 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of Fundamental Science Led by Generative Closed-Loop Artificial Intelligence
Jul 09, 2023



Recent advances in machine learning and AI, including Generative AI and LLMs, are disrupting technological innovation, product development, and society as a whole. AI's contribution to technology can come from multiple approaches that require access to large training data sets and clear performance evaluation criteria, ranging from pattern recognition and classification to generative models. Yet, AI has contributed less to fundamental science in part because large data sets of high-quality data for scientific practice and model discovery are more difficult to access. Generative AI, in general, and Large Language Models in particular, may represent an opportunity to augment and accelerate the scientific discovery of fundamental deep science with quantitative models. Here we explore and investigate aspects of an AI-driven, automated, closed-loop approach to scientific discovery, including self-driven hypothesis generation and open-ended autonomous exploration of the hypothesis space. Integrating AI-driven automation into the practice of science would mitigate current problems, including the replication of findings, systematic production of data, and ultimately democratisation of the scientific process. Realising these possibilities requires a vision for augmented AI coupled with a diversity of AI approaches able to deal with fundamental aspects of causality analysis and model discovery while enabling unbiased search across the space of putative explanations. These advances hold the promise to unleash AI's potential for searching and discovering the fundamental structure of our world beyond what human scientists have been able to achieve. Such a vision would push the boundaries of new fundamental science rather than automatize current workflows and instead open doors for technological innovation to tackle some of the greatest challenges facing humanity today.
Automated Scientific Discovery: From Equation Discovery to Autonomous Discovery Systems
May 03, 2023



The paper surveys automated scientific discovery, from equation discovery and symbolic regression to autonomous discovery systems and agents. It discusses the individual approaches from a "big picture" perspective and in context, but also discusses open issues and recent topics like the various roles of deep neural networks in this area, aiding in the discovery of human-interpretable knowledge. Further, we will present closed-loop scientific discovery systems, starting with the pioneering work on the Adam system up to current efforts in fields from material science to astronomy. Finally, we will elaborate on autonomy from a machine learning perspective, but also in analogy to the autonomy levels in autonomous driving. The maximal level, level five, is defined to require no human intervention at all in the production of scientific knowledge. Achieving this is one step towards solving the Nobel Turing Grand Challenge to develop AI Scientists: AI systems capable of making Nobel-quality scientific discoveries highly autonomously at a level comparable, and possibly superior, to the best human scientists by 2050.
Deep Learning Frameworks Applied For Audio-Visual Scene Classification
Jun 12, 2021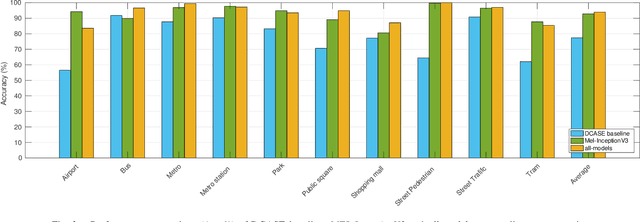
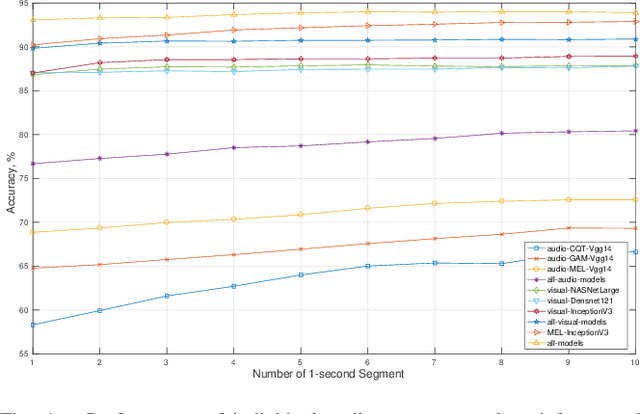

In this paper, we present deep learning frameworks for audio-visual scene classification (SC) and indicate how individual visual and audio features as well as their combination affect SC performance. Our extensive experiments, which are conducted on DCASE (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) Task 1B development dataset, achieve the best classification accuracy of 82.2%, 91.1%, and 93.9% with audio input only, visual input only, and both audio-visual input, respectively. The highest classification accuracy of 93.9%, obtained from an ensemble of audio-based and visual-based frameworks, shows an improvement of 16.5% compared with DCASE baseline.
