 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic Smoothing for Adaptive PAC-Bayesian Off-Policy Learning
Jun 12, 2025Off-policy learning serves as the primary framework for learning optimal policies from logged interactions collected under a static behavior policy. In this work, we investigate the more practical and flexible setting of adaptive off-policy learning, where policies are iteratively refined and re-deployed to collect higher-quality data. Building on the success of PAC-Bayesian learning with Logarithmic Smoothing (LS) in static settings, we extend this framework to the adaptive scenario using tools from online PAC-Bayesian theory. Furthermore, we demonstrate that a principled adjustment to the LS estimator naturally accommodates multiple rounds of deployment and yields faster convergence rates under mild conditions. Our method matches the performance of leading offline approaches in static settings, and significantly outperforms them when intermediate policy deployments are allowed. Empirical evaluations across diverse scenarios highlight both the advantages of adaptive data collection and the strength of the PAC-Bayesian formulation.
Algorithm- and Data-Dependent Generalization Bounds for Score-Based Generative Models
Jun 04, 2025



Score-based generative models (SGMs) have emerged as one of the most popular classes of generative models. A substantial body of work now exists on the analysis of SGMs, focusing either on discretization aspects or on their statistical performance. In the latter case, bounds have been derived, under various metrics, between the true data distribution and the distribution induced by the SGM, often demonstrating polynomial convergence rates with respect to the number of training samples. However, these approaches adopt a largely approximation theory viewpoint, which tends to be overly pessimistic and relatively coarse. In particular, they fail to fully explain the empirical success of SGMs or capture the role of the optimization algorithm used in practice to train the score network. To support this observation, we first present simple experiments illustrating the concrete impact of optimization hyperparameters on the generalization ability of the generated distribution. Then, this paper aims to bridge this theoretical gap by providing the first algorithmic- and data-dependent generalization analysis for SGMs. In particular, we establish bounds that explicitly account for the optimization dynamics of the learning algorithm, offering new insights into the generalization behavior of SGMs. Our theoretical findings are supported by empirical results on several datasets.
Understanding the Generalization Error of Markov algorithms through Poissonization
Feb 11, 2025Using continuous-time stochastic differential equation (SDE) proxies to stochastic optimization algorithms has proven fruitful for understanding their generalization abilities. A significant part of these approaches are based on the so-called ``entropy flows'', which greatly simplify the generalization analysis. Unfortunately, such well-structured entropy flows cannot be obtained for most discrete-time algorithms, and the existing SDE approaches remain limited to specific noise and algorithmic structures. We aim to alleviate this issue by introducing a generic framework for analyzing the generalization error of Markov algorithms through `Poissonization', a continuous-time approximation of discrete-time processes with formal approximation guarantees. Through this approach, we first develop a novel entropy flow, which directly leads to PAC-Bayesian generalization bounds. We then draw novel links to modified versions of the celebrated logarithmic Sobolev inequalities (LSI), identify cases where such LSIs are satisfied, and obtain improved bounds. Beyond its generality, our framework allows exploiting specific properties of learning algorithms. In particular, we incorporate the noise structure of different algorithm types - namely, those with additional noise injections (noisy) and those without (non-noisy) - through various technical tools. This illustrates the capacity of our methods to achieve known (yet, Poissonized) and new generalization bounds.
A PAC-Bayesian Link Between Generalisation and Flat Minima
Feb 13, 2024
Modern machine learning usually involves predictors in the overparametrised setting (number of trained parameters greater than dataset size), and their training yield not only good performances on training data, but also good generalisation capacity. This phenomenon challenges many theoretical results, and remains an open problem. To reach a better understanding, we provide novel generalisation bounds involving gradient terms. To do so, we combine the PAC-Bayes toolbox with Poincar\'e and Log-Sobolev inequalities, avoiding an explicit dependency on dimension of the predictor space. Our results highlight the positive influence of \emph{flat minima} (being minima with a neighbourhood nearly minimising the learning problem as well) on generalisation performances, involving directly the benefits of the optimisation phase.
