 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLITZRANK: Principled Zero-shot Ranking Agents with Tournament Graphs
Feb 05, 2026Large language models have emerged as powerful zero-shot rerankers for retrieval-augmented generation, offering strong generalization without task-specific training. However, existing LLM reranking methods either rely on heuristics that fail to fully exploit the information revealed by each ranking decision or are inefficient when they do. We introduce a tournament graph framework that provides a principled foundation for $k$-wise reranking. Our key observation is that each $k$-document comparison reveals a complete tournament of $\binom{k}{2}$ pairwise preferences. These tournaments are aggregated into a global preference graph, whose transitive closure yields many additional orderings without further model invocations. We formalize when a candidate's rank is certifiably determined and design a query schedule that greedily maximizes information gain towards identifying the top-$m$ items. Our framework also gracefully handles non-transitive preferences - cycles induced by LLM judgments - by collapsing them into equivalence classes that yield principled tiered rankings. Empirically, across 14 benchmarks and 5 LLMs, our method achieves Pareto dominance over existing methods: matching or exceeding accuracy while requiring 25-40% fewer tokens than comparable approaches, and 7$\times$ fewer than pairwise methods at near-identical quality.
Efficient Adaptive Optimization via Subset-Norm and Subspace-Momentum: Fast, Memory-Reduced Training with Convergence Guarantees
Nov 11, 2024We introduce two complementary techniques for efficient adaptive optimization that reduce memory requirements while accelerating training of large-scale neural networks. The first technique, Subset-Norm adaptive step size, generalizes AdaGrad-Norm and AdaGrad(-Coordinate) by reducing the second moment term's memory footprint from $O(d)$ to $O(\sqrt{d})$ through step-size sharing, where $d$ is the model size. For non-convex smooth objectives under coordinate-wise sub-gaussian gradient noise, we prove a noise-adapted high-probability convergence guarantee showing improved dimensional dependence over existing methods. Our second technique, Subspace-Momentum, reduces the momentum state's memory footprint by operating in a low-dimensional subspace while applying standard SGD in the orthogonal complement. We establish high-probability convergence rates under similar relaxed assumptions. Empirical evaluation on LLaMA models from 60M to 1B parameters demonstrates the effectiveness of our methods, where combining subset-norm with subspace-momentum achieves Adam's validation perplexity in approximately half the training tokens (6.8B vs 13.1B) while using only 20% of the Adam's optimizer-states memory footprint and requiring minimal additional hyperparameter tuning.
High Probability Convergence of Stochastic Gradient Methods
Feb 28, 2023In this work, we describe a generic approach to show convergence with high probability for both stochastic convex and non-convex optimization with sub-Gaussian noise. In previous works for convex optimization, either the convergence is only in expectation or the bound depends on the diameter of the domain. Instead, we show high probability convergence with bounds depending on the initial distance to the optimal solution. The algorithms use step sizes analogous to the standard settings and are universal to Lipschitz functions, smooth functions, and their linear combinations. This method can be applied to the non-convex case. We demonstrate an $O((1+\sigma^{2}\log(1/\delta))/T+\sigma/\sqrt{T})$ convergence rate when the number of iterations $T$ is known and an $O((1+\sigma^{2}\log(T/\delta))/\sqrt{T})$ convergence rate when $T$ is unknown for SGD, where $1-\delta$ is the desired success probability. These bounds improve over existing bounds in the literature. Additionally, we demonstrate that our techniques can be used to obtain high probability bound for AdaGrad-Norm (Ward et al., 2019) that removes the bounded gradients assumption from previous works. Furthermore, our technique for AdaGrad-Norm extends to the standard per-coordinate AdaGrad algorithm (Duchi et al., 2011), providing the first noise-adapted high probability convergence for AdaGrad.
