory data combines the complexities of time series, spatial data, and (sometimes irrational) movement behavior. As data availability and computing power have increased, so has the popularity of deep learning from trajectory data. This review paper provides the first comprehensive overview of deep learning approaches for trajectory data. We have identified eight specific mobility use cases which we analyze with regards to the deep learning models and the training data used. Besides a comprehensive quantitative review of the literature since 2018, the main contribution of our work is the data-centric analysis of recent work in this field, placing it along the mobility data continuum which ranges from detailed dense trajectories of individual movers (quasi-continuous tracking data), to sparse trajectories (such as check-in data), and aggregated trajectories (crowd information).
Predictability and Comprehensibility in Post-Hoc XAI Methods: A User-Centered Analysis
Sep 21, 2023



Post-hoc explainability methods aim to clarify predictions of black-box machine learning models. However, it is still largely unclear how well users comprehend the provided explanations and whether these increase the users ability to predict the model behavior. We approach this question by conducting a user study to evaluate comprehensibility and predictability in two widely used tools: LIME and SHAP. Moreover, we investigate the effect of counterfactual explanations and misclassifications on users ability to understand and predict the model behavior. We find that the comprehensibility of SHAP is significantly reduced when explanations are provided for samples near a model's decision boundary. Furthermore, we find that counterfactual explanations and misclassifications can significantly increase the users understanding of how a machine learning model is making decisions. Based on our findings, we also derive design recommendations for future post-hoc explainability methods with increased comprehensibility and predictability.
Towards eXplainable AI for Mobility Data Science
Jul 17, 2023This paper presents our ongoing work towards XAI for Mobility Data Science applications, focusing on explainable models that can learn from dense trajectory data, such as GPS tracks of vehicles and vessels using temporal graph neural networks (GNNs) and counterfactuals. We review the existing GeoXAI studies, argue the need for comprehensible explanations with human-centered approaches, and outline a research path toward XAI for Mobility Data Science.
Low-complexity deep learning frameworks for acoustic scene classification using teacher-student scheme and multiple spectrograms
May 16, 2023In this technical report, a low-complexity deep learning system for acoustic scene classification (ASC) is presented. The proposed system comprises two main phases: (Phase I) Training a teacher network; and (Phase II) training a student network using distilled knowledge from the teacher. In the first phase, the teacher, which presents a large footprint model, is trained. After training the teacher, the embeddings, which are the feature map of the second last layer of the teacher, are extracted. In the second phase, the student network, which presents a low complexity model, is trained with the embeddings extracted from the teacher. Our experiments conducted on DCASE 2023 Task 1 Development dataset have fulfilled the requirement of low-complexity and achieved the best classification accuracy of 57.4%, improving DCASE baseline by 14.5%.