Tighter Generalisation Bounds via Interpolation
Feb 07, 2024



This paper contains a recipe for deriving new PAC-Bayes generalisation bounds based on the $(f, \Gamma)$-divergence, and, in addition, presents PAC-Bayes generalisation bounds where we interpolate between a series of probability divergences (including but not limited to KL, Wasserstein, and total variation), making the best out of many worlds depending on the posterior distributions properties. We explore the tightness of these bounds and connect them to earlier results from statistical learning, which are specific cases. We also instantiate our bounds as training objectives, yielding non-trivial guarantees and practical performances.
Federated Learning with Nonvacuous Generalisation Bounds
Oct 17, 2023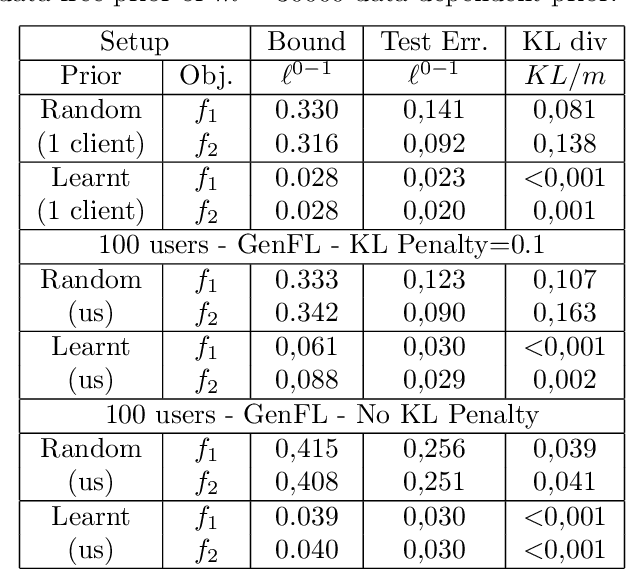
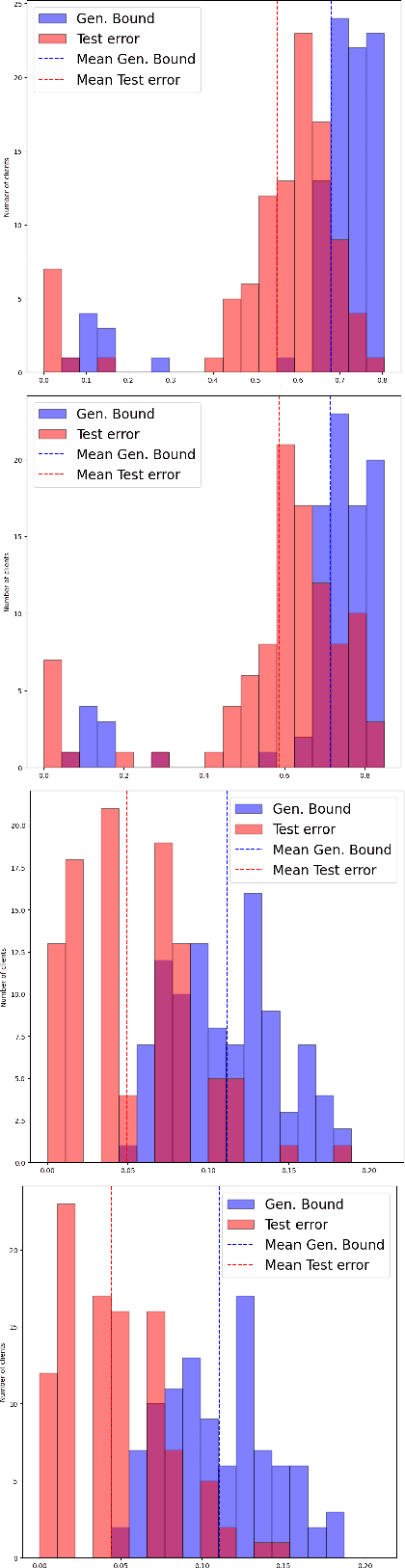
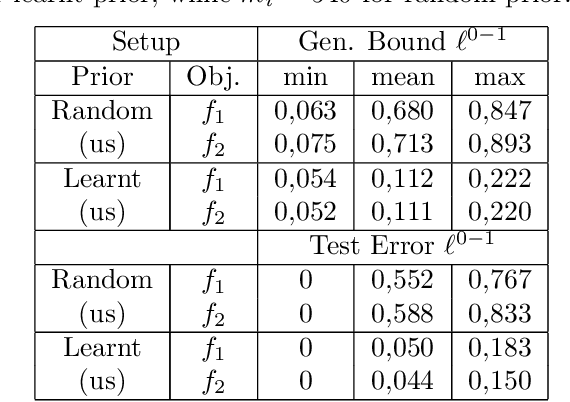
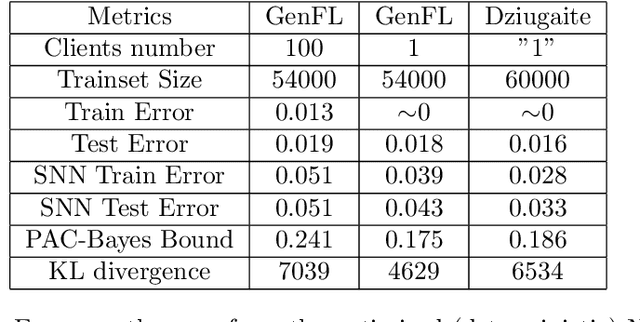
We introduce a novel strategy to train randomised predictors in federated learning, where each node of the network aims at preserving its privacy by releasing a local predictor but keeping secret its training dataset with respect to the other nodes. We then build a global randomised predictor which inherits the properties of the local private