 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization at the Edge of Stability
Apr 21, 2026Training modern neural networks often relies on large learning rates, operating at the edge of stability, where the optimization dynamics exhibit oscillatory and chaotic behavior. Empirically, this regime often yields improved generalization performance, yet the underlying mechanism remains poorly understood. In this work, we represent stochastic optimizers as random dynamical systems, which often converge to a fractal attractor set (rather than a point) with a smaller intrinsic dimension. Building on this connection and inspired by Lyapunov dimension theory, we introduce a novel notion of dimension, coined the `sharpness dimension', and prove a generalization bound based on this dimension. Our results show that generalization in the chaotic regime depends on the complete Hessian spectrum and the structure of its partial determinants, highlighting a complexity that cannot be captured by the trace or spectral norm considered in prior work. Experiments across various MLPs and transformers validate our theory while also providing new insights into the recently observed phenomenon of grokking.
Rényi Differential Privacy for Heavy-Tailed SDEs via Fractional Poincaré Inequalities
Nov 19, 2025Characterizing the differential privacy (DP) of learning algorithms has become a major challenge in recent years. In parallel, many studies suggested investigating the behavior of stochastic gradient descent (SGD) with heavy-tailed noise, both as a model for modern deep learning models and to improve their performance. However, most DP bounds focus on light-tailed noise, where satisfactory guarantees have been obtained but the proposed techniques do not directly extend to the heavy-tailed setting. Recently, the first DP guarantees for heavy-tailed SGD were obtained. These results provide $(0,δ)$-DP guarantees without requiring gradient clipping. Despite casting new light on the link between DP and heavy-tailed algorithms, these results have a strong dependence on the number of parameters and cannot be extended to other DP notions like the well-established Rényi differential privacy (RDP). In this work, we propose to address these limitations by deriving the first RDP guarantees for heavy-tailed SDEs, as well as their discretized counterparts. Our framework is based on new Rényi flow computations and the use of well-established fractional Poincaré inequalities. Under the assumption that such inequalities are satisfied, we obtain DP guarantees that have a much weaker dependence on the dimension compared to prior art.
On the Interaction of Compressibility and Adversarial Robustness
Jul 23, 2025Modern neural networks are expected to simultaneously satisfy a host of desirable properties: accurate fitting to training data, generalization to unseen inputs, parameter and computational efficiency, and robustness to adversarial perturbations. While compressibility and robustness have each been studied extensively, a unified understanding of their interaction still remains elusive. In this work, we develop a principled framework to analyze how different forms of compressibility - such as neuron-level sparsity and spectral compressibility - affect adversarial robustness. We show that these forms of compression can induce a small number of highly sensitive directions in the representation space, which adversaries can exploit to construct effective perturbations. Our analysis yields a simple yet instructive robustness bound, revealing how neuron and spectral compressibility impact $L_\infty$ and $L_2$ robustness via their effects on the learned representations. Crucially, the vulnerabilities we identify arise irrespective of how compression is achieved - whether via regularization, architectural bias, or implicit learning dynamics. Through empirical evaluations across synthetic and realistic tasks, we confirm our theoretical predictions, and further demonstrate that these vulnerabilities persist under adversarial training and transfer learning, and contribute to the emergence of universal adversarial perturbations. Our findings show a fundamental tension between structured compressibility and robustness, and suggest new pathways for designing models that are both efficient and secure.
