 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Video Forensic Platform for Investigating Post-Terrorist Attack Scenarios
Apr 02, 2020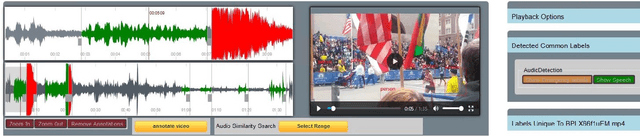
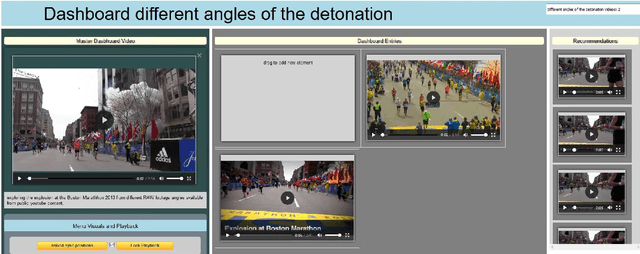
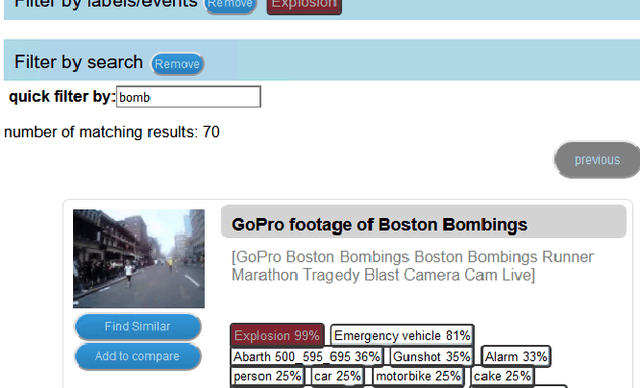
The forensic investigation of a terrorist attack poses a significant challenge to the investigative authorities, as often several thousand hours of video footage must be viewed. Large scale Video Analytic Platforms (VAP) assist law enforcement agencies (LEA) in identifying suspects and securing evidence. Current platforms focus primarily on the integration of different computer vision methods and thus are restricted to a single modality. We present a video analytic platform that integrates visual and audio analytic modules and fuses information from surveillance cameras and video uploads from eyewitnesses. Videos are analyzed according their acoustic and visual content. Specifically, Audio Event Detection is applied to index the content according to attack-specific acoustic concepts. Audio similarity search is utilized to identify similar video sequences recorded from different perspectives. Visual object detection and tracking are used to index the content according to relevant concepts. Innovative user-interface concepts are introduced to harness the full potential of the heterogeneous results of the analytical modules, allowing investigators to more quickly follow-up on leads and eyewitness reports.
Unsupervised Cross-Modal Audio Representation Learning from Unstructured Multilingual Text
Mar 27, 2020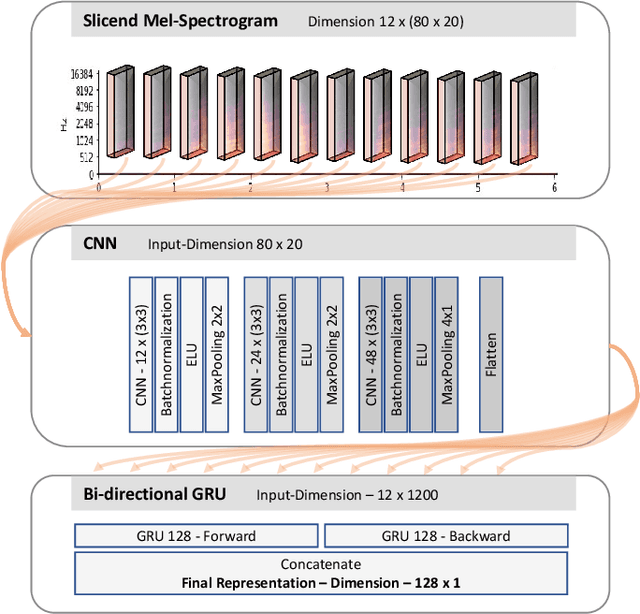
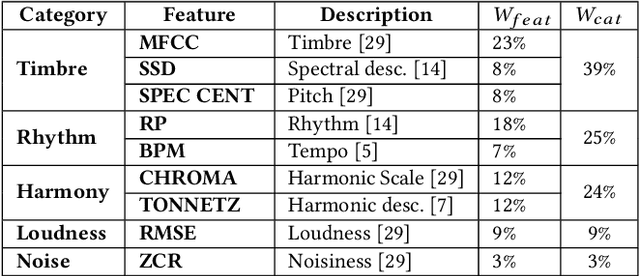
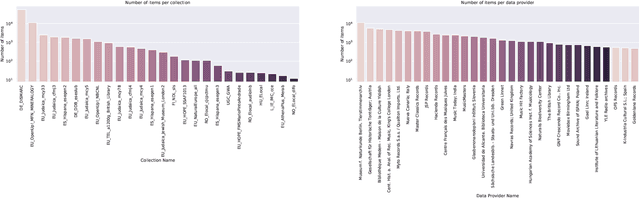

We present an approach to unsupervised audio representation learning. Based on a triplet neural network architecture, we harnesses semantically related cross-modal information to estimate audio track-relatedness. By applying Latent Semantic Indexing (LSI) we embed corresponding textual information into a latent vector space from which we derive track relatedness for online triplet selection. This LSI topic modelling facilitates fine-grained selection of similar and dissimilar audio-track pairs to learn the audio representation using a Convolution Recurrent Neural Network (CRNN). By this we directly project the semantic context of the unstructured text modality onto the learned representation space of the audio modality without deriving structured ground-truth annotations from it. We evaluate our approach on the Europeana Sounds collection and show how to improve search in digital audio libraries by harnessing the multilingual meta-data provided by numerous European digital libraries. We show that our approach is invariant to the variety of annotation styles as well as to the different languages of this collection. The learned representations perform comparable to the baseline of handcrafted features, respectively exceeding this baseline in similarity retrieval precision at higher cut-offs with only 15\% of the baseline's feature vector length.
* This is the long version of our SAC2020 poster presentation