Robust, General, and Low Complexity Acoustic Scene Classification Systems and An Effective Visualization for Presenting a Sound Scene Context
Oct 16, 2022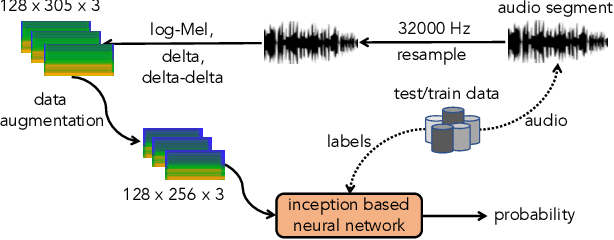
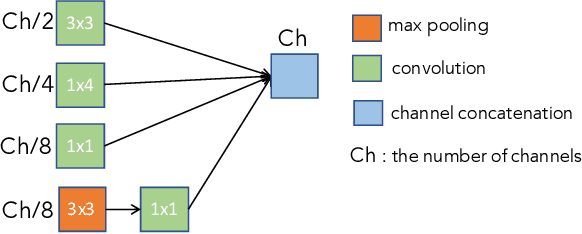
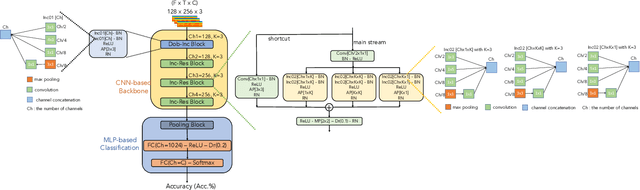
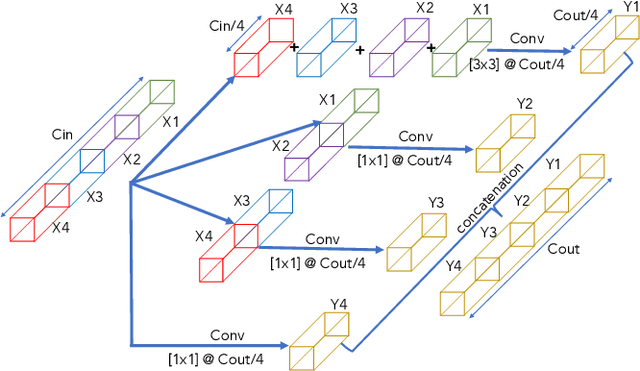
In this paper, we present a comprehensive analysis of Acoustic Scene Classification (ASC), the task of identifying the scene of an audio recording from its acoustic signature. In particular, we firstly propose an inception-based and low footprint ASC model, referred to as the ASC baseline. The proposed ASC baseline is then compared with benchmark and high-complexity network architectures of MobileNetV1, MobileNetV2, VGG16, VGG19, ResNet50V2, ResNet152V2, DenseNet121, DenseNet201, and Xception. Next, we improve the ASC baseline by proposing a novel deep neural network architecture which leverages residual-inception architectures and multiple kernels. Given the novel residual-inception (NRI) model, we further evaluate the trade off between the model complexity and the model accuracy performance. Finally, we evaluate whether sound events occurring in a sound scene recording can help to improve ASC accuracy, then indicate how a sound scene context is well presented by combining both sound scene and sound event information. We conduct extensive experiments on various ASC datasets, including Crowded Scenes, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) 2018 Task 1A and 1B, 2019 Task 1A and 1B, 2020 Task 1A, 2021 Task 1A, 2022 Task 1. The experimental results on several different ASC challenges highlight two main achievements; the first is to propose robust, general, and low complexity ASC systems which are suitable for real-life applications on a wide range of edge devices and mobiles; the second is to propose an effective visualization method for comprehensively presenting a sound scene context.
Low-complexity deep learning frameworks for acoustic scene classification
Jun 13, 2022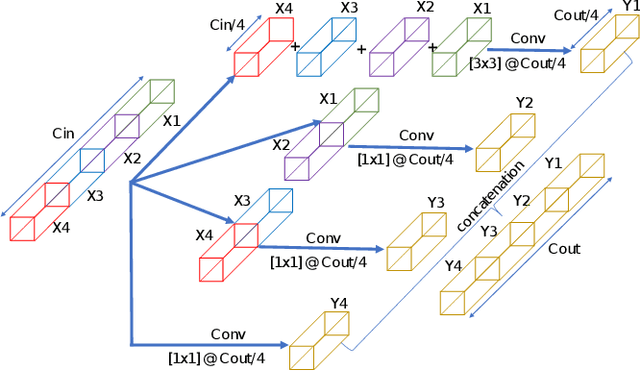
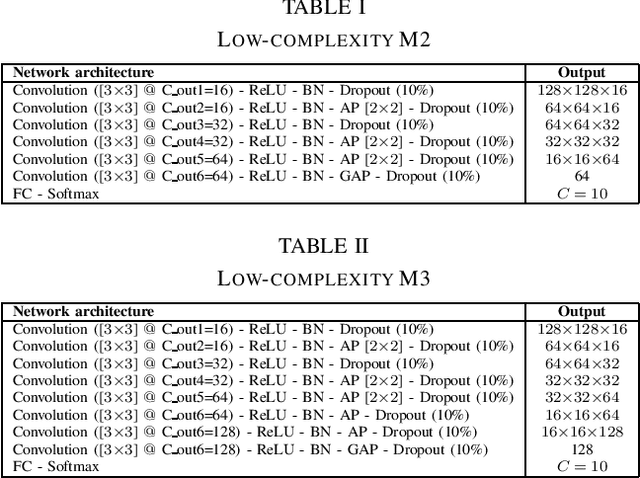
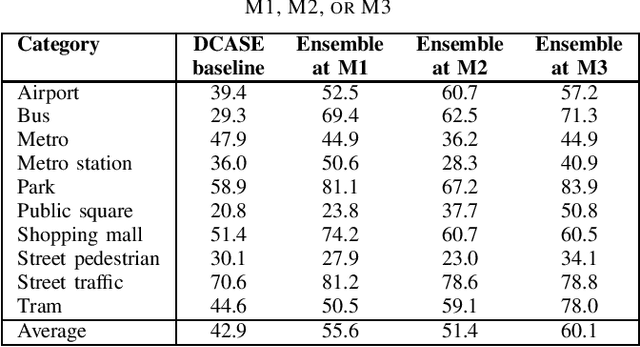
In this report, we presents low-complexity deep learning frameworks for acoustic scene classification (ASC). The proposed frameworks can be separated into four main steps: Front-end spectrogram extraction, online data augmentation, back-end classification, and late fusion of predicted probabilities. In particular, we initially transform audio recordings into Mel, Gammatone, and CQT spectrograms. Next, data augmentation methods of Random Cropping, Specaugment, and Mixup are then applied to generate augmented spectrograms before being fed into deep learning based classifiers. Finally, to achieve the best performance, we fuse probabilities which obtained from three individual classifiers, which are independently-trained with three type of spectrograms. Our experiments conducted on DCASE 2022 Task 1 Development dataset have fullfiled the requirement of low-complexity and achieved the best classification accuracy of 60.1%, improving DCASE baseline by 17.2%.