Mutual Information Free Topological Generalization Bounds via Stability
Jul 09, 2025Providing generalization guarantees for stochastic optimization algorithms is a major challenge in modern learning theory. Recently, several studies highlighted the impact of the geometry of training trajectories on the generalization error, both theoretically and empirically. Among these works, a series of topological generalization bounds have been proposed, relating the generalization error to notions of topological complexity that stem from topological data analysis (TDA). Despite their empirical success, these bounds rely on intricate information-theoretic (IT) terms that can be bounded in specific cases but remain intractable for practical algorithms (such as ADAM), potentially reducing the relevance of the derived bounds. In this paper, we seek to formulate comprehensive and interpretable topological generalization bounds free of intractable mutual information terms. To this end, we introduce a novel learning theoretic framework that departs from the existing strategies via proof techniques rooted in algorithmic stability. By extending an existing notion of \textit{hypothesis set stability}, to \textit{trajectory stability}, we prove that the generalization error of trajectory-stable algorithms can be upper bounded in terms of (i) TDA quantities describing the complexity of the trajectory of the optimizer in the parameter space, and (ii) the trajectory stability parameter of the algorithm. Through a series of experimental evaluations, we demonstrate that the TDA terms in the bound are of great importance, especially as the number of training samples grows. This ultimately forms an explanation of the empirical success of the topological generalization bounds.
Topological Generalization Bounds for Discrete-Time Stochastic Optimization Algorithms
Jul 11, 2024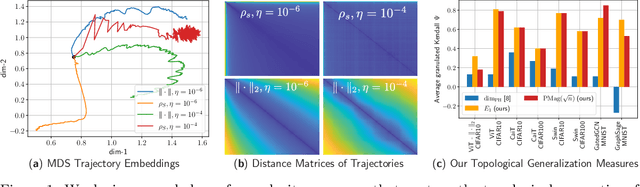
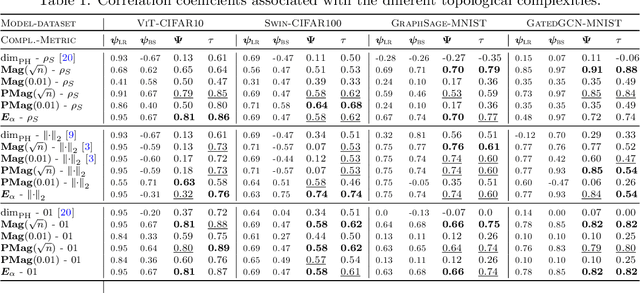

We present a novel set of rigorous and computationally efficient topology-based complexity notions that exhibit a strong correlation with the generalization gap in modern deep neural networks (DNNs). DNNs show remarkable generalization properties, yet the source of these capabilities remains elusive, defying the established statistical learning theory. Recent studies have revealed that properties of training trajectories can be indicative of generalization. Building on this insight, state-of-the-art methods have leveraged the topology of these trajectories, particularly their fractal dimension, to quantify generalization. Most existing works compute this quantity by assuming continuous- or infinite-time training dynamics, complicating the development of practical estimators capable of accurately predicting generalization without access to test data. In this paper, we respect the discrete-time nature of training trajectories and investigate the underlying topological quantities that can be amenable to topological data analysis tools. This leads to a new family of reliable topological complexity measures that provably bound the generalization error, eliminating the need for restrictive geometric assumptions. These measures are computationally friendly, enabling us to propose simple yet effective algorithms for computing generalization indices. Moreover, our flexible framework can be extended to different domains, tasks, and architectures. Our experimental results demonstrate that our new complexity measures correlate highly with generalization error in industry-standards architectures such as transformers and deep graph networks. Our approach consistently outperforms existing topological bounds across a wide range of datasets, models, and optimizers, highlighting the practical relevance and effectiveness of our complexity measures.
Differential Privacy of Noisy GD under Heavy-Tailed Perturbations
Mar 04, 2024Injecting heavy-tailed noise to the iterates of stochastic gradient descent (SGD) has received increasing attention over the past few years. While various theoretical properties of the resulting algorithm have been analyzed mainly from learning theory and optimization perspectives, their privacy preservation properties have not yet been established. Aiming to bridge this gap, we provide differential privacy (DP) guarantees for noisy SGD, when the injected noise follows an $\alpha$-stable distribution, which includes a spectrum of heavy-tailed distributions (with infinite variance) as well as the Gaussian distribution. Considering the $(\epsilon, \delta)$-DP framework, we show that SGD with heavy-tailed perturbations achieves $(0, \tilde{\mathcal{O}}(1/n))$-DP for a broad class of loss functions which can be non-convex, where $n$ is the number of data points. As a remarkable byproduct, contrary to prior work that necessitates bounded sensitivity for the gradients or clipping the iterates, our theory reveals that under mild assumptions, such a projection step is not actually necessary. We illustrate that the heavy-tailed noising mechanism achieves similar DP guarantees compared to the Gaussian case, which suggests that it can be a viable alternative to its light-tailed counterparts.
