 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScattering Transform for Auditory Attention Decoding
Feb 26, 2026The use of hearing aids will increase in the coming years due to demographic change. One open problem that remains to be solved by a new generation of hearing aids is the cocktail party problem. A possible solution is electroencephalography-based auditory attention decoding. This has been the subject of several studies in recent years, which have in common that they use the same preprocessing methods in most cases. In this work, in order to achieve an advantage, the use of a scattering transform is proposed as an alternative to these preprocessing methods. The two-layer scattering transform is compared with a regular filterbank, the synchrosqueezing short-time Fourier transform and the common preprocessing. To demonstrate the performance, the known and the proposed preprocessing methods are compared for different classification tasks on two widely used datasets, provided by the KU Leuven (KUL) and the Technical University of Denmark (DTU). Both established and new neural-network-based models, CNNs, LSTMs, and recent Transformer/graph-based models are used for classification. Various evaluation strategies were compared, with a focus on the task of classifying speakers who are unknown from the training. We show that the two-layer scattering transform can significantly improve the performance for subject-related conditions, especially on the KUL dataset. However, on the DTU dataset, this only applies to some of the models, or when larger amounts of training data are provided, as in 10-fold cross-validation. This suggests that the scattering transform is capable of extracting additional relevant information.
Equilibrium Model with Anisotropy for Model-Based Reconstruction in Magnetic Particle Imaging
Mar 01, 2024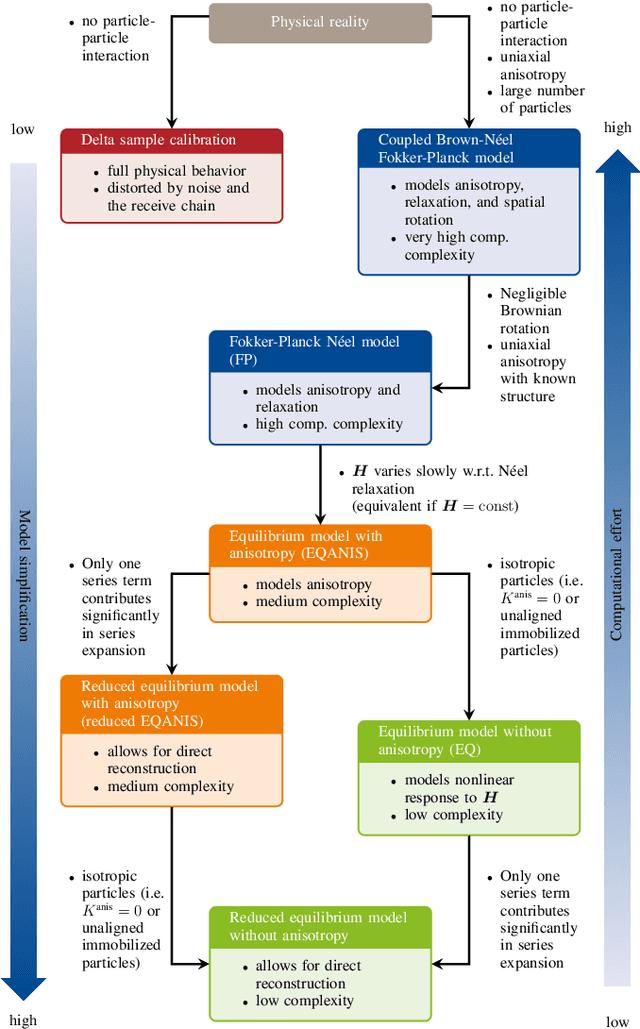
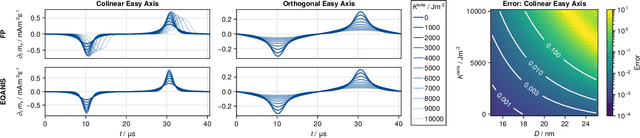
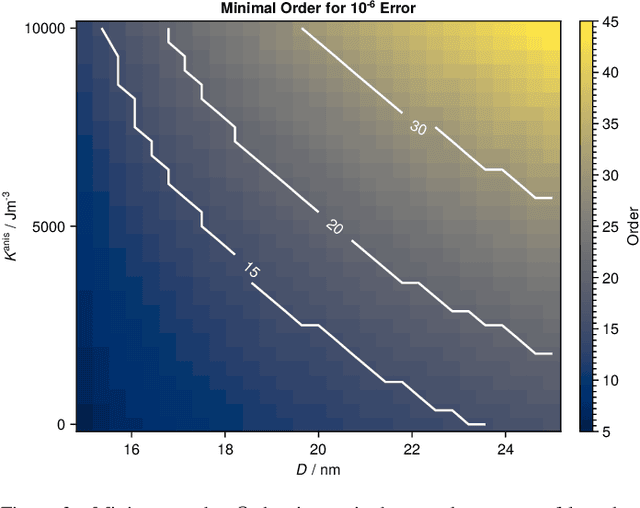

Magnetic particle imaging is a tracer-based tomographic imaging technique that allows the concentration of magnetic nanoparticles to be determined with high spatio-temporal resolution. To reconstruct an image of the tracer concentration, the magnetization dynamics of the particles must be accurately modeled. A popular ensemble model is based on solving the Fokker-Plank equation, taking into account either Brownian or N\'eel dynamics. The disadvantage of this model is that it is computationally expensive due to an underlying stiff differential equation. A simplified model is the equilibrium model, which can be evaluated directly but in most relevant cases it suffers from a non-negligible modeling error. In the present work, we investigate an extended version of the equilibrium model that can account for particle anisotropy. We show that this model can be expressed as a series of Bessel functions, which can be truncated based on a predefined accuracy, leading to very short computation times, which are about three orders of magnitude lower than equivalent Fokker-Planck computation times. We investigate the accuracy of the model for 2D Lissajous MPI sequences and show that the difference between the Fokker-Planck and the equilibrium model with anisotropy is sufficiently small so that the latter model can be used for image reconstruction on experimental data with only marginal loss of image quality, even compared to a system matrix-based reconstruction.