Machine Learning Methods for Health-Index Prediction in Coating Chambers
May 30, 2022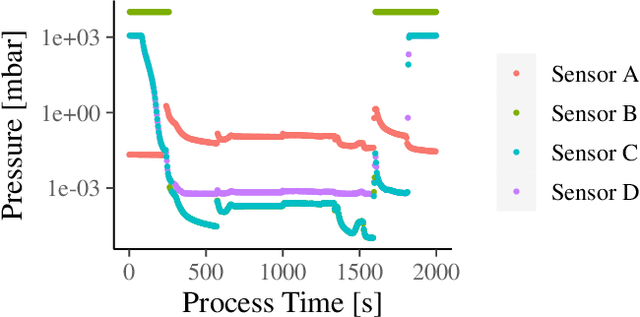
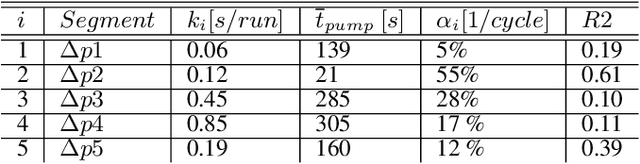
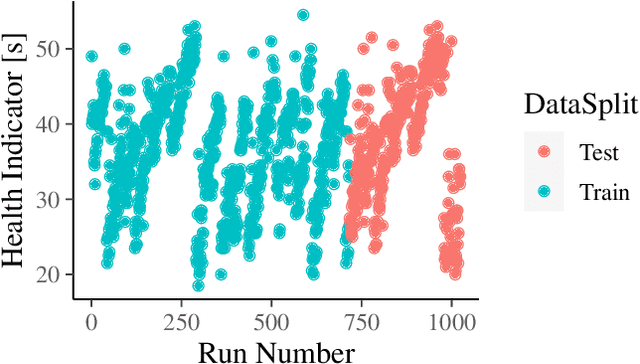
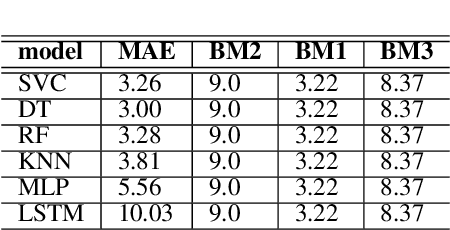
Coating chambers create thin layers that improve the mechanical and optical surface properties in jewelry production using physical vapor deposition. In such a process, evaporated material condensates on the walls of such chambers and, over time, causes mechanical defects and unstable processes. As a result, manufacturers perform extensive maintenance procedures to reduce production loss. Current rule-based maintenance strategies neglect the impact of specific recipes and the actual condition of the vacuum chamber. Our overall goal is to predict the future condition of the coating chamber to allow cost and quality optimized maintenance of the equipment. This paper describes the derivation of a novel health indicator that serves as a step toward condition-based maintenance for coating chambers. We indirectly use gas emissions of the chamber's contamination to evaluate the machine's condition. Our approach relies on process data and does not require additional hardware installation. Further, we evaluated multiple machine learning algorithms for a condition-based forecast of the health indicator that also reflects production planning. Our results show that models based on decision trees are the most effective and outperform all three benchmarks, improving at least $0.22$ in the mean average error. Our work paves the way for cost and quality optimized maintenance of coating applications.
