 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Power Iteration Method for Differentially Private PCA
Feb 13, 2026We study $(ε,δ)$-differentially private algorithms for the problem of approximately computing the top singular vector of a matrix $A\in\mathbb{R}^{n\times d}$ where each row of $A$ is a datapoint in $\mathbb{R}^{d}$. In our privacy model, neighboring inputs differ by one single row/datapoint. We study the private variant of the power iteration method, which is widely adopted in practice. Our algorithm is based on a filtering technique which adapts to the coherence parameter of the input matrix. This technique provides a utility that goes beyond the worst-case guarantees for matrices with low coherence parameter. Our work departs from and complements the work by Hardt-Roth (STOC 2013) which designed a private power iteration method for the privacy model where neighboring inputs differ in one single entry by at most 1.
Efficient Adaptive Optimization via Subset-Norm and Subspace-Momentum: Fast, Memory-Reduced Training with Convergence Guarantees
Nov 11, 2024We introduce two complementary techniques for efficient adaptive optimization that reduce memory requirements while accelerating training of large-scale neural networks. The first technique, Subset-Norm adaptive step size, generalizes AdaGrad-Norm and AdaGrad(-Coordinate) by reducing the second moment term's memory footprint from $O(d)$ to $O(\sqrt{d})$ through step-size sharing, where $d$ is the model size. For non-convex smooth objectives under coordinate-wise sub-gaussian gradient noise, we prove a noise-adapted high-probability convergence guarantee showing improved dimensional dependence over existing methods. Our second technique, Subspace-Momentum, reduces the momentum state's memory footprint by operating in a low-dimensional subspace while applying standard SGD in the orthogonal complement. We establish high-probability convergence rates under similar relaxed assumptions. Empirical