 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the hidden treasure of dialog in video question answering
Mar 26, 2021
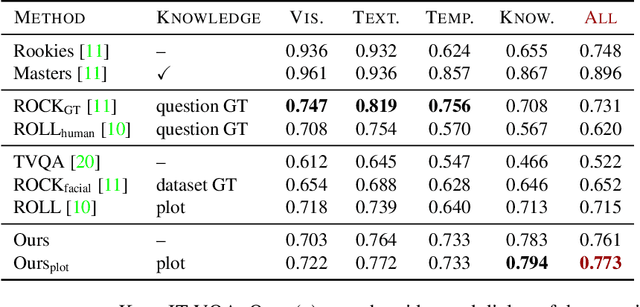
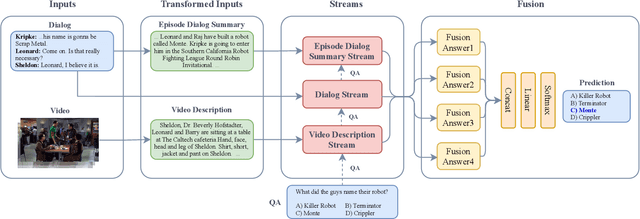

High-level understanding of stories in video such as movies and TV shows from raw data is extremely challenging. Modern video question answering (VideoQA) systems often use additional human-made sources like plot synopses, scripts, video descriptions or knowledge bases. In this work, we present a new approach to understand the whole story without such external sources. The secret lies in the dialog: unlike any prior work, we treat dialog as a noisy source to be converted into text description via dialog summarization, much like recent methods treat video. The input of each modality is encoded by transformers independently, and a simple fusion method combines all modalities, using soft temporal attention for localization over long inputs. Our model outperforms the state of the art on the KnowIT VQA dataset by a large margin, without using question-specific human annotation or human-made plot summaries. It even outperforms human evaluators who have never watched any whole episode before.
Self-Attention Generative Adversarial Network for Speech Enhancement
Oct 18, 2020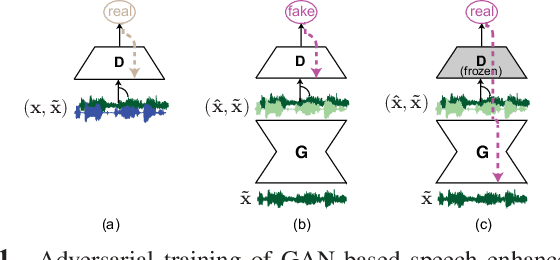
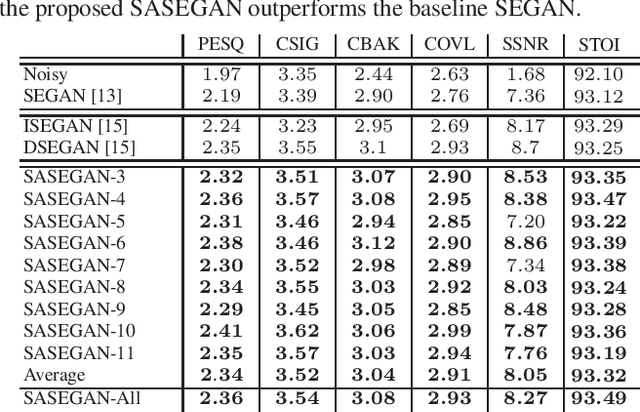
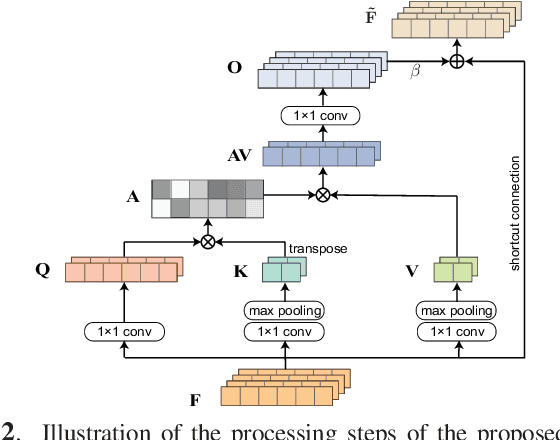
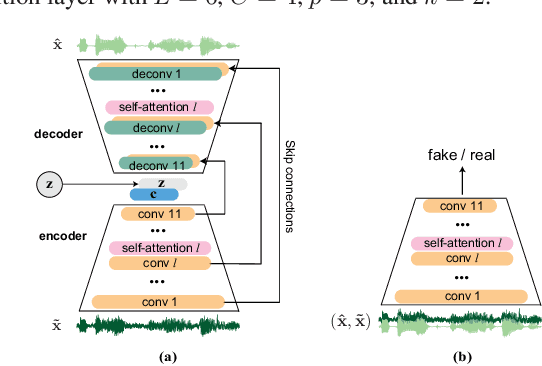
Existing generative adversarial networks (GANs) for speech enhancement solely rely on the convolution operation, which may obscure temporal dependencies across the sequence input. To remedy this issue, we propose a self-attention layer adapted from non-local attention, coupled with the convolutional and deconvolutional layers of a speech enhancement GAN (SEGAN) using raw signal