L-SeqSleepNet: Whole-cycle Long Sequence Modelling for Automatic Sleep Staging
Jan 25, 2023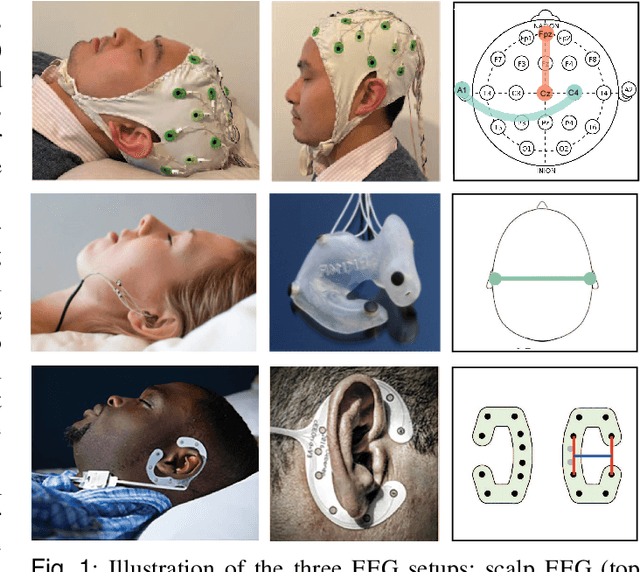
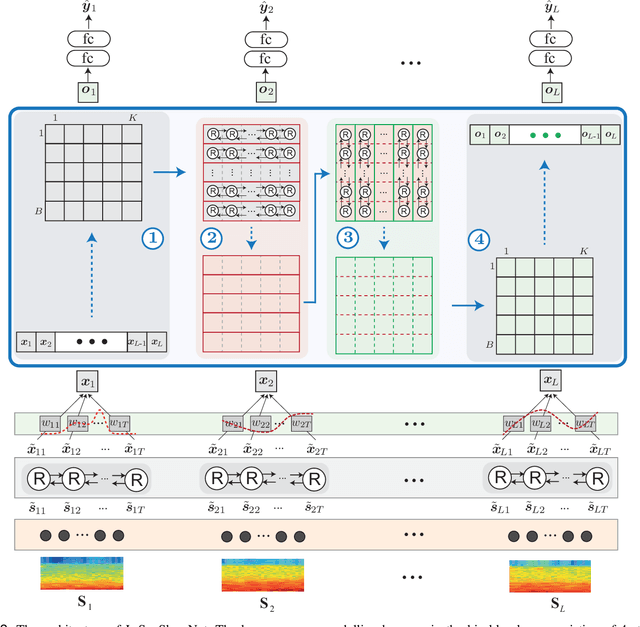
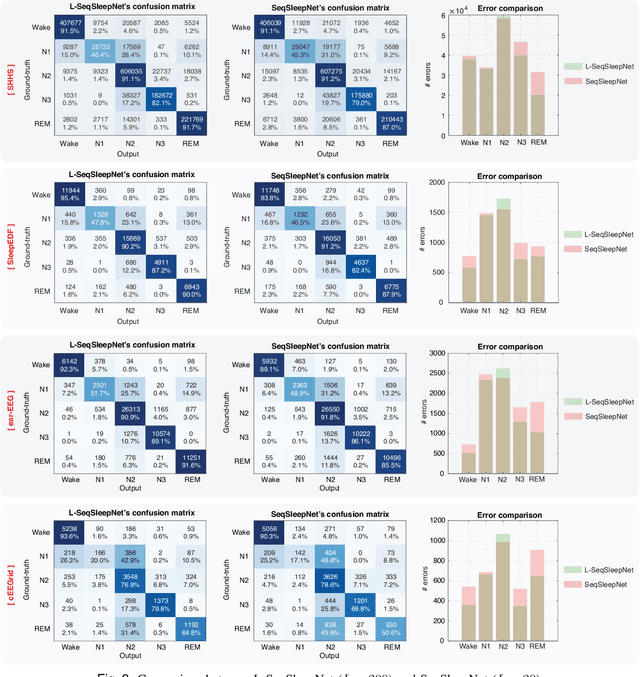
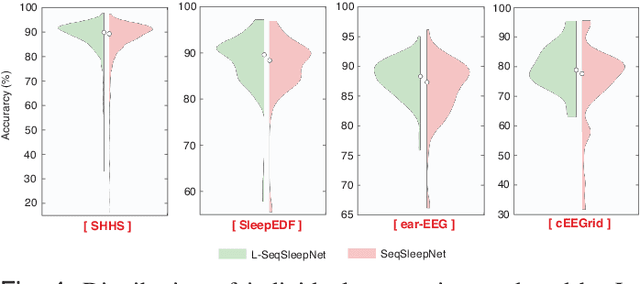
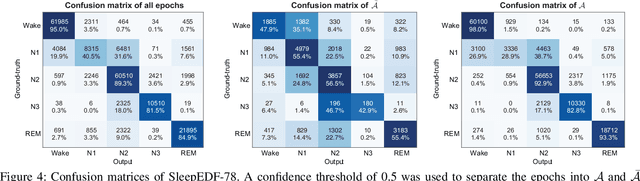
Human sleep is cyclical with a period of approximately 90 minutes, implying long temporal dependency in the sleep data. Yet, exploring this long-term dependency when developing sleep staging models has remained untouched. In this work, we show that while encoding the logic of a whole sleep cycle is crucial to improve sleep staging performance, the sequential modelling approach in existing state-of-the-art deep learning models are inefficient for that purpose. We thus introduce a method for efficient long sequence modelling and propose a new deep learning model, L-SeqSleepNet, which takes into account whole-cycle sleep information for sleep staging. Evaluating L-SeqSleepNet on four distinct databases of various sizes, we demonstrate state-of-the-art performance obtained by the model over three different EEG setups, including scalp EEG in conventional Polysomnography (PSG), in-ear EEG, and around-the-ear EEG (cEEGrid), even with a single EEG channel input. Our analyses also show that L-SeqSleepNet is able to alleviate the predominance of N2 sleep (the major class in terms of classification) to bring down errors in other sleep stages. Moreover the network becomes much more robust, meaning that for all subjects where the baseline method had exceptionally poor performance, their performance are improved significantly. Finally, the computation time only grows at a sub-linear rate when the sequence length increases.