Generalization Bounds for Heavy-Tailed SDEs through the Fractional Fokker-Planck Equation
Feb 12, 2024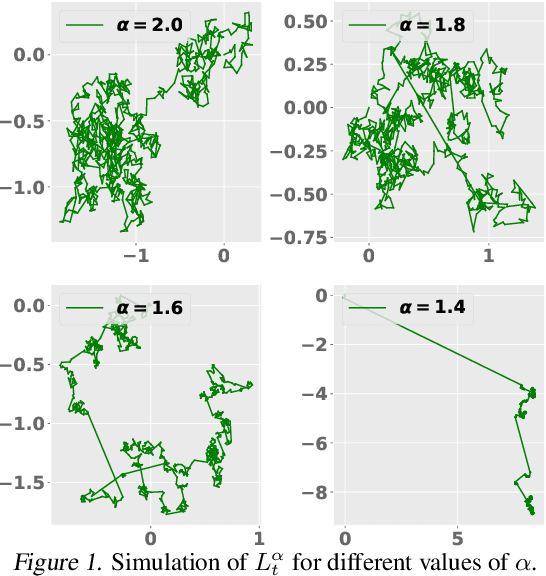
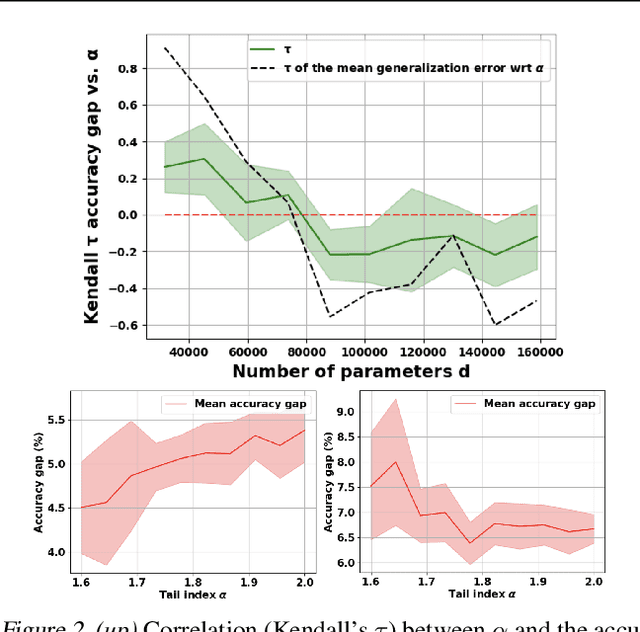
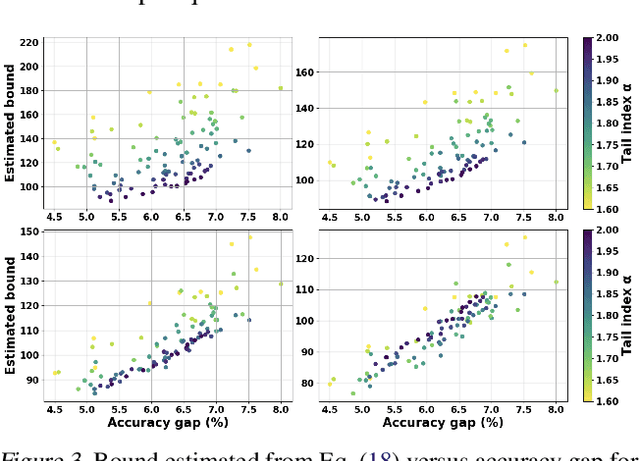
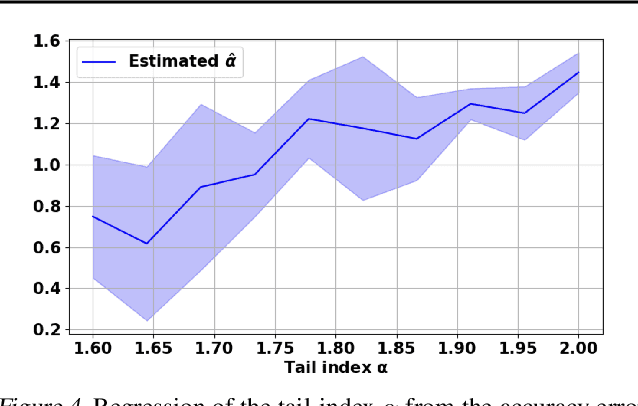
Understanding the generalization properties of heavy-tailed stochastic optimization algorithms has attracted increasing attention over the past years. While illuminating interesting aspects of stochastic optimizers by using heavy-tailed stochastic differential equations as proxies, prior works either provided expected generalization bounds, or introduced non-computable information theoretic terms. Addressing these drawbacks, in this work, we prove high-probability generalization bounds for heavy-tailed SDEs which do not contain any nontrivial information theoretic terms. To achieve this goal, we develop new proof techniques based on estimating the entropy flows associated with the so-called fractional Fokker-Planck equation (a partial differential equation that governs the evolution of the distribution of the corresponding heavy-tailed SDE). In addition to obtaining high-probability bounds, we show that our bounds have a better dependence on the dimension of parameters as compared to prior art. Our results further identify a phase transition phenomenon, which suggests that heavy tails can be either beneficial or harmful depending on the problem structure. We support our theory with experiments conducted in a variety of settings.
Tighter Generalisation Bounds via Interpolation
Feb 07, 2024



This paper contains a recipe for deriving new PAC-Bayes generalisation bounds based on the $(f, \Gamma)$-divergence, and, in addition, presents PAC-Bayes generalisation bounds where we interpolate between a series of probability divergences (including but not limited to KL, Wasserstein, and total variation), making the best out of many worlds depending on the posterior distributions properties. We explore the tightness of these bounds and connect them to earlier results from statistical learning, which are specific cases. We also instantiate our bounds as training objectives, yielding non-trivial guarantees and practical performances.
