 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models and the Manifold Hypothesis: Log-Domain Smoothing is Geometry Adaptive
Oct 02, 2025



Diffusion models have achieved state-of-the-art performance, demonstrating remarkable generalisation capabilities across diverse domains. However, the mechanisms underpinning these strong capabilities remain only partially understood. A leading conjecture, based on the manifold hypothesis, attributes this success to their ability to adapt to low-dimensional geometric structure within the data. This work provides evidence for this conjecture, focusing on how such phenomena could result from the formulation of the learning problem through score matching. We inspect the role of implicit regularisation by investigating the effect of smoothing minimisers of the empirical score matching objective. Our theoretical and empirical results confirm that smoothing the score function -- or equivalently, smoothing in the log-density domain -- produces smoothing tangential to the data manifold. In addition, we show that the manifold along which the diffusion model generalises can be controlled by choosing an appropriate smoothing.
Rao-Blackwellised Reparameterisation Gradients
Jun 09, 2025

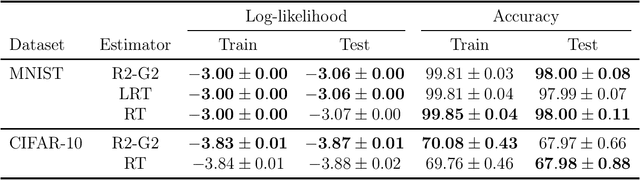

Latent Gaussian variables have been popularised in probabilistic machine learning. In turn, gradient estimators are the machinery that facilitates gradient-based optimisation for models with latent Gaussian variables. The reparameterisation trick is often used as the default estimator as it is simple to implement and yields low-variance gradients for variational inference. In this work, we propose the R2-G2 estimator as the Rao-Blackwellisation of the reparameterisation gradient estimator. Interestingly, we show that the local reparameterisation gradient estimator for Bayesian MLPs is an instance of the R2-G2 estimator and Rao-Blackwellisation. This lets us extend benefits of Rao-Blackwellised gradients to a suite of probabilistic models. We show that initial training with R2-G2 consistently yields better performance in models with multiple applications of the reparameterisation trick.
Adaptive Diffusion Guidance via Stochastic Optimal Control
May 25, 2025Guidance is a cornerstone of modern diffusion models, playing a pivotal role in conditional generation and enhancing the quality of unconditional samples. However, current approaches to guidance scheduling--determining the appropriate guidance weight--are largely heuristic and lack a solid theoretical foundation. This work addresses these limitations on two fronts. First, we provide a theoretical formalization that precisely characterizes the relationship between guidance strength and classifier confidence. Second, building on this insight, we introduce a stochastic optimal control framework that casts guidance scheduling as an adaptive optimization problem. In this formulation, guidance strength is not fixed but dynamically selected based on time, the current sample, and the conditioning class, either independently or in combination. By solving the resulting control problem, we establish a principled foundation for more effective guidance in diffusion models.
Conditioning Diffusions Using Malliavin Calculus
Apr 04, 2025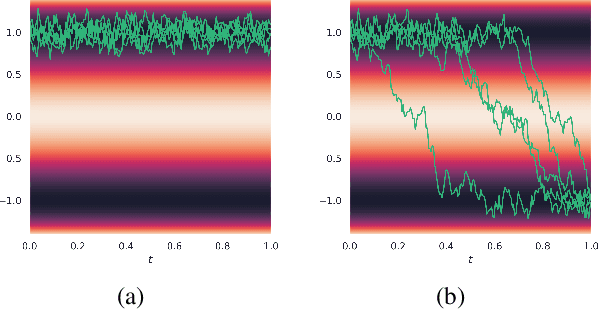