A Low-Compexity Deep Learning Framework For Acoustic Scene Classification
Jun 12, 2021
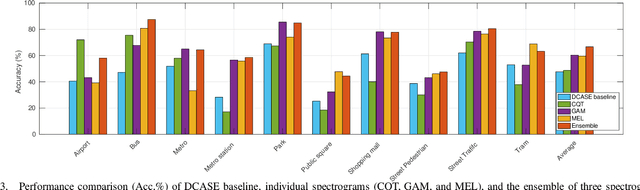
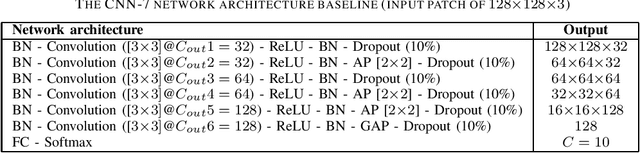
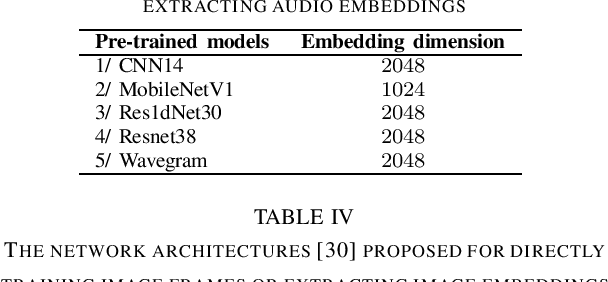
In this paper, we presents a low-complexity deep learning frameworks for acoustic scene classification (ASC). The proposed framework can be separated into three main steps: Front-end spectrogram extraction, back-end classification, and late fusion of predicted probabilities. First, we use Mel filter, Gammatone filter and Constant Q Transfrom (CQT) to transform raw audio signal into spectrograms, where both frequency and temporal features are presented. Three spectrograms are then fed into three individual back-end convolutional neural networks (CNNs), classifying into ten urban scenes. Finally, a late fusion of three predicted probabilities obtained from three CNNs is conducted to achieve the final classification result. To reduce the complexity of our proposed CNN network, we apply two model compression techniques: model restriction and decomposed convolution. Our extensive experiments, which are conducted on DCASE 2021 (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) Task 1A development dataset, achieve a low-complexity CNN based framework with 128 KB trainable parameters and the best classification accuracy of 66.7%, improving DCASE baseline by 19.0%
Inception-Based Network and Multi-Spectrogram Ensemble Applied For Predicting Respiratory Anomalies and Lung Diseases
Dec 26, 2020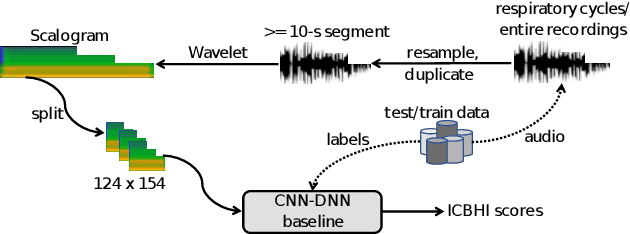
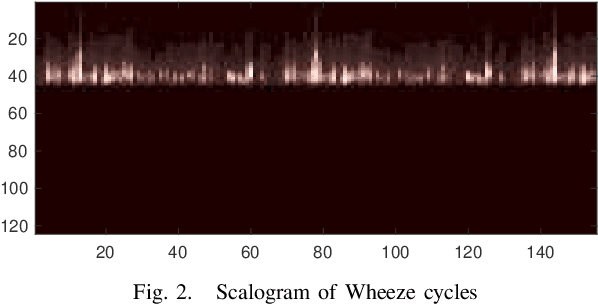
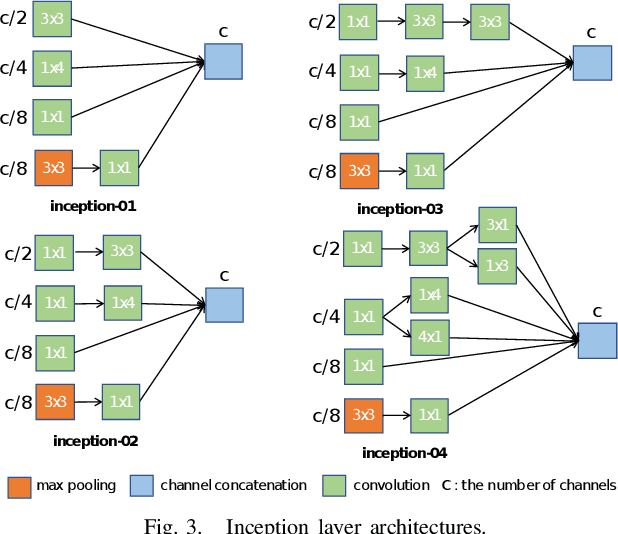