Minimal-Configuration Anomaly Detection for IIoT Sensors
Oct 08, 2021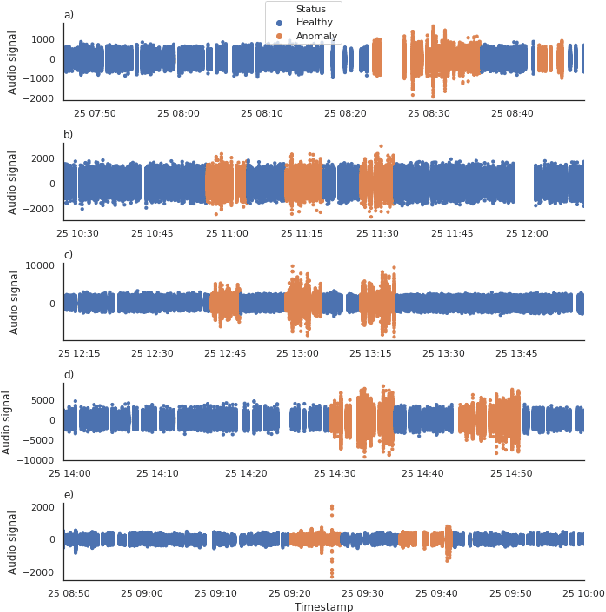
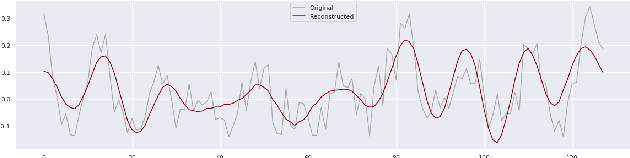
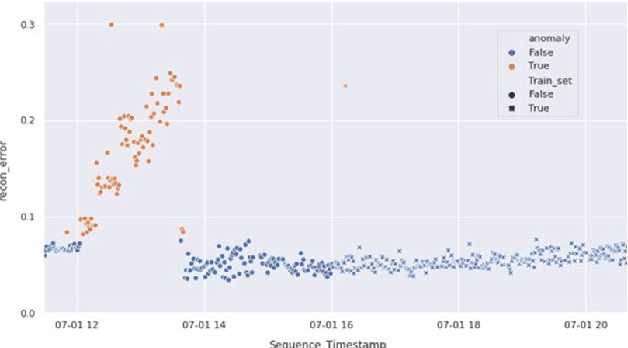
The increasing deployment of low-cost IoT sensor platforms in industry boosts the demand for anomaly detection solutions that fulfill two key requirements: minimal configuration effort and easy transferability across equipment. Recent advances in deep learning, especially long-short-term memory (LSTM) and autoencoders, offer promising methods for detecting anomalies in sensor data recordings. We compared autoencoders with various architectures such as deep neural networks (DNN), LSTMs and convolutional neural networks (CNN) using a simple benchmark dataset, which we generated by operating a peristaltic pump under various operating conditions and inducing anomalies manually. Our preliminary results indicate that a single model can detect anomalies under various operating conditions on a four-dimensional data set without any specific feature engineering for each operating condition. We consider this work as being the first step towards a generic anomaly detection method, which is applicable for a wide range of industrial equipment.