Efficient Sampling of Stochastic Differential Equations with Positive Semi-Definite Models
Mar 30, 2023This paper deals with the problem of efficient sampling from a stochastic differential equation, given the drift function and the diffusion matrix. The proposed approach leverages a recent model for probabilities \citep{rudi2021psd} (the positive semi-definite -- PSD model) from which it is possible to obtain independent and identically distributed (i.i.d.) samples at precision $\varepsilon$ with a cost that is $m^2 d \log(1/\varepsilon)$ where $m$ is the dimension of the model, $d$ the dimension of the space. The proposed approach consists in: first, computing the PSD model that satisfies the Fokker-Planck equation (or its fractional variant) associated with the SDE, up to error $\varepsilon$, and then sampling from the resulting PSD model. Assuming some regularity of the Fokker-Planck solution (i.e. $\beta$-times differentiability plus some geometric condition on its zeros) We obtain an algorithm that: (a) in the preparatory phase obtains a PSD model with L2 distance $\varepsilon$ from the solution of the equation, with a model of dimension $m = \varepsilon^{-(d+1)/(\beta-2s)} (\log(1/\varepsilon))^{d+1}$ where $0<s\leq1$ is the fractional power to the Laplacian, and total computational complexity of $O(m^{3.5} \log(1/\varepsilon))$ and then (b) for Fokker-Planck equation, it is able to produce i.i.d.\ samples with error $\varepsilon$ in Wasserstein-1 distance, with a cost that is $O(d \varepsilon^{-2(d+1)/\beta-2} \log(1/\varepsilon)^{2d+3})$ per sample. This means that, if the probability associated with the SDE is somewhat regular, i.e. $\beta \geq 4d+2$, then the algorithm requires $O(\varepsilon^{-0.88} \log(1/\varepsilon)^{4.5d})$ in the preparatory phase, and $O(\varepsilon^{-1/2}\log(1/\varepsilon)^{2d+2})$ for each sample. Our results suggest that as the true solution gets smoother, we can circumvent the curse of dimensionality without requiring any sort of convexity.