META-STORM: Generalized Fully-Adaptive Variance Reduced SGD for Unbounded Functions
Sep 29, 2022
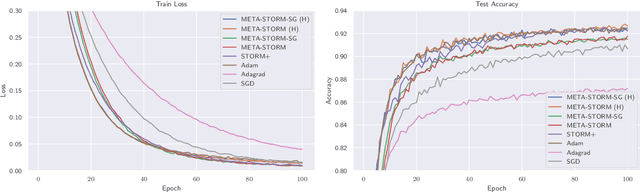
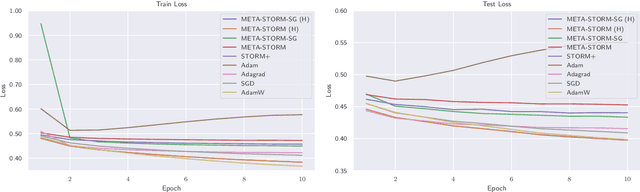
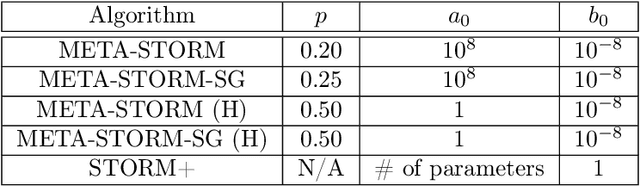
We study the application of variance reduction (VR) techniques to general non-convex stochastic optimization problems. In this setting, the recent work STORM [Cutkosky-Orabona '19] overcomes the drawback of having to compute gradients of "mega-batches" that earlier VR methods rely on. There, STORM utilizes recursive momentum to achieve the VR effect and is then later made fully adaptive in STORM+ [Levy et al., '21], where full-adaptivity removes the requirement for obtaining certain problem-specific parameters such as the smoothness of the objective and bounds on the variance and norm of the stochastic gradients in order to set the step size. However, STORM+ crucially relies on the assumption that the function values are bounded, excluding a large class of useful functions. In this work, we propose META-STORM, a generalized framework of STORM+ that removes this bounded function values assumption while still attaining the optimal convergence rate for non-convex optimization. META-STORM not only maintains full-adaptivity, removing the need to obtain problem specific parameters, but also improves the convergence rate's dependency on the problem parameters. Furthermore, META-STORM can utilize a large range of parameter settings that subsumes previous methods allowing for more flexibility in a wider range of settings. Finally, we demonstrate the effectiveness of META-STORM through experiments across common deep learning tasks. Our algorithm improves upon the previous work STORM+ and is competitive with widely used algorithms after the addition of per-coordinate update and exponential moving average heuristics.
Improved Worst-Group Robustness via Classifier Retraining on Independent Splits
Apr 20, 2022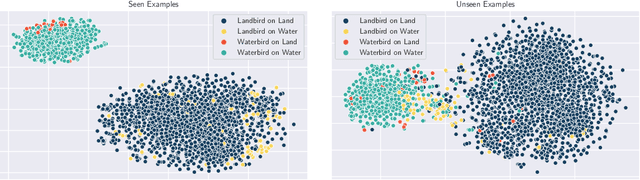
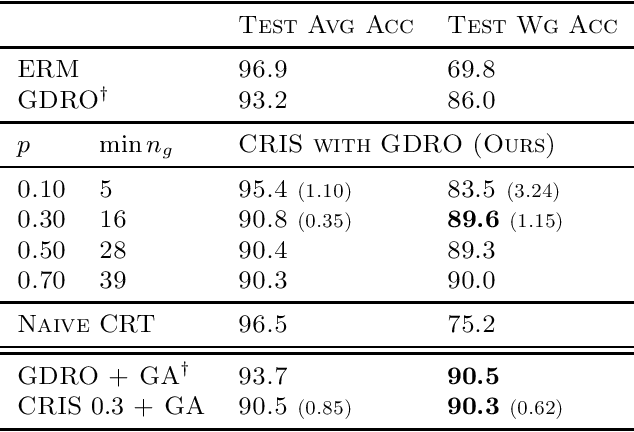
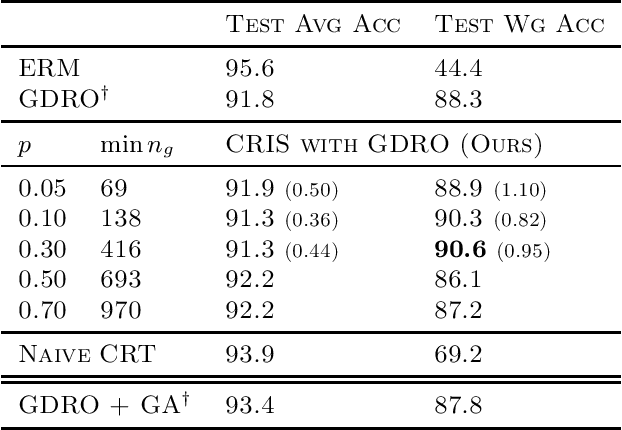
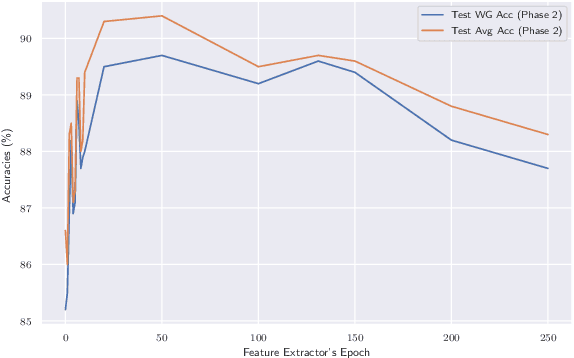
High-capacity deep neural networks (DNNs) trained with Empirical Risk Minimization (ERM) often suffer from poor worst-group accuracy despite good on-average performance, where worst-group accuracy measures a model's robustness towards certain subpopulations of the input space. Spurious correlations and memorization behaviors of ERM trained DNNs are typically attributed to this degradation in performance. We develop a method, called CRIS, that address these issues by performing robust classifier retraining on independent splits of the dataset. This results in a simple method that improves upon state-of-the-art methods, such as Group DRO, on standard datasets while relying on much fewer group labels and little additional hyperparameter tuning.