 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaDiS: Parallelly Distributable Slimmable Neural Networks
Oct 06, 2021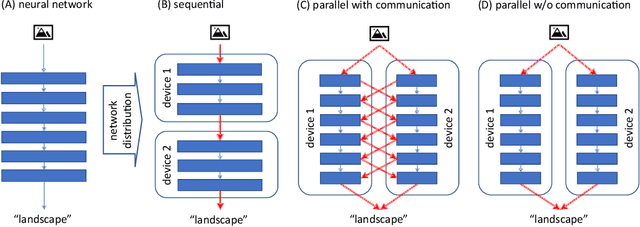

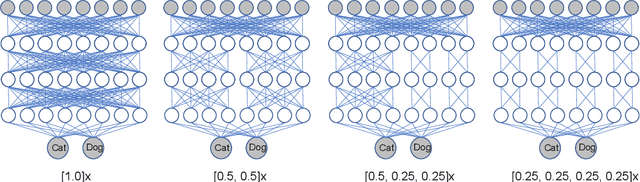

When several limited power devices are available, one of the most efficient ways to make profit of these resources, while reducing the processing latency and communication load, is to run in parallel several neural sub-networks and to fuse the result at the end of processing. However, such a combination of sub-networks must be trained specifically for each particular configuration of devices (characterized by number of devices and their capacities) which may vary over different model deployments and even within the same deployment. In this work we introduce parallelly distributable slimmable (ParaDiS) neural networks that are splittable in parallel among various device configurations without retraining. While inspired by slimmable networks allowing instant adaptation to resources on just one device, ParaDiS networks consist of several multi-device distributable configurations or switches that strongly share the parameters between them. We evaluate ParaDiS framework on MobileNet v1 and ResNet-50 architectures on ImageNet classification task. We show that ParaDiS switches achieve similar or better accuracy than the individual models, i.e., distributed models of the same structure trained individually. Moreover, we show that, as compared to universally slimmable networks that are not distributable, the accuracy of distributable ParaDiS switches either does not drop at all or drops by a maximum of 1 % only in the worst cases.
Inplace knowledge distillation with teacher assistant for improved training of flexible deep neural networks
May 18, 2021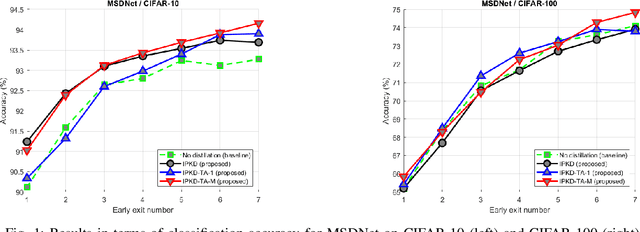
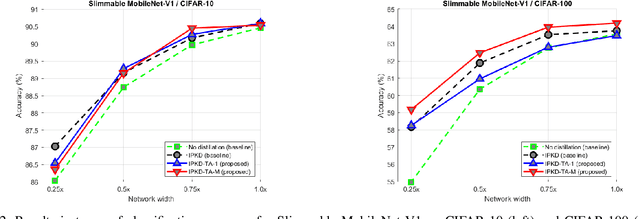
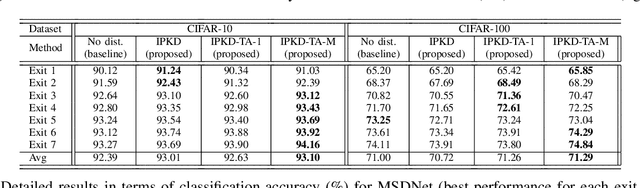
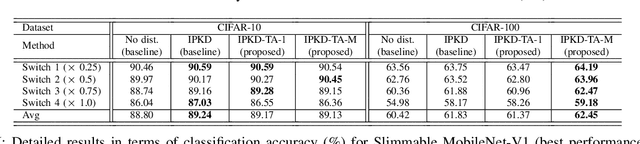
Deep neural networks (DNNs) have achieved great success in various machine learning tasks. However, most existing powerful DNN models are computationally expensive and memory demanding, hindering their deployment in devices with low memory and computational resources or in applications with strict latency requirements. Thus, several resource-adaptable or flexible approaches were recently proposed that train at the same time a big model and several resource-specific sub-models. Inplace knowledge distillation (IPKD) became a popular method to train those models and consists in distilling the knowledge from a larger model (teacher) to all other sub-models (students). In this work a novel generic training method called IPKD with teacher assistant (IPKD-TA) is introduced, where sub-models themselves become teacher assistants teaching smaller sub-models. We evaluated the proposed IPKD-TA training method using two state-of-the-art flexible models (MSDNet and Slimmable MobileNet-V1) with two popular image classification benchmarks (CIFAR-10 and CIFAR-100). Our results demonstrate that the IPKD-TA is on par with the existing state of the art while improving it in most cases.
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021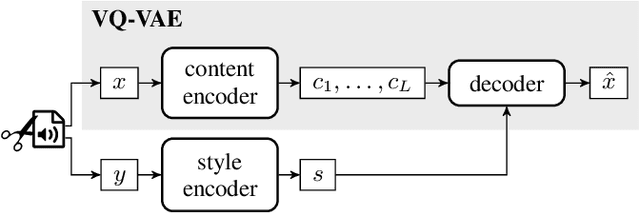
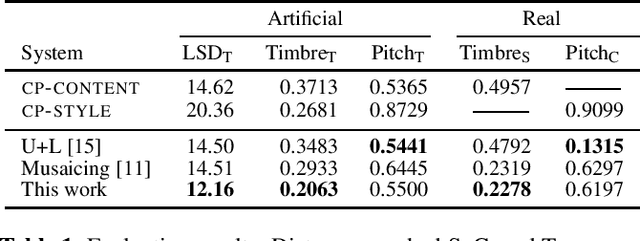
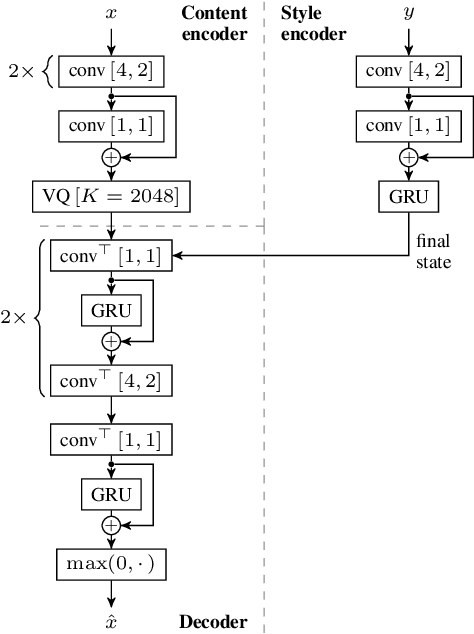
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
Identify, locate and separate: Audio-visual object extraction in large video collections using weak supervision
Nov 09, 2018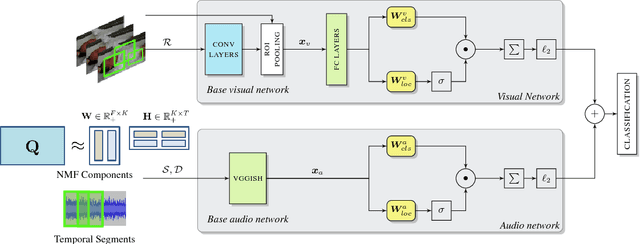
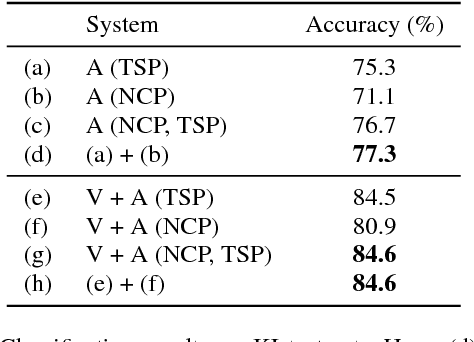


