 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Negative Signals with Self-Attention for Sequential Music Recommendation
Sep 20, 2023
Music streaming services heavily rely on their recommendation engines to continuously provide content to their consumers. Sequential recommendation consequently has seen considerable attention in current literature, where state of the art approaches focus on self-attentive models leveraging contextual information such as long and short-term user history and item features; however, most of these studies focus on long-form content domains (retail, movie, etc.) rather than short-form, such as music. Additionally, many do not explore incorporating negative session-level feedback during training. In this study, we investigate the use of transformer-based self-attentive architectures to learn implicit session-level information for sequential music recommendation. We additionally propose a contrastive learning task to incorporate negative feedback (e.g skipped tracks) to promote positive hits and penalize negative hits. This task is formulated as a simple loss term that can be incorporated into a variety of deep learning architectures for sequential recommendation. Our experiments show that this results in consistent performance gains over the baseline architectures ignoring negative user feedback.
Content-based Music Recommendation: Evolution, State of the Art, and Challenges
Jul 25, 2021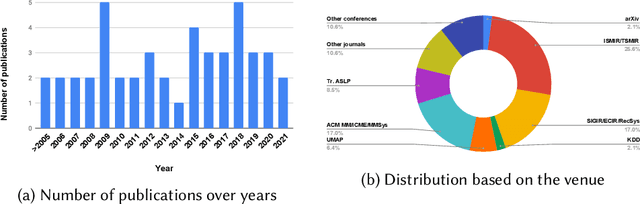
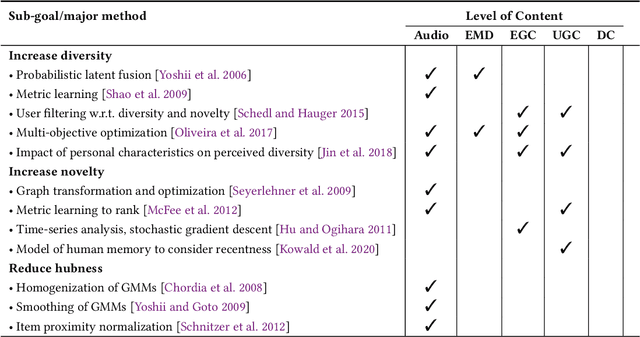
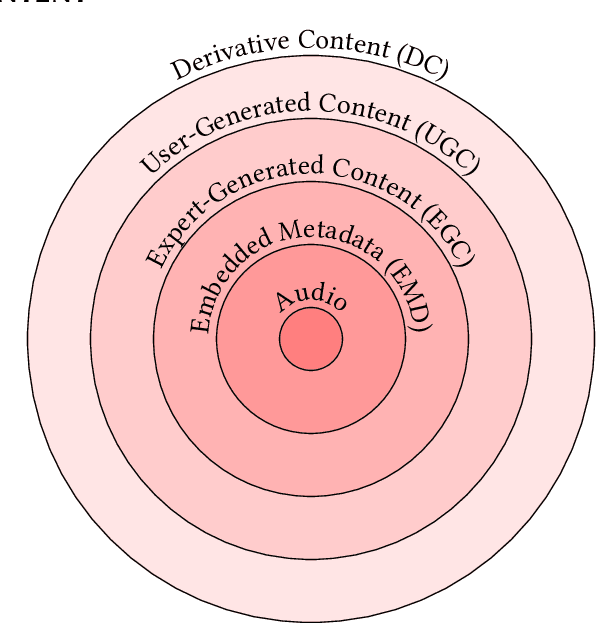

The music domain is among the most important ones for adopting recommender systems technology. In contrast to most other recommendation domains, which predominantly rely on collaborative filtering (CF) techniques, music recommenders have traditionally embraced content-based (CB) approaches. In the past years, music recommendation models that leverage collaborative and content data -- which we refer to as content-driven models -- have been replacing pure CF or CB models. In this survey, we review 47 articles on content-driven music recommendation. Based on a thorough literature analysis, we first propose an onion model comprising five layers, each of which corresponds to a category of music content we identified: signal, embedded metadata, expert-generated content, user-generated content, and derivative content. We provide a detailed characterization of each category along several dimensions. Second, we identify six overarching challenges, according to which we organize our main discussion: increasing recommendation diversity and novelty, providing transparency and explanations, accomplishing context-awareness, recommending sequences of music, improving scalability and efficiency, and alleviating cold start. Each article addressing one or more of these challenges is categorized according to the content layers of our onion model, the article's goal(s), and main methodological choices. Furthermore, articles are discussed in temporal order to shed light on the evolution of content-driven music recommendation strategies. Finally, we provide our personal selection of the persisting grand challenges, which are still waiting to be solved in future research endeavors.
