 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust, General, and Low Complexity Acoustic Scene Classification Systems and An Effective Visualization for Presenting a Sound Scene Context
Oct 16, 2022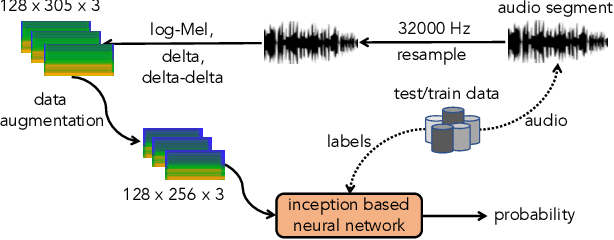
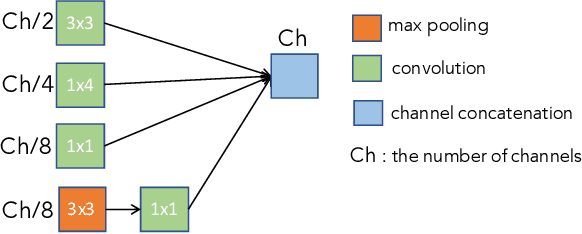
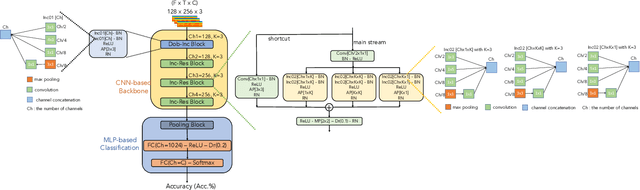
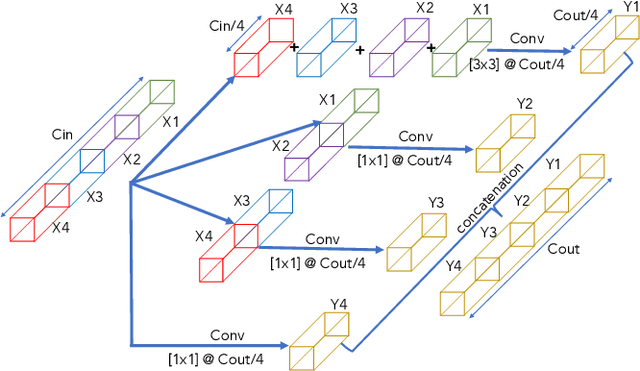
In this paper, we present a comprehensive analysis of Acoustic Scene Classification (ASC), the task of identifying the scene of an audio recording from its acoustic signature. In particular, we firstly propose an inception-based and low footprint ASC model, referred to as the ASC baseline. The proposed ASC baseline is then compared with benchmark and high-complexity network architectures of MobileNetV1, MobileNetV2, VGG16, VGG19, ResNet50V2, ResNet152V2, DenseNet121, DenseNet201, and Xception. Next, we improve the ASC baseline by proposing a novel deep neural network architecture which leverages residual-inception architectures and multiple kernels. Given the novel residual-inception (NRI) model, we further evaluate the trade off between the model complexity and the model accuracy performance. Finally, we evaluate whether sound events occurring in a sound scene recording can help to improve ASC accuracy, then indicate how a sound scene context is well presented by combining both sound scene and sound event information. We conduct extensive experiments on various ASC datasets, including Crowded Scenes, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) 2018 Task 1A and 1B, 2019 Task 1A and 1B, 2020 Task 1A, 2021 Task 1A, 2022 Task 1. The experimental results on several different ASC challenges highlight two main achievements; the first is to propose robust, general, and low complexity ASC systems which are suitable for real-life applications on a wide range of edge devices and mobiles; the second is to propose an effective visualization method for comprehensively presenting a sound scene context.