We tackle the problem of audiovisual scene analysis for weakly-labeled data. To this end, we build upon our previous audiovisual representation learning framework to perform object classification in noisy acoustic environments and integrate audio source enhancement capability. This is made possible by a novel use of non-negative matrix factorization for the audio modality. Our approach is founded on the multiple instance learning paradigm. Its effectiveness is established through experiments over a challenging dataset of music instrument performance videos. We also show encouraging visual object localization results.
Weakly Supervised Representation Learning for Unsynchronized Audio-Visual Events
Jul 09, 2018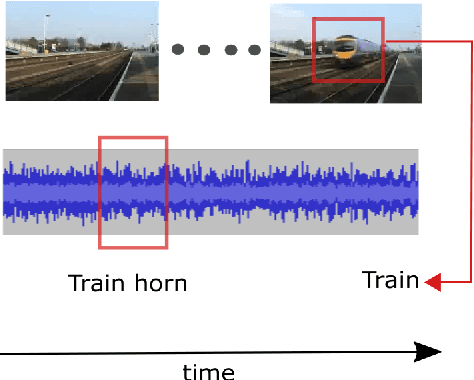
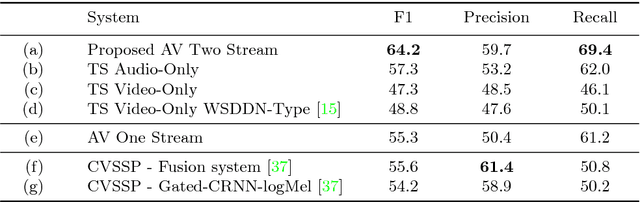
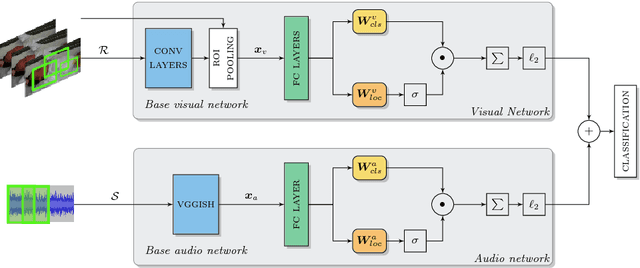
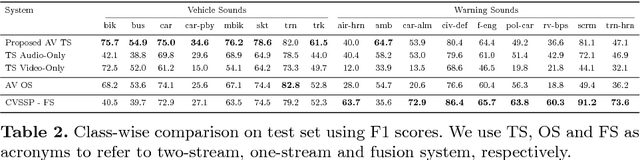
Audio-visual representation learning is an important task from the perspective of designing machines with the ability to understand complex events. To this end, we propose a novel multimodal framework that instantiates multiple instance learning. We show that the learnt representations are useful for classifying events and localizing their characteristic audio-visual elements. The system is trained using only video-level event labels without any timing information. An important feature of our method is its capacity to learn from unsynchronized audio-visual events. We achieve state-of-the-art results on a large-scale dataset of weakly-labeled audio event videos. Visualizations of localized visual regions and audio segments substantiate our system's efficacy, especially when dealing with noisy situations where modality-specific cues appear asynchronously.