evaluation on LLaMA models from 60M to 1B parameters demonstrates the effectiveness of our methods, where combining subset-norm with subspace-momentum achieves Adam's validation perplexity in approximately half the training tokens (6.8B vs 13.1B) while using only 20% of the Adam's optimizer-states memory footprint and requiring minimal additional hyperparameter tuning.
Improved Worst-Group Robustness via Classifier Retraining on Independent Splits
Apr 20, 2022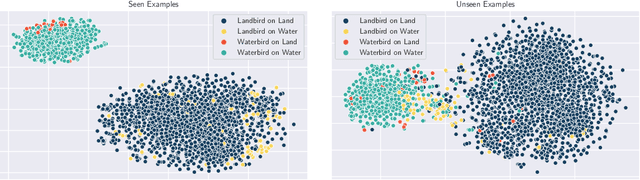
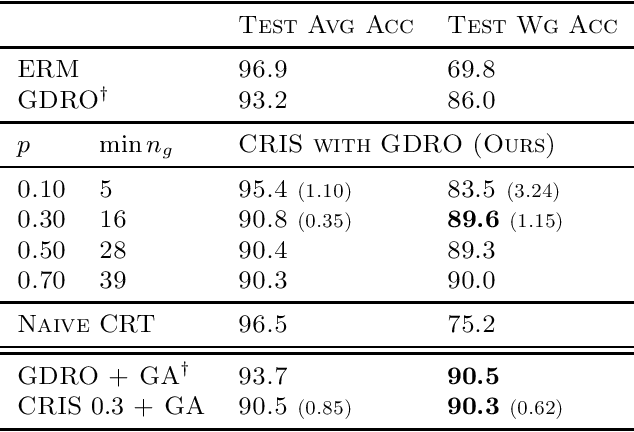
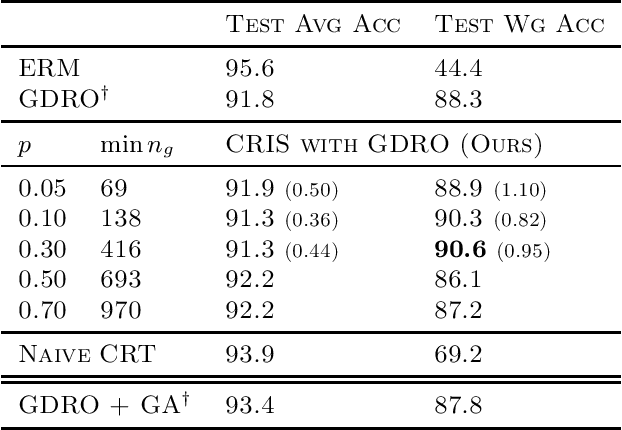
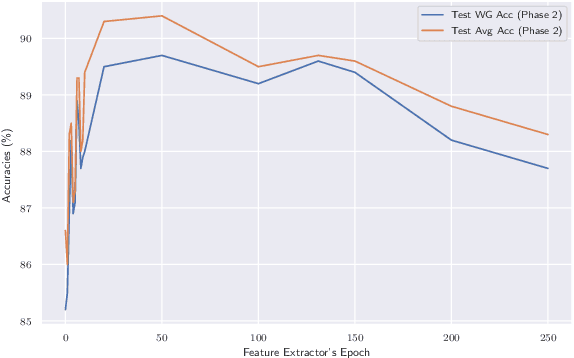
High-capacity deep neural networks (DNNs) trained with Empirical Risk Minimization (ERM) often suffer from poor worst-group accuracy despite good on-average performance, where worst-group accuracy measures a model's robustness towards certain subpopulations of the input space. Spurious correlations and memorization behaviors of ERM trained DNNs are typically attributed to this degradation in performance. We develop a method, called CRIS, that address these issues by performing robust classifier retraining on independent splits of the dataset. This results in a simple method that improves upon state-of-the-art methods, such as Group DRO, on standard datasets while relying on much fewer group labels and little additional hyperparameter tuning.
Linear Constraints Learning for Spiking Neurons
Mar 10, 2021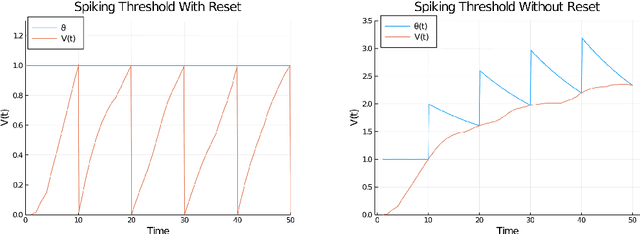

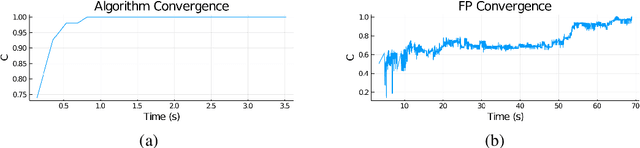

Encoding information with precise spike timings using spike-coded neurons has been shown to be more computationally powerful than rate-coded approaches. However, most existing supervised learning algorithms for spiking neurons are complicated and offer poor time complexity. To address these limitations, we propose a supervised multi-spike learning algorithm which reduces the required number of training iterations. We achieve this by formulating a