input. Further, we empirically study the effect of placing the self-attention layer at the (de)convolutional layers with varying layer indices as well as at all of them when memory allows. Our experiments show that introducing self-attention to SEGAN leads to consistent improvement across the objective evaluation metrics of enhancement performance. Furthermore, applying at different (de)convolutional layers does not significantly alter performance, suggesting that it can be conveniently applied at the highest-level (de)convolutional layer with the smallest memory overhead.
On Multitask Loss Function for Audio Event Detection and Localization
Sep 11, 2020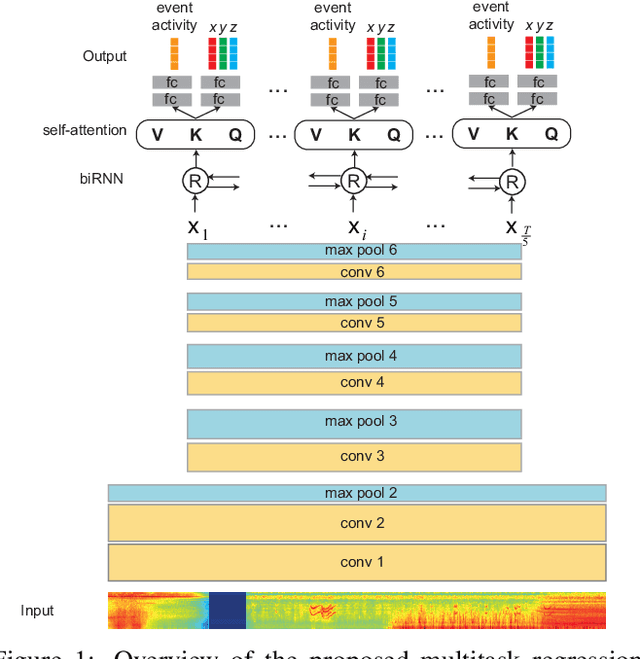
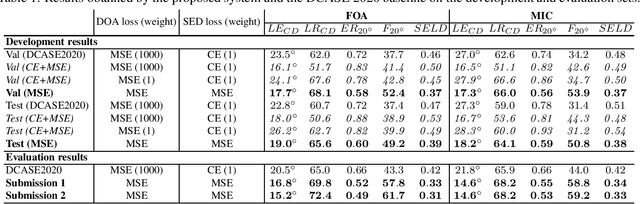
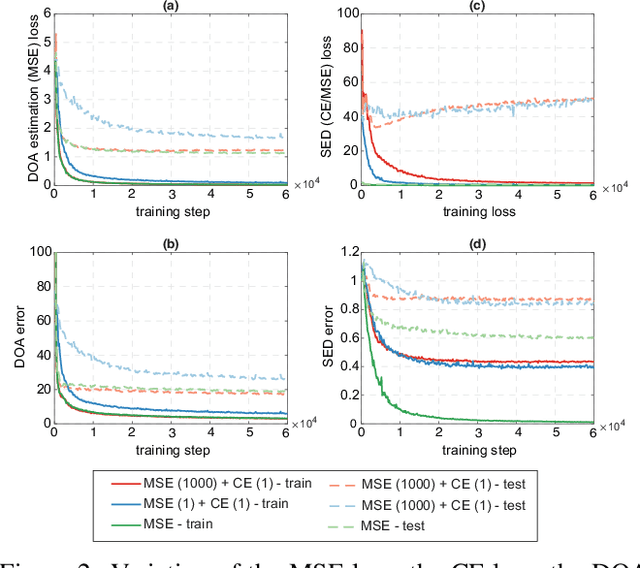
Audio event localization and detection (SELD) have been commonly tackled using multitask models. Such a model usually consists of a multi-label event classification branch with sigmoid cross-entropy loss for event activity detection and a regression branch with mean squared error loss for direction-of-arrival estimation. In this work, we propose a multitask regression model, in which both (multi-label) event detection and localization are formulated as regression problems and use the mean squared error loss homogeneously for model training. We show that the common combination of heterogeneous loss functions causes the network to underfit the data whereas the homogeneous mean squared error loss leads to better convergence and performance. Experiments on the development and validation sets of the DCASE 2020 SELD task demonstrate that the proposed system also outperforms the DCASE 2020 SELD baseline across all the detection and localization metrics, reducing the overall SELD error (the combined metric) by approximately 10% absolute.