Polyphonic audio event detection: multi-label or multi-class multi-task classification problem?
Jan 29, 2022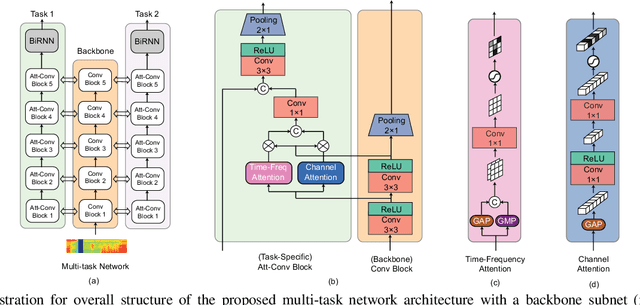
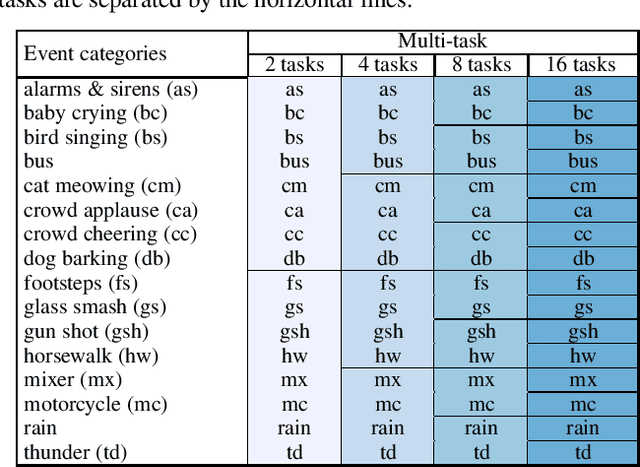
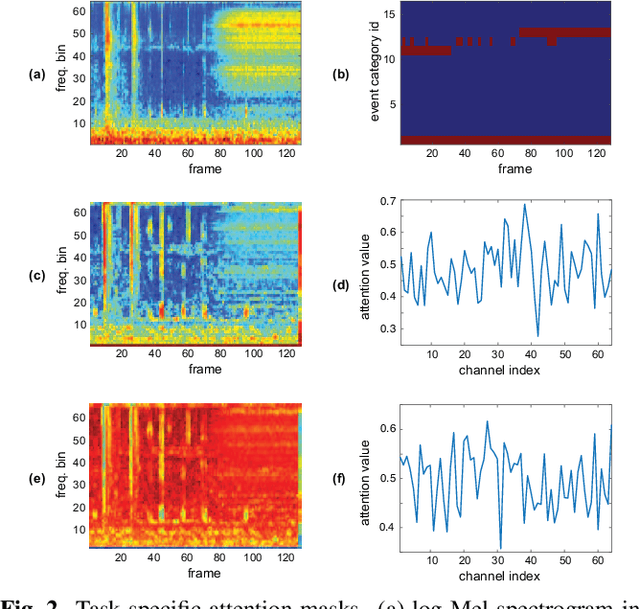
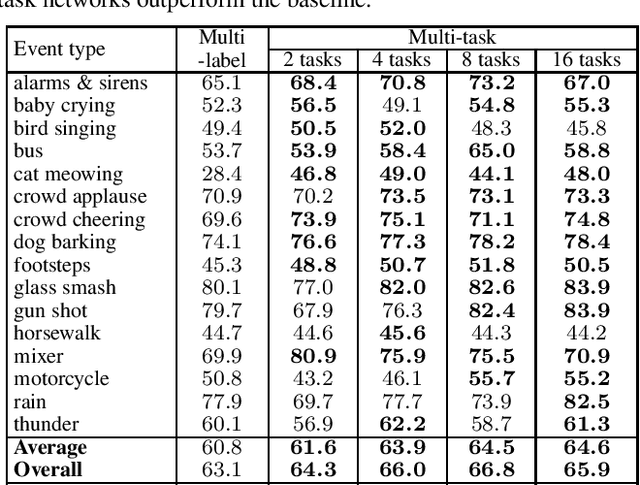
Polyphonic events are the main error source of audio event detection (AED) systems. In deep-learning context, the most common approach to deal with event overlaps is to treat the AED task as a multi-label classification problem. By doing this, we inherently consider multiple one-vs.-rest classification problems, which are jointly solved by a single (i.e. shared) network. In this work, to better handle polyphonic mixtures, we propose to frame the task as a multi-class classification problem by considering each possible label combination as one class. To circumvent the large number of arising classes due to combinatorial explosion, we divide the event categories into multiple groups and construct a multi-task problem in a divide-and-conquer fashion, where each of the tasks is a multi-class classification problem. A network architecture is then devised for multi-class multi-task modelling. The network is composed of a backbone subnet and multiple task-specific subnets. The task-specific subnets are designed to learn time-frequency and channel attention masks to extract features for the task at hand from the common feature maps learned by the backbone. Experiments on the TUT-SED-Synthetic-2016 with high degree of event overlap show that the proposed approach results in more favorable performance than the common multi-label approach.