predictors in the sense of a PAC-Bayesian generalisation bound. We consider the synchronous case where all nodes share the same training objective (derived from a generalisation bound), and the asynchronous case where each node may have its own personalised training objective. We show through a series of numerical experiments that our approach achieves a comparable predictive performance to that of the batch approach where all datasets are shared across nodes. Moreover the predictors are supported by numerically nonvacuous generalisation bounds while preserving privacy for each node. We explicitly compute the increment on predictive performance and generalisation bounds between batch and federated settings, highlighting the price to pay to preserve privacy.
Learning via Wasserstein-Based High Probability Generalisation Bounds
Jun 07, 2023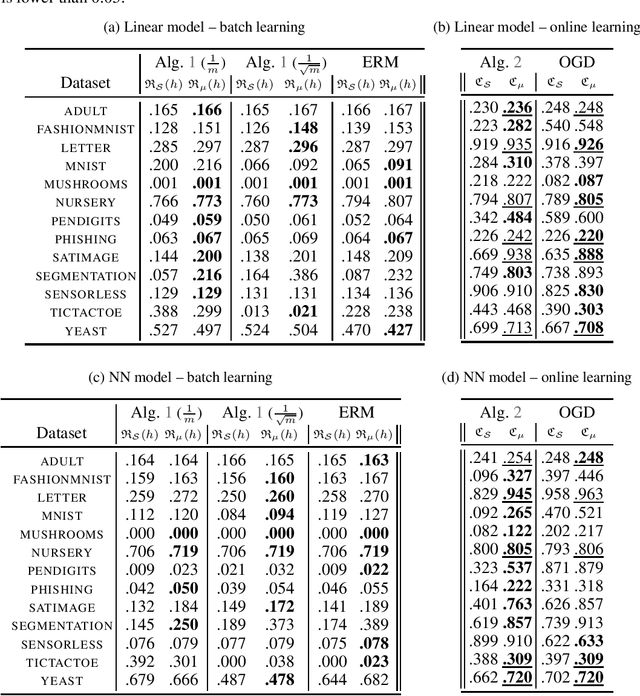
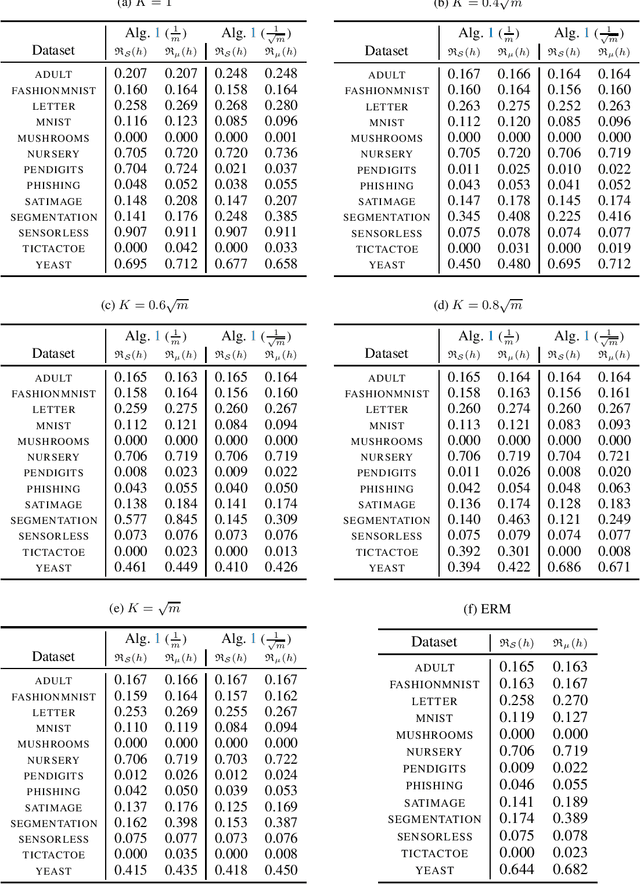
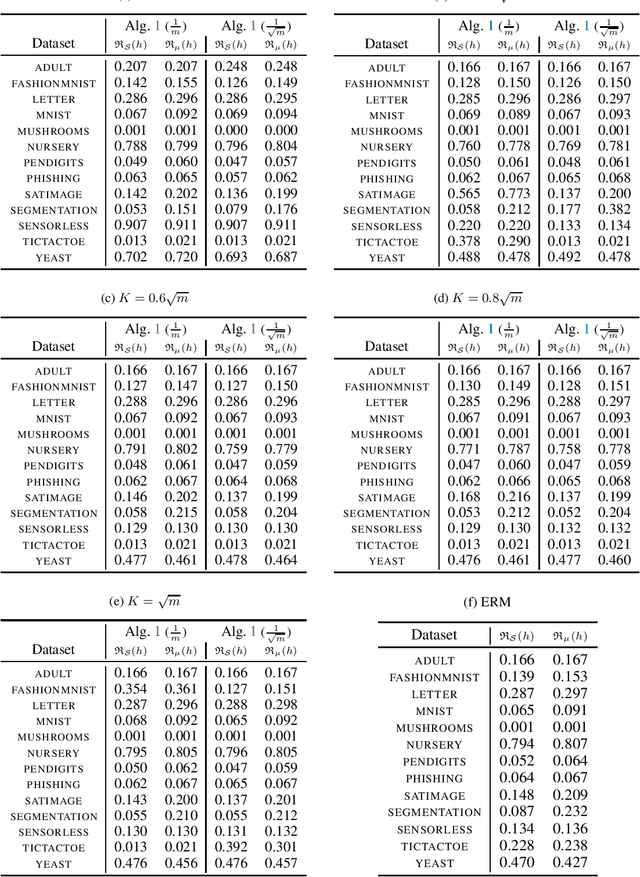
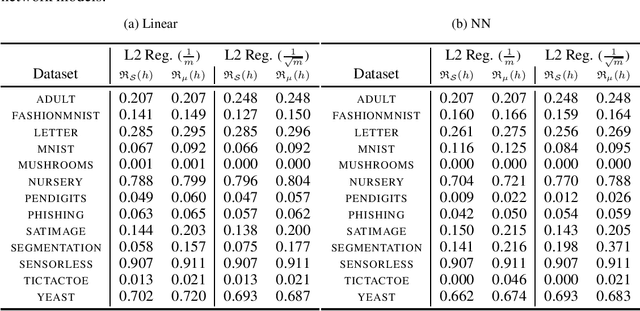
Minimising upper bounds on the population risk or the generalisation gap has been widely used in structural risk minimisation (SRM) - this is in particular at the core of PAC-Bayesian learning. Despite its successes and unfailing surge of interest in recent years, a limitation of the PAC-Bayesian framework is that most bounds involve a Kullback-Leibler (KL) divergence term (or its variations), which might exhibit erratic behavior and fail to capture the underlying geometric structure of the learning problem - hence restricting its use in practical applications. As a remedy, recent studies have attempted to replace the KL divergence in the PAC-Bayesian bounds with the Wasserstein distance. Even though these bounds alleviated the aforementioned issues to a certain extent, they either hold in expectation, are for bounded losses, or are nontrivial to minimize in an SRM framework. In this work, we contribute to this line of research and prove novel Wasserstein distance-based PAC-Bayesian generalisation bounds for both batch learning with independent and identically distributed (i.i.d.) data, and online learning with potentially non-i.i.d. data. Contrary to previous art, our bounds are stronger in the sense that (i) they hold with high probability, (ii) they apply to unbounded (potentially heavy-tailed) losses, and (iii) they lead to optimizable training objectives that can be used in SRM. As a result we derive novel Wasserstein-based PAC-Bayesian learning algorithms and we illustrate their empirical advantage on a variety of experiments.