VideoMem: Constructing, Analyzing, Predicting Short-term and Long-term Video Memorability
Dec 05, 2018



Humans share a strong tendency to memorize/forget some of the visual information they encounter. This paper focuses on providing computational models for the prediction of the intrinsic memorability of visual content. To address this new challenge, we introduce a large scale dataset (VideoMem) composed of 10,000 videos annotated with memorability scores. In contrast to previous work on image memorability -- where memorability was measured a few minutes after memorization -- memory performance is measured twice: a few minutes after memorization and again 24-72 hours later. Hence, the dataset comes with short-term and long-term memorability annotations. After an in-depth analysis of the dataset, we investigate several deep neural network based models for the prediction of video memorability. Our best model using a ranking loss achieves a Spearman's rank correlation of 0.494 for short-term memorability prediction, while our proposed model with attention mechanism provides insights of what makes a content memorable. The VideoMem dataset with pre-extracted features is publicly available.
Weakly Supervised Representation Learning for Unsynchronized Audio-Visual Events
Jul 09, 2018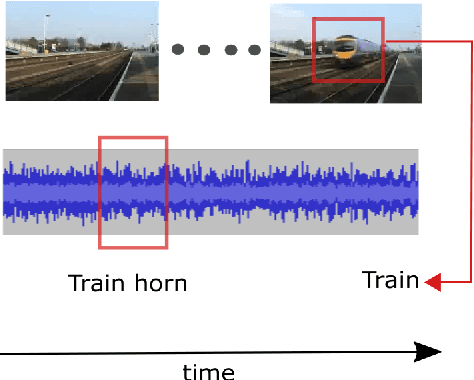
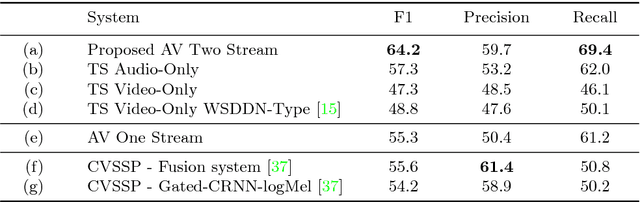
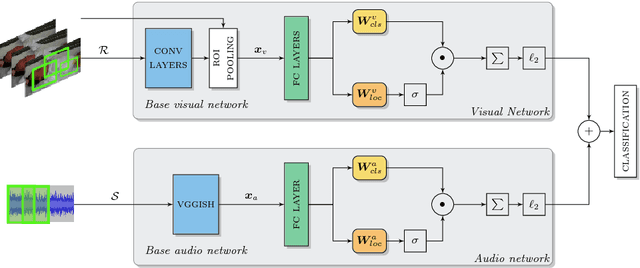
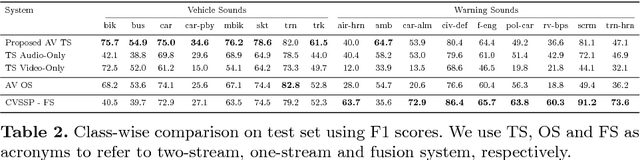
Audio-visual representation learning is an important task from the perspective of designing machines with the ability to understand complex events. To this end, we propose a novel multimodal framework that instantiates multiple instance learning. We show that the learnt representations are useful for classifying events and localizing their characteristic audio-visual elements. The system is trained using only video-level event labels without any timing information. An important feature of our method is its capacity to learn from unsynchronized audio-visual events. We achieve state-of-the-art results on a large-scale dataset of weakly-labeled audio event videos. Visualizations of localized visual regions and audio segments substantiate our system's efficacy, especially when dealing with noisy situations where modality-specific cues appear asynchronously.