This paper presents an inception-based deep neural network for detecting lung diseases using respiratory sound input. Recordings of respiratory sound collected from patients are firstly transformed into spectrograms where both spectral and temporal information are well presented, referred to as front-end feature extraction. These spectrograms are then fed into the proposed network, referred to as back-end classification, for detecting whether patients suffer from lung-relevant diseases. Our experiments, conducted over the ICBHI benchmark meta-dataset of respiratory sound, achieve competitive ICBHI scores of 0.53/0.45 and 0.87/0.85 regarding respiratory anomaly and disease detection, respectively.
Multi-Modal Video Forensic Platform for Investigating Post-Terrorist Attack Scenarios
Apr 02, 2020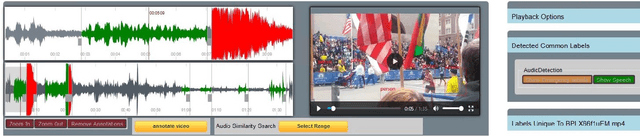
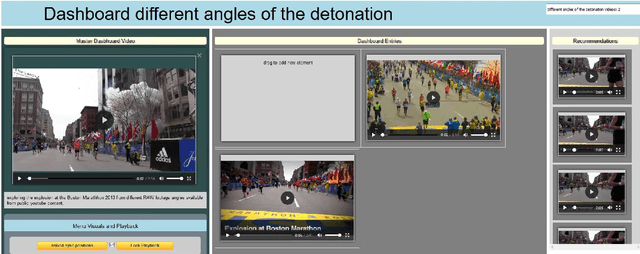
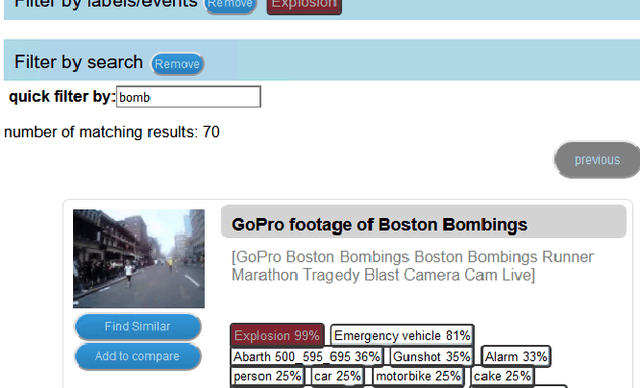
The forensic investigation of a terrorist attack poses a significant challenge to the investigative authorities, as often several thousand hours of video footage must be viewed. Large scale Video Analytic Platforms (VAP) assist law enforcement agencies (LEA) in identifying suspects and securing evidence. Current platforms focus primarily on the integration of different computer vision methods and thus are restricted to a single modality. We present a video analytic platform that integrates visual and audio analytic modules and fuses information from surveillance cameras and video uploads from eyewitnesses. Videos are analyzed according their acoustic and visual content. Specifically, Audio Event Detection is applied to index the content according to attack-specific acoustic concepts. Audio similarity search is utilized to identify similar video sequences recorded from different perspectives. Visual object detection and tracking are used to index the content according to relevant concepts. Innovative user-interface concepts are introduced to harness the full potential of the heterogeneous results of the analytical modules, allowing investigators to more quickly follow-up on leads and eyewitness reports.