large number of weight updates as a linear constraint satisfaction problem, which can be solved efficiently. Experimental results show this method offers better efficiency compared to existing algorithms on the MNIST dataset. Additionally, we provide experimental results on the classification capacity of the LIF neuron model, relative to several parameters of the system.
Multi-view Audio and Music Classification
Mar 03, 2021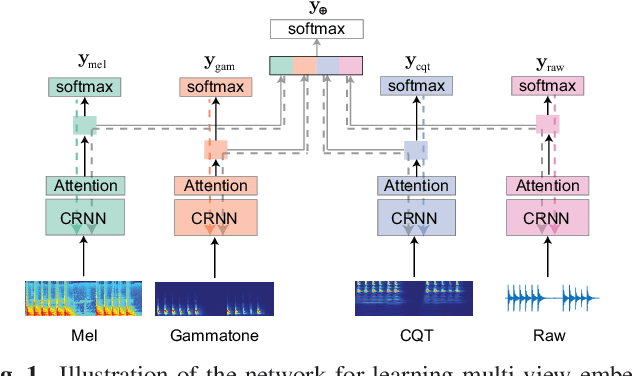

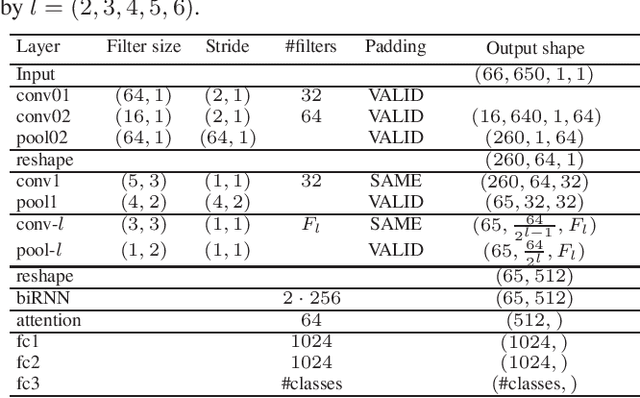

We propose in this work a multi-view learning approach for audio and music classification. Considering four typical low-level representations (i.e. different views) commonly used for audio and music recognition tasks, the proposed multi-view network consists of four subnetworks, each handling one input types. The learned embedding in the subnetworks are then concatenated to form the multi-view embedding for classification similar to a simple concatenation network. However, apart from the joint classification branch, the network also maintains four classification branches on the single-view embedding of the subnetworks. A novel method is then proposed to keep track of the learning behavior on the classification branches and adapt their weights to proportionally blend their gradients for network training. The weights are adapted in such a way that learning on a branch that is generalizing well will be encouraged whereas learning on a branch that is overfitting will be slowed down. Experiments on three different audio and music classification tasks show that the proposed multi-view network not only outperforms the single-view baselines but also is superior to the multi-view baselines based on concatenation and late fusion.
Fair and Optimal Cohort Selection for Linear Utilities