Pediatric Automatic Sleep Staging: A comparative study of state-of-the-art deep learning methods
Aug 23, 2021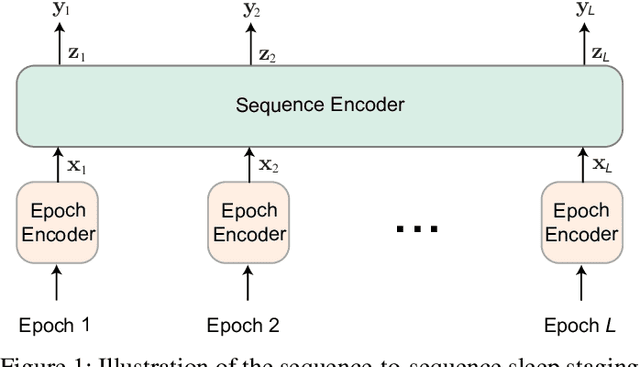

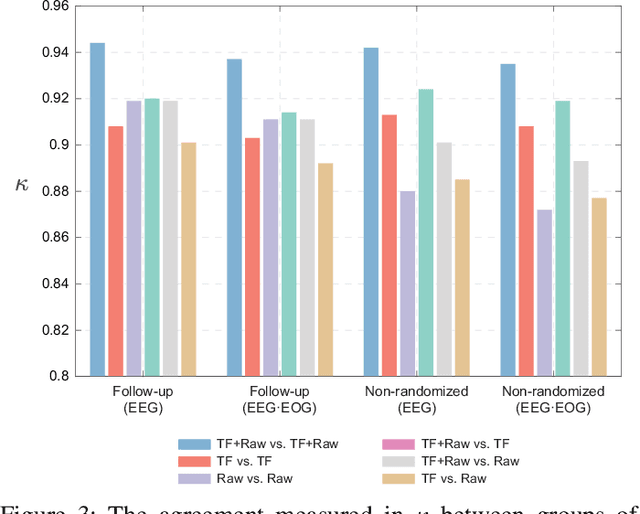
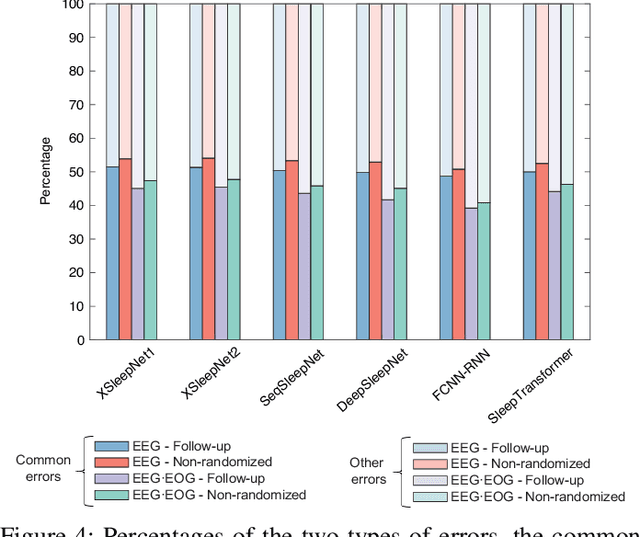
Despite the tremendous progress recently made towards automatic sleep staging in adults, it is currently known if the most advanced algorithms generalize to the pediatric population, which displays distinctive characteristics in overnight polysomnography (PSG). To answer the question, in this work, we conduct a large-scale comparative study on the state-of-the-art deep learning methods for pediatric automatic sleep staging. A selection of six different deep neural networks with diverging features are adopted to evaluate a sample of more than 1,200 children across a wide spectrum of obstructive sleep apnea (OSA) severity. Our experimental results show that the performance of automated pediatric sleep staging when evaluated on new subjects is equivalent to the expert-level one reported on adults, reaching an overall accuracy of 87.0%, a Cohen's kappa of 0.829, and a macro F1-score of 83.5% in case of single-channel EEG. The performance is further improved when dual-channel EEG$\cdot$EOG are used, reaching an accuracy of 88.2%, a Cohen's kappa of 0.844, and a macro F1-score of 85.1%. The results also show that the studied algorithms are robust to concept drift when the training and test data were recorded 7-months apart. Detailed analyses further demonstrate "almost perfect" agreement between the automatic scorers to one another and their similar behavioral patterns on the staging errors.
SleepTransformer: Automatic Sleep Staging with Interpretability and Uncertainty Quantification
May 23, 2021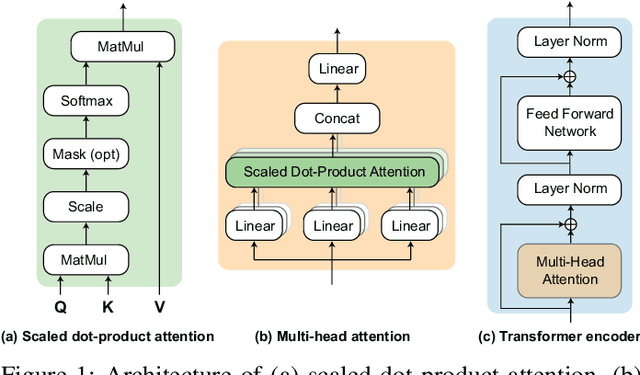
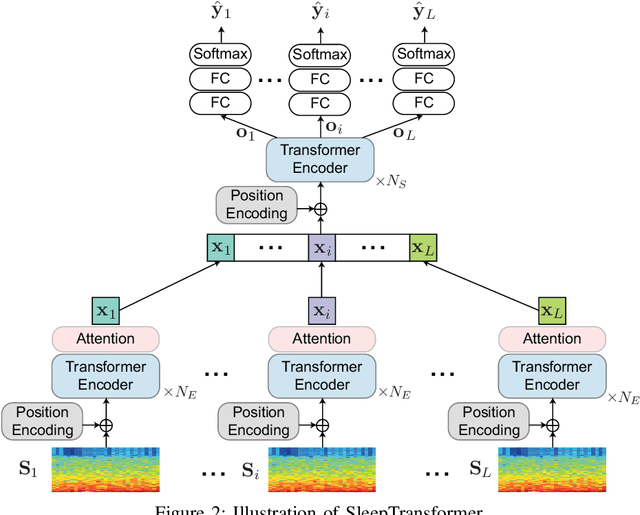

Black-box skepticism is one of the main hindrances impeding deep-learning-based automatic sleep scoring from being used in clinical environments. Towards interpretability, this work proposes a sequence-to-sequence sleep-staging model, namely SleepTransformer. It is based on the transformer backbone whose self-attention scores offer interpretability of the model's decisions at both the epoch and