Wasserstein PAC-Bayes Learning: A Bridge Between Generalisation and Optimisation
Apr 14, 2023PAC-Bayes learning is an established framework to assess the generalisation ability of learning algorithm during the training phase. However, it remains challenging to know whether PAC-Bayes is useful to understand, before training, why the output of well-known algorithms generalise well. We positively answer this question by expanding the \emph{Wasserstein PAC-Bayes} framework, briefly introduced in \cite{amit2022ipm}. We provide new generalisation bounds exploiting geometric assumptions on the loss function. Using our framework, we prove, before any training, that the output of an algorithm from \citet{lambert2022variational} has a strong asymptotic generalisation ability. More precisely, we show that it is possible to incorporate optimisation results within a generalisation framework, building a bridge between PAC-Bayes and optimisation algorithms.
Optimistic Dynamic Regret Bounds
Jan 18, 2023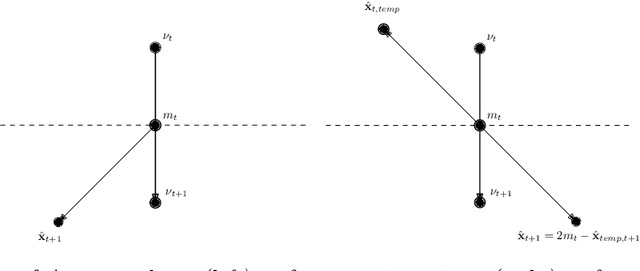
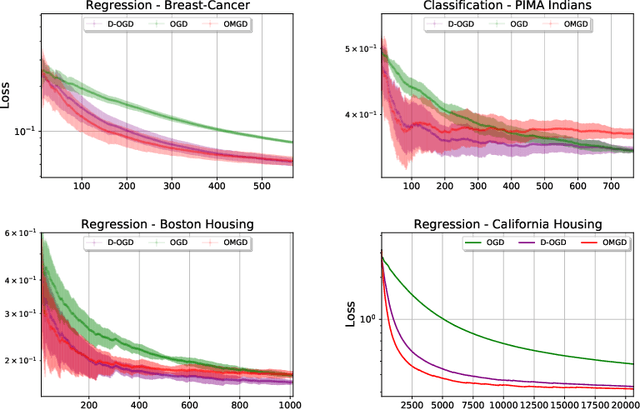
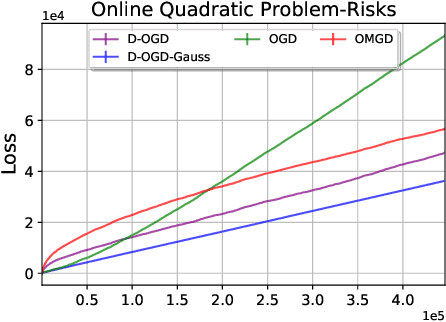
Online Learning (OL) algorithms have originally been developed to guarantee good performances when comparing their output to the best fixed strategy. The question of performance with respect to dynamic strategies remains an active research topic. We develop in this work dynamic adaptations of classical OL algorithms based on the use of experts' advice and the notion of optimism. We also propose a constructivist method to generate those advices and eventually provide both theoretical and experimental guarantees for our procedures.
PAC-Bayes with Unbounded Losses through Supermartingales
Oct 03, 2022While PAC-Bayes is now an established learning framework for bounded losses, its extension to the case of unbounded losses (as simple as the squared loss on an unbounded space) remains largely uncharted and has attracted a growing interest in recent years. We contribute to this line of work by developing an extention of Markov's inequality for supermartingales, which we use to establish a novel PAC-Bayesian generalisation bound holding for unbounded losses. We show that this bound extends, unifies and even improves on existing PAC-Bayesian bounds.