Unsupervised Cross-Modal Audio Representation Learning from Unstructured Multilingual Text
Mar 27, 2020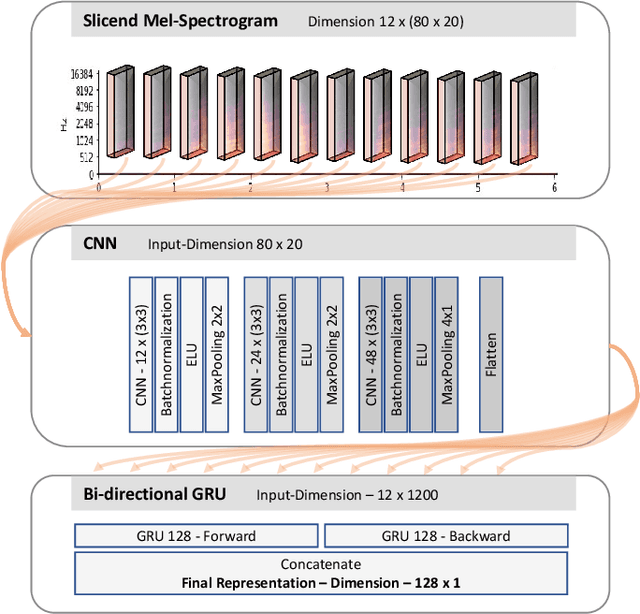

We present an approach to unsupervised audio representation learning. Based on a triplet neural network architecture, we harnesses semantically related cross-modal information to estimate audio track-relatedness. By applying Latent Semantic Indexing (LSI) we embed corresponding textual information into a latent vector space from which we derive track relatedness for online triplet selection. This LSI topic modelling facilitates fine-grained selection of similar and dissimilar audio-track pairs to learn the audio representation using a Convolution Recurrent Neural Network (CRNN). By this we directly project the semantic context of the unstructured text modality onto the learned representation space of the audio modality without deriving structured ground-truth annotations from it. We evaluate our approach on the Europeana Sounds collection and show how to improve search in digital audio libraries by harnessing the multilingual meta-data provided by numerous European digital libraries. We show that our approach is invariant to the variety of annotation styles as well as to the different languages of this collection. The learned representations perform comparable to the baseline of handcrafted features, respectively exceeding this baseline in similarity retrieval precision at higher cut-offs with only 15\% of the baseline's feature vector length.
* This is the long version of our SAC2020 poster presentation
Towards multi-instrument drum transcription
Oct 03, 2018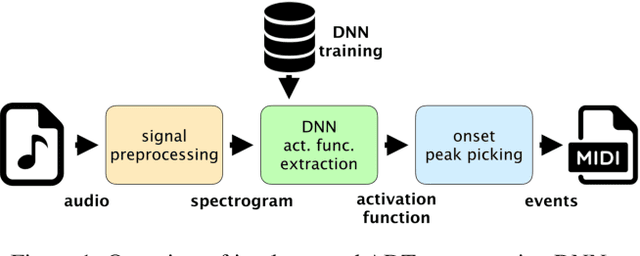
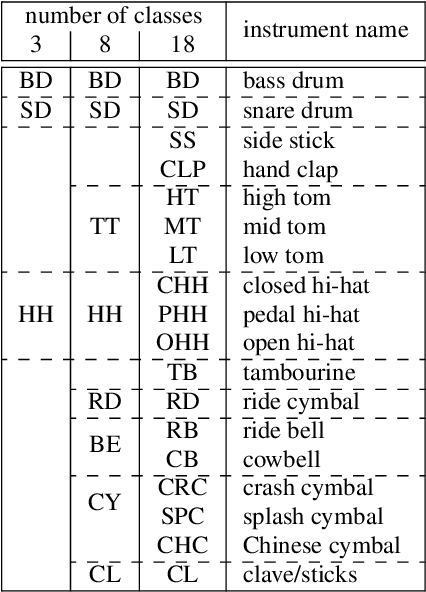
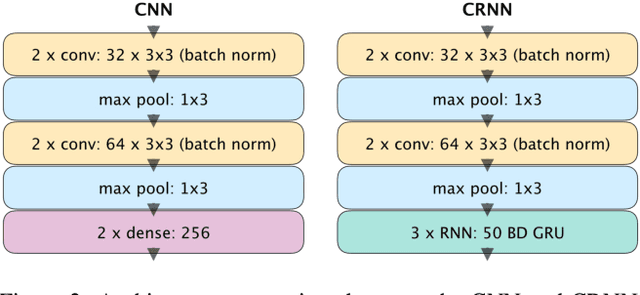
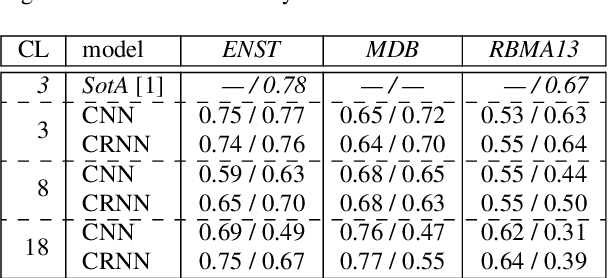
Automatic drum transcription, a subtask of the more general automatic music transcription, deals with extracting drum instrument note onsets from an audio source. Recently, progress in transcription performance has been made using non-negative matrix factorization as well as deep learning methods. However, these works primarily focus on transcribing three drum instruments only: snare drum, bass drum, and hi-hat. Yet, for many applications, the ability to transcribe more drum instruments which make up standard drum kits used in western popular music would be desirable. In this work, convolutional and convolutional recurrent neural networks are trained to transcribe a wider range of drum instruments. First, the shortcomings of publicly available datasets in this context are discussed. To overcome these limitations, a larger synthetic dataset is introduced. Then, methods to train models using the new dataset focusing on generalization to real world data are investigated. Finally, the trained models are evaluated on publicly available datasets and results are discussed. The contributions of this work comprise: (i.) a large-scale synthetic dataset for drum transcription, (ii.) first steps towards an automatic drum transcription system that supports a larger range of instruments by evaluating and discussing training setups and the impact of datasets in this context, and (iii.) a publicly available set of trained models for drum transcription. Additional materials are available at http://ifs.tuwien.ac.at/~vogl/dafx2018