sequence level. At the epoch level, the attention scores can be encoded as a heat map to highlight sleep-relevant features captured from the input EEG signal. At the sequence level, the attention scores are visualized as the influence of different neighboring epochs in an input sequence (i.e. the context) to recognition of a target epoch, mimicking the way manual scoring is done by human experts. We further propose a simple yet efficient method to quantify uncertainty in the model's decisions. The method, which is based on entropy, can serve as a metric for deferring low-confidence epochs to a human expert for further inspection. Additionally, we demonstrate that the proposed SleepTransformer outperforms existing methods at a lower computational cost and achieves state-of-the-art performance on two experimental databases of different sizes.
Multi-view Audio and Music Classification
Mar 03, 2021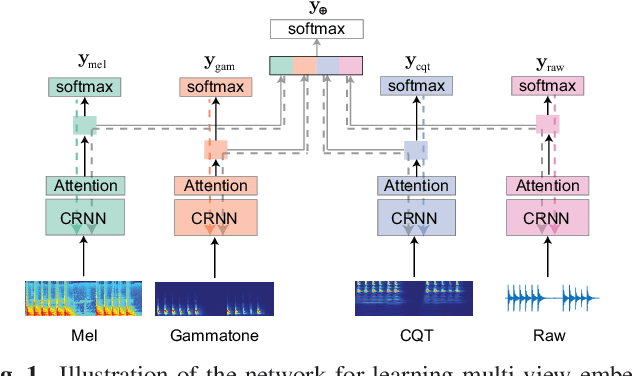

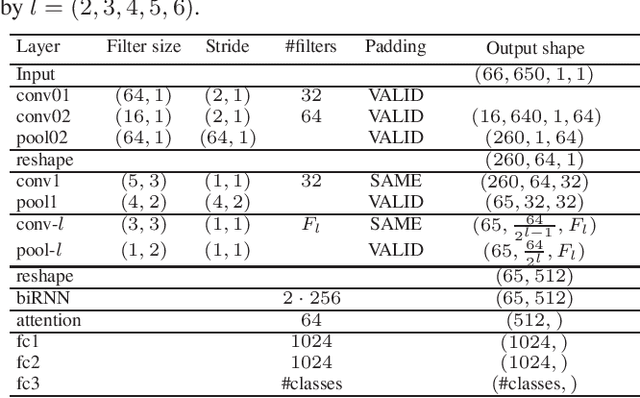

We propose in this work a multi-view learning approach for audio and music classification. Considering four typical low-level representations (i.e. different views) commonly used for audio and music recognition tasks, the proposed multi-view network consists of four subnetworks, each handling one input types. The learned embedding in the subnetworks are then concatenated to form the multi-view embedding for classification similar to a simple concatenation network. However, apart from the joint classification branch, the network also maintains four classification branches on the single-view embedding of the subnetworks. A novel method is then proposed to keep track of the learning behavior on the classification branches and adapt their weights to proportionally blend their gradients for network training. The weights are adapted in such a way that learning on a branch that is generalizing well will be encouraged whereas learning on a branch that is overfitting will be slowed down. Experiments on three different audio and music classification tasks show that the proposed multi-view network not only outperforms the single-view baselines but also is superior to the multi-view baselines based on concatenation and late fusion.