A Low-Compexity Deep Learning Framework For Acoustic Scene Classification
Jun 12, 2021
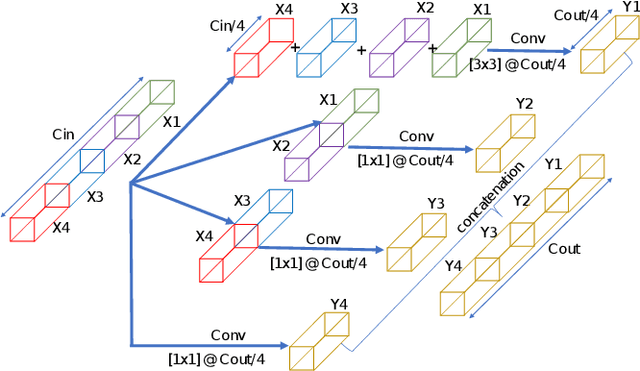
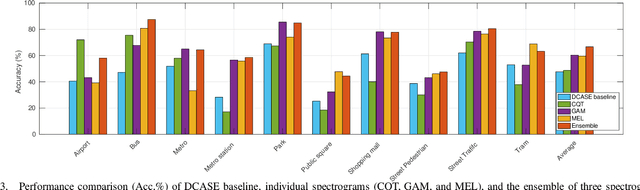
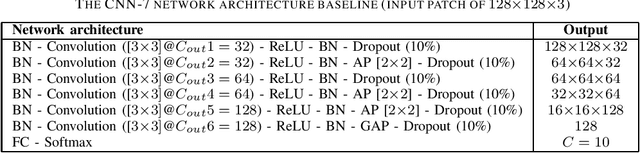
In this paper, we presents a low-complexity deep learning frameworks for acoustic scene classification (ASC). The proposed framework can be separated into three main steps: Front-end spectrogram extraction, back-end classification, and late fusion of predicted probabilities. First, we use Mel filter, Gammatone filter and Constant Q Transfrom (CQT) to transform raw audio signal into spectrograms, where both frequency and temporal features are presented. Three spectrograms are then fed into three individual back-end convolutional neural networks (CNNs), classifying into ten urban scenes. Finally, a late fusion of three predicted probabilities obtained from three CNNs is conducted to achieve the final classification result. To reduce the complexity of our proposed CNN network, we apply two model compression techniques: model restriction and decomposed convolution. Our extensive experiments, which are conducted on DCASE 2021 (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) Task 1A development dataset, achieve a low-complexity CNN based framework with 128 KB trainable parameters and the best classification accuracy of 66.7%, improving DCASE baseline by 19.0%
Multi-Modal Video Forensic Platform for Investigating Post-Terrorist Attack Scenarios
Apr 02, 2020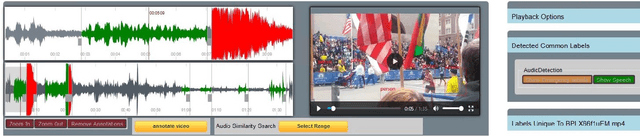
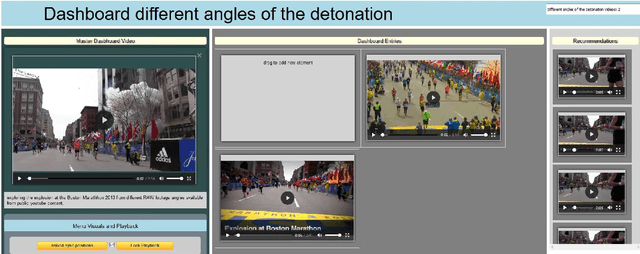
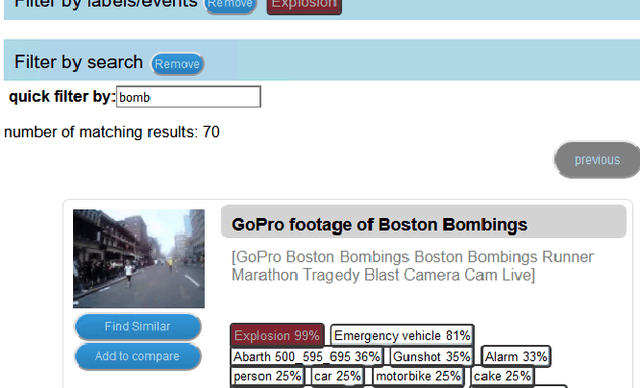
The forensic investigation of a terrorist attack poses a significant challenge to the investigative authorities, as often several thousand hours of video footage must be viewed. Large scale Video Analytic Platforms (VAP) assist law enforcement agencies (LEA) in identifying suspects and securing evidence. Current platforms focus primarily on the integration of different computer vision methods and thus are restricted to a single modality. We present a video analytic platform that integrates visual and audio analytic modules and fuses information from surveillance cameras and video uploads from eyewitnesses. Videos are analyzed according their acoustic and visual content. Specifically, Audio Event Detection is applied to index the content according to attack-specific acoustic concepts. Audio similarity search is utilized to identify similar video sequences recorded from different perspectives. Visual object detection and tracking are used to index the content according to relevant concepts. Innovative user-interface concepts are introduced to harness the full potential of the heterogeneous results of the analytical modules, allowing investigators to more quickly follow-up on leads and eyewitness reports.