Cyclic and Randomized Stepsizes Invoke Heavier Tails in SGD
Feb 10, 2023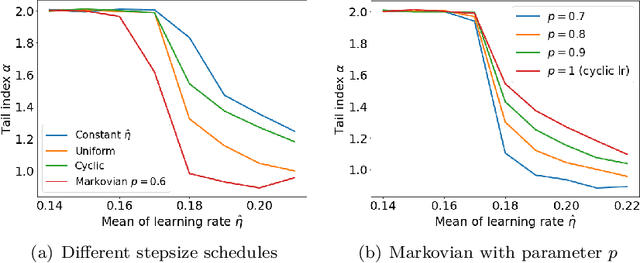
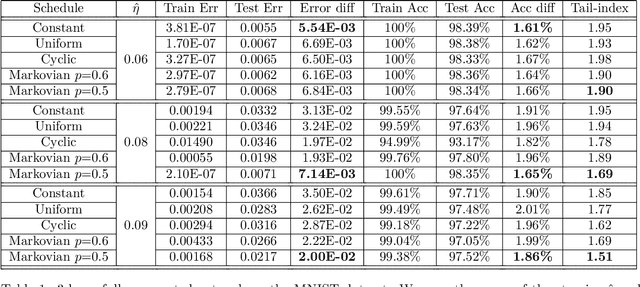
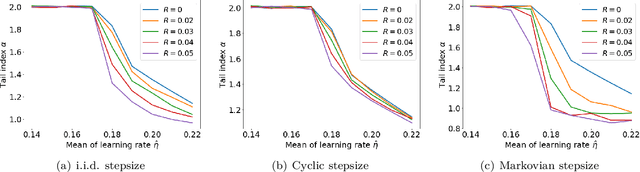
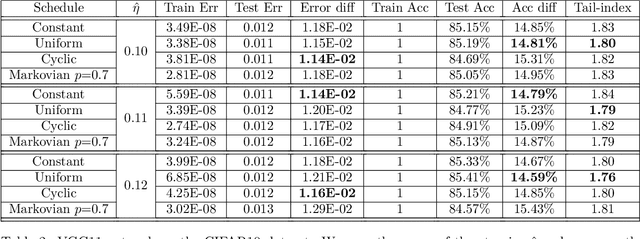
Cyclic and randomized stepsizes are widely used in the deep learning practice and can often outperform standard stepsize choices such as constant stepsize in SGD. Despite their empirical success, not much is currently known about when and why they can theoretically improve the generalization performance. We consider a general class of Markovian stepsizes for learning, which contain i.i.d. random stepsize, cyclic stepsize as well as the constant stepsize as special cases, and motivated by the literature which shows that heaviness of the tails (measured by the so-called "tail-index") in the SGD iterates is correlated with generalization, we study tail-index and provide a number of theoretical results that demonstrate how the tail-index varies on the stepsize scheduling. Our results bring a new understanding of the benefits of cyclic and randomized stepsizes compared to constant stepsize in terms of the tail behavior. We illustrate our theory on linear regression experiments and show through deep learning experiments that Markovian stepsizes can achieve even a heavier tail and be a viable alternative to cyclic and i.i.d. randomized stepsize rules.