Inception-Based Network and Multi-Spectrogram Ensemble Applied For Predicting Respiratory Anomalies and Lung Diseases
Dec 26, 2020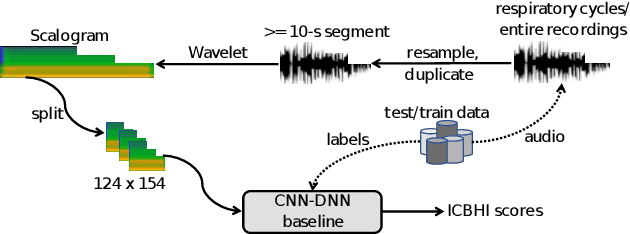
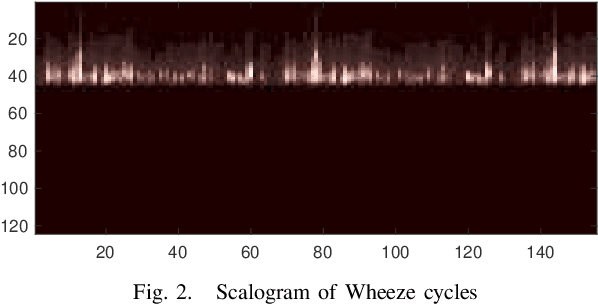
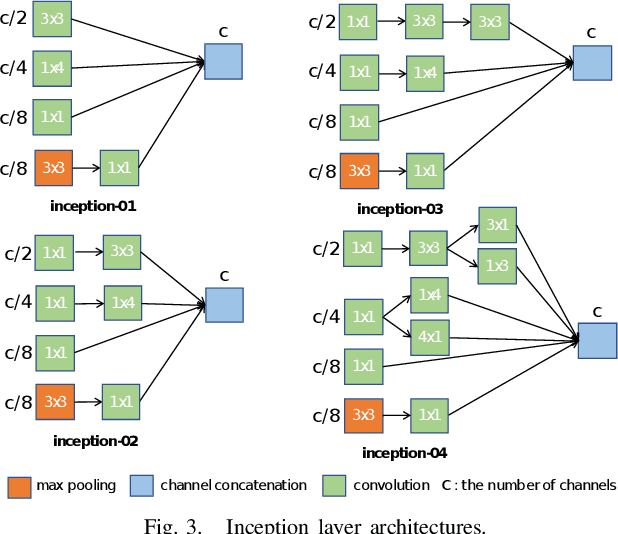

This paper presents an inception-based deep neural network for detecting lung diseases using respiratory sound input. Recordings of respiratory sound collected from patients are firstly transformed into spectrograms where both spectral and temporal information are well presented, referred to as front-end feature extraction. These spectrograms are then fed into the proposed network, referred to as back-end classification, for detecting whether patients suffer from lung-relevant diseases. Our experiments, conducted over the ICBHI benchmark meta-dataset of respiratory sound, achieve competitive ICBHI scores of 0.53/0.45 and 0.87/0.85 regarding respiratory anomaly and disease detection, respectively.
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020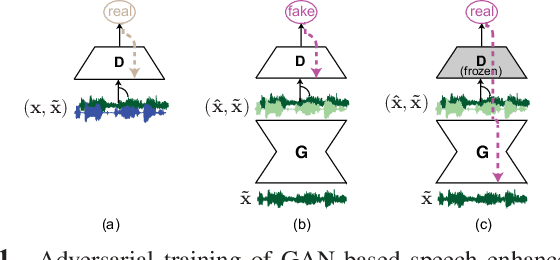
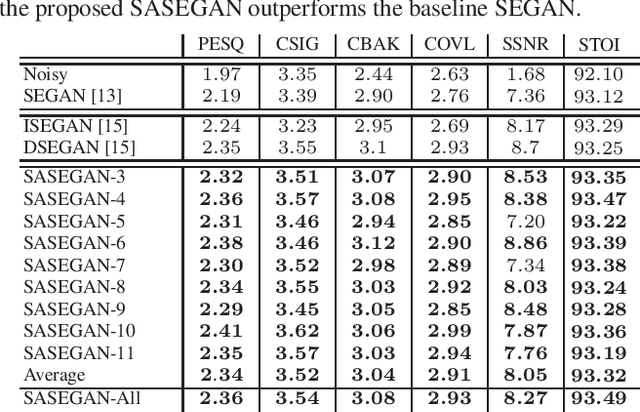
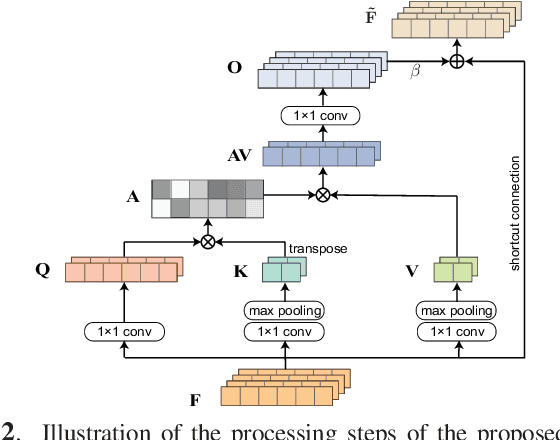
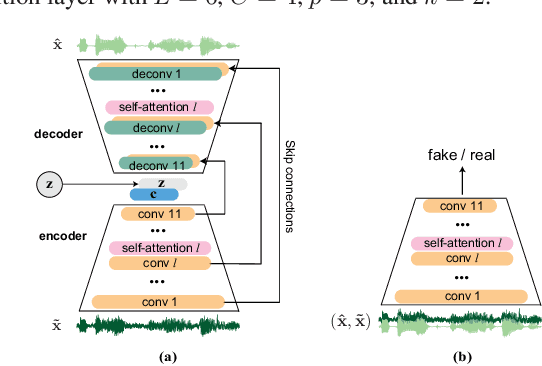
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.
On Multitask Loss Function for Audio Event Detection and Localization
Sep 11, 2020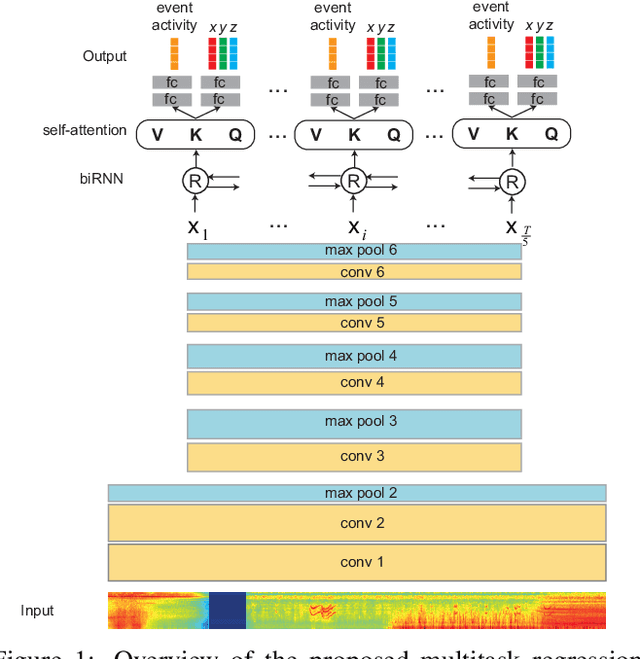
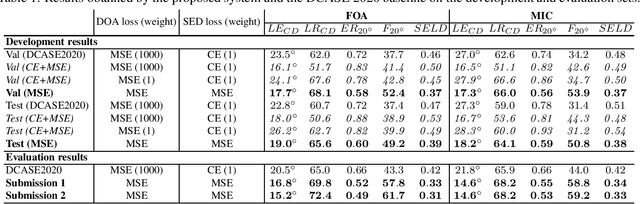
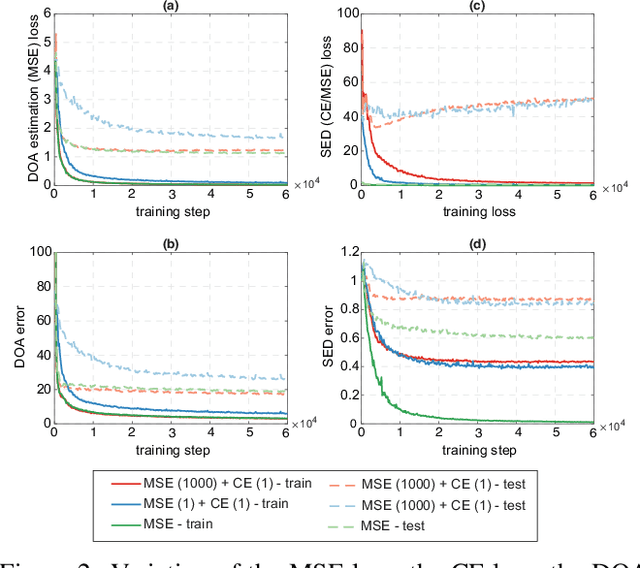
Audio event localization and detection (SELD) have been commonly tackled using multitask models. Such a model usually consists of a multi-label event classification branch with sigmoid cross-entropy loss for event activity detection and a regression branch with mean squared error loss for direction-of-arrival estimation. In this work, we propose a multitask regression model, in which both (multi-label) event detection and localization are formulated as regression problems and use the mean squared error loss homogeneously for model training. We show that the common combination of heterogeneous loss functions causes the network to underfit the data whereas the homogeneous mean squared error loss leads to better convergence and performance. Experiments on the development and validation sets of the DCASE 2020 SELD task demonstrate that the proposed system also outperforms the DCASE 2020 SELD baseline across all the detection and localization metrics, reducing the overall SELD error (the combined metric) by approximately 10% absolute.