Feb 16, 2021The rise of algorithmic decision-making has created an explosion of research around the fairness of those algorithms. While there are many compelling notions of individual fairness, beginning with the work of Dwork et al., these notions typically do not satisfy desirable composition properties. To this end, Dwork and Ilvento introduced the fair cohort selection problem, which captures a specific application where a single fair classifier is composed with itself to pick a group of candidates of size exactly $k$. In this work we introduce a specific instance of cohort selection where the goal is to choose a cohort maximizing a linear utility function. We give approximately optimal polynomial-time algorithms for this problem in both an offline setting where the entire fair classifier is given at once, or an online setting where candidates arrive one at a time and are classified as they arrive.
Constraints on Hebbian and STDP learned weights of a spiking neuron
Dec 14, 2020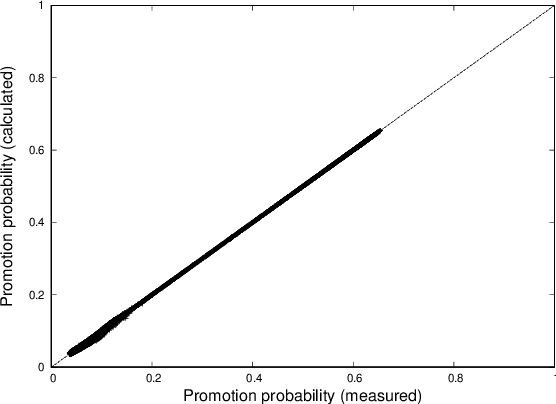
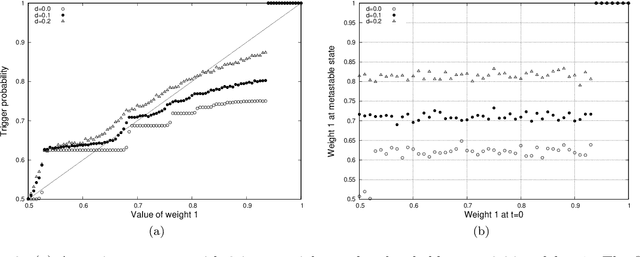
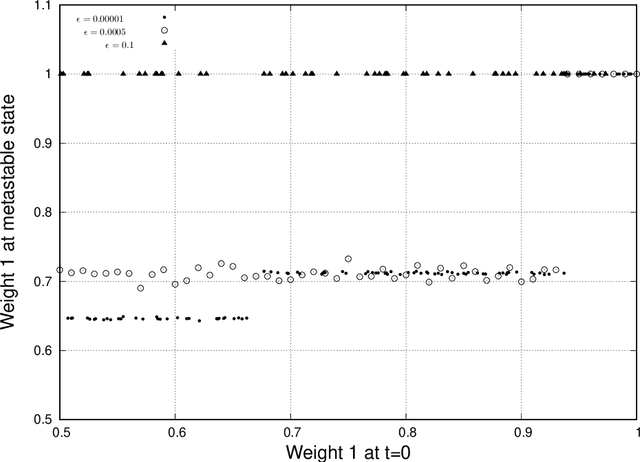
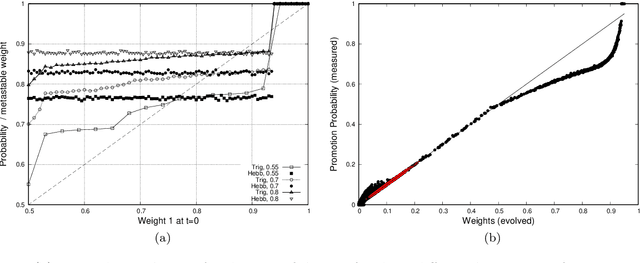
We analyse mathematically the constraints on weights resulting from Hebbian and STDP learning rules applied to a spiking neuron with weight normalisation. In the case of pure Hebbian learning, we find that the normalised weights equal the promotion probabilities of weights up to correction terms that depend on the learning rate and are usually small. A similar relation can be derived for STDP algorithms, where the normalised weight values reflect a difference between the promotion and demotion probabilities of the weight. These relations are practically useful in that they allow checking for convergence of Hebbian and STDP algorithms. Another application is novelty detection. We demonstrate this using the MNIST dataset.
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020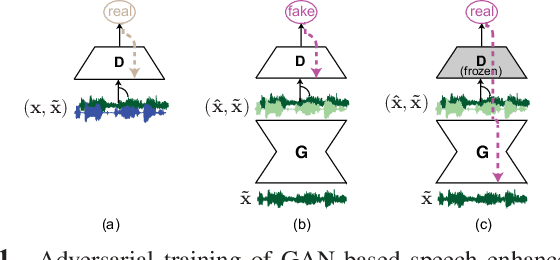
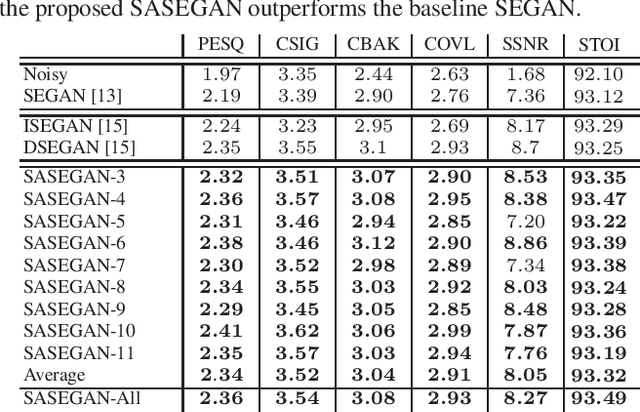
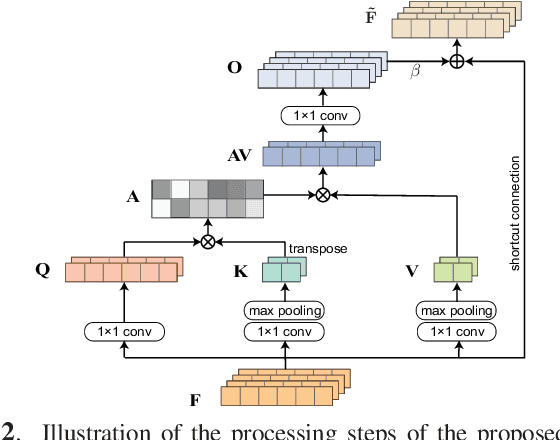
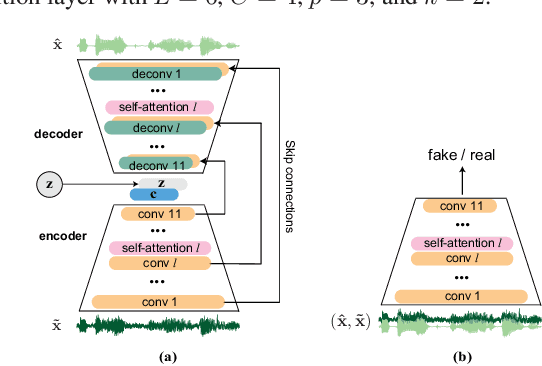
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.