In stochastic optimal control and conditional generative modelling, a central computational task is to modify a reference diffusion process to maximise a given terminal-time reward. Most existing methods require this reward to be differentiable, using gradients to steer the diffusion towards favourable outcomes. However, in many practical settings, like diffusion bridges, the reward is singular, taking an infinite value if the target is hit and zero otherwise. We introduce a novel framework, based on Malliavin calculus and path-space integration by parts, that enables the development of methods robust to such singular rewards. This allows our approach to handle a broad range of applications, including classification, diffusion bridges, and conditioning without the need for artificial observational noise. We demonstrate that our approach offers stable and reliable training, outperforming existing techniques.
Understanding the Generalization Error of Markov algorithms through Poissonization
Feb 11, 2025Using continuous-time stochastic differential equation (SDE) proxies to stochastic optimization algorithms has proven fruitful for understanding their generalization abilities. A significant part of these approaches are based on the so-called ``entropy flows'', which greatly simplify the generalization analysis. Unfortunately, such well-structured entropy flows cannot be obtained for most discrete-time algorithms, and the existing SDE approaches remain limited to specific noise and algorithmic structures. We aim to alleviate this issue by introducing a generic framework for analyzing the generalization error of Markov algorithms through `Poissonization', a continuous-time approximation of discrete-time processes with formal approximation guarantees. Through this approach, we first develop a novel entropy flow, which directly leads to PAC-Bayesian generalization bounds. We then draw novel links to modified versions of the celebrated logarithmic Sobolev inequalities (LSI), identify cases where such LSIs are satisfied, and obtain improved bounds. Beyond its generality, our framework allows exploiting specific properties of learning algorithms. In particular, we incorporate the noise structure of different algorithm types - namely, those with additional noise injections (noisy) and those without (non-noisy) - through various technical tools. This illustrates the capacity of our methods to achieve known (yet, Poissonized) and new generalization bounds.
Linear Convergence of Diffusion Models Under the Manifold Hypothesis
Oct 11, 2024Score-matching generative models have proven successful at sampling from complex high-dimensional data distributions. In many applications, this distribution is believed to concentrate on a much lower $d$-dimensional manifold embedded into $D$-dimensional space; this is known as the manifold hypothesis. The current best-known convergence guarantees are either linear in $D$ or polynomial (superlinear) in $d$. The latter exploits a novel integration scheme for the backward SDE. We take the best of both worlds and show that the number of steps diffusion models require in order to converge in Kullback-Leibler~(KL) divergence is linear (up to logarithmic terms) in the intrinsic dimension $d$. Moreover, we show that this linear dependency is sharp.
Convergence of Diffusion Models Under the Manifold Hypothesis in High-Dimensions
Sep 27, 2024Denoising Diffusion Probabilistic Models (DDPM) are powerful state-of-the-art methods used to generate synthetic data from high-dimensional data distributions and are widely used for image, audio and video generation as well as many more applications in science and beyond. The manifold hypothesis states that high-dimensional data often lie on lower-dimensional manifolds within the ambient space, and is widely believed to hold in provided examples. While recent results has provided invaluable insight into how diffusion models adapt to the manifold hypothesis, they do not capture the great empirical success of these models, making this a very fruitful research direction. In this work, we study DDPMs under the manifold hypothesis and prove that they achieve rates independent of the ambient dimension in terms of learning the score. In terms of sampling, we obtain rates independent of the ambient dimension w.r.t. the Kullback-Leibler divergence, and $O(\sqrt{D})$ w.r.t. the Wasserstein distance. We do this by developing a new framework connecting diffusion models to the well-studied theory of extrema of Gaussian Processes.
Differentiable Cost-Parameterized Monge Map Estimators
Jun 12, 2024



Within the field of optimal transport (OT), the choice of ground cost is crucial to ensuring that the optimality of a transport map corresponds to usefulness in real-world applications. It is therefore desirable to use known information to tailor cost functions and hence learn OT maps which are adapted to the problem at hand. By considering a class of neural ground costs whose Monge maps have a known form, we construct a differentiable Monge map estimator which can be optimized to be consistent with known information about an OT map. In doing so, we simultaneously learn both an OT map estimator and a corresponding adapted cost function. Through suitable choices of loss function, our method provides a general approach for incorporating prior information about the Monge map itself when learning adapted OT maps and cost functions.
Uniform Generalization Bounds on Data-Dependent Hypothesis Sets via PAC-Bayesian Theory on Random Sets
Apr 26, 2024



We propose data-dependent uniform generalization bounds by approaching the problem from a PAC-Bayesian perspective. We first apply the PAC-Bayesian framework on `random sets' in a rigorous way, where the training algorithm is assumed to output a data-dependent hypothesis set after observing the training data. This approach allows us to prove data-dependent bounds, which can be applicable in numerous contexts. To highlight the power of our approach, we consider two main applications. First, we propose a PAC-Bayesian formulation of the recently developed fractal-dimension-based generalization bounds. The derived results are shown to be tighter and they unify the existing results around one simple proof technique. Second, we prove uniform bounds over the trajectories of continuous Langevin dynamics and stochastic gradient Langevin dynamics. These results provide novel information about the generalization properties of noisy algorithms.
Particle Denoising Diffusion Sampler
Feb 09, 2024



Denoising diffusion models have become ubiquitous for generative modeling. The core idea is to transport the data distribution to a Gaussian by using a diffusion. Approximate samples from the data distribution are then obtained by estimating the time-reversal of this diffusion using score matching ideas. We follow here a similar strategy to sample from unnormalized probability densities and compute their normalizing constants. However, the time-reversed diffusion is here simulated by using an original iterative particle scheme relying on a novel score matching loss. Contrary to standard denoising diffusion models, the resulting Particle Denoising Diffusion Sampler (PDDS) provides asymptotically consistent estimates under mild assumptions. We demonstrate PDDS on multimodal and high dimensional sampling tasks.