Structural inpainting
Mar 27, 2018


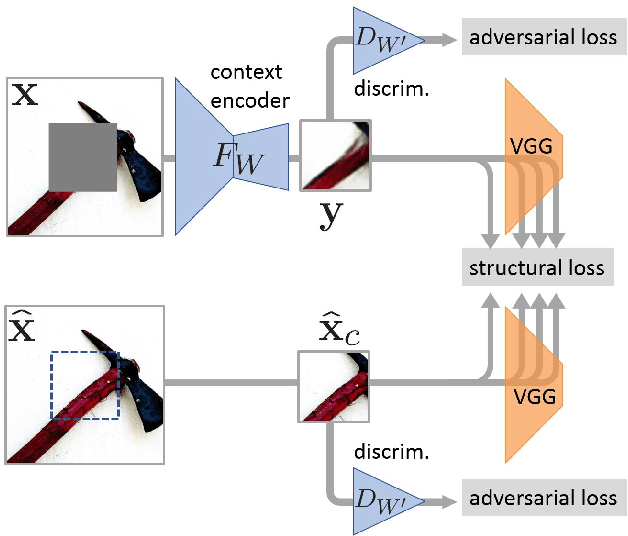
Scene-agnostic visual inpainting remains very challenging despite progress in patch-based methods. Recently, Pathak et al. 2016 have introduced convolutional "context encoders" (CEs) for unsupervised feature learning through image completion tasks. With the additional help of adversarial training, CEs turned out to be a promising tool to complete complex structures in real inpainting problems. In the present paper we propose to push further this key ability by relying on perceptual reconstruction losses at training time. We show on a wide variety of visual scenes the merit of the approach for structural inpainting, and confirm it through a user study. Combined with the optimization-based refinement of Yang et al. 2016 with neural patches, our context encoder opens up new opportunities for prior-free visual inpainting.
A Review of Audio Features and Statistical Models Exploited for Voice Pattern Design
Feb 24, 2015
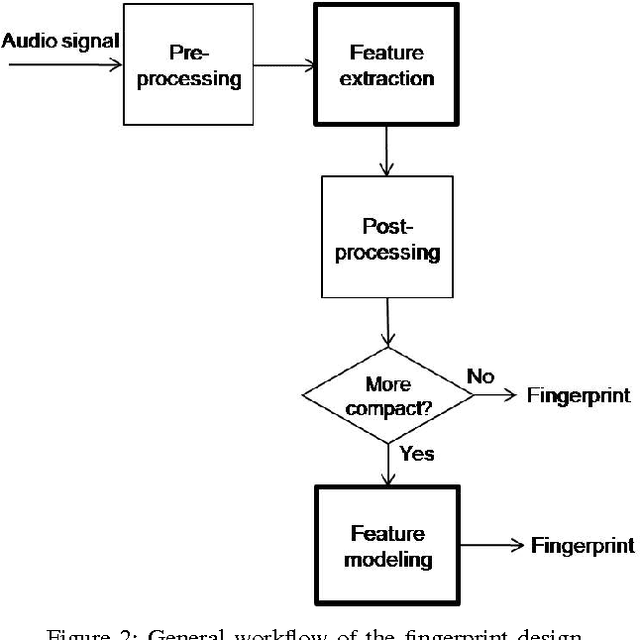
Audio fingerprinting, also named as audio hashing, has been well-known as a powerful technique to perform audio identification and synchronization. It basically involves two major steps: fingerprint (voice pattern) design and matching search. While the first step concerns the derivation of a robust and compact audio signature, the second step usually requires knowledge about database and quick-search algorithms. Though this technique offers a wide range of real-world applications, to the best of the authors' knowledge, a comprehensive survey of existing algorithms appeared more than eight years ago. Thus, in this paper, we present a more up-to-date review and, for emphasizing on the audio signal processing aspect, we focus our state-of-the-art survey on the fingerprint design step for which various audio features